Spark-RDD之Partition源码分析
概要
Spark RDD主要由Dependency、Partition、Partitioner组成,Partition是其中之一。一份待处理的原始数据会被按照相应的逻辑(例如jdbc和hdfs的split逻辑)切分成n份,每份数据对应到RDD中的一个Partition,Partition的数量决定了task的数量,影响着程序的并行度,所以理解Partition是了解spark背后运行原理的第一步。
Partition定义
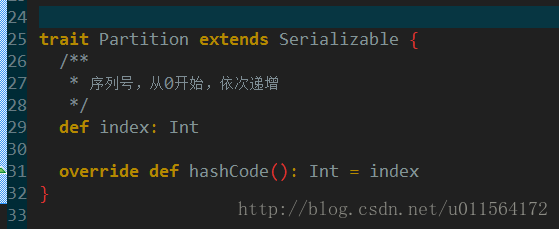
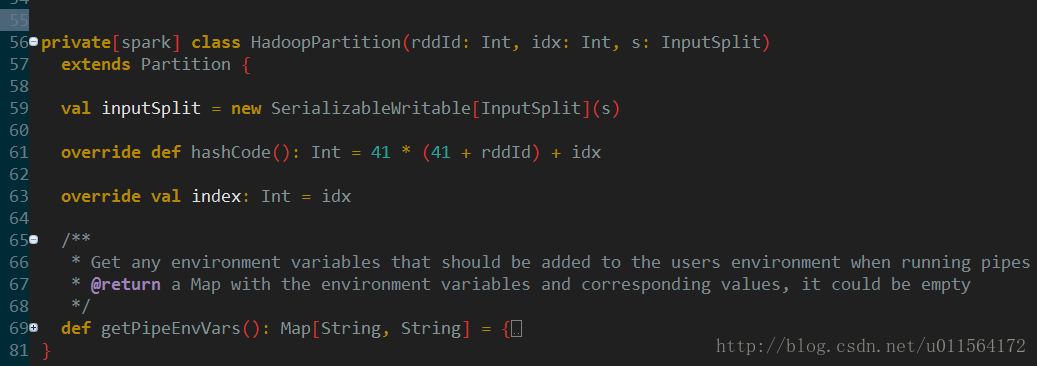
查看spark源码,trait Partition的定义很简单,序列号index和hashCode方法。Partition和RDD是伴生的,即每一种RDD都有其对应的Partition实现,所以,分析Partition主要是分析其子类。我们关注两个常用的子类,JdbcPartition和HadoopPartition。此外,RDD源码中有5个方法,代表其组成,如下:
第二个方法,getPartitions是数据源如何被切分的逻辑,返回值正是Partition,第一个方法compute是消费切割后的Partition的方法,所以学习Partition,要结合getPartitions和compute方法。
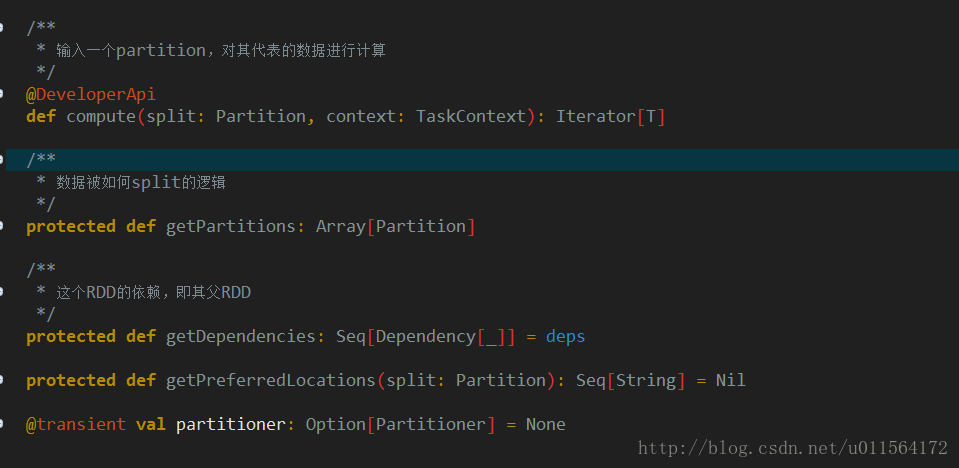
JdbcPartition例子
下面是Spark JdbcRDDSuite中一个例子
val sc = new SparkContext("local[1]", "test")
val rdd = new JdbcRDD(
sc,
() => { DriverManager.getConnection("jdbc:derby:target/JdbcRDDSuiteDb") },
// DATA类型为INTEGER
"SELECT DATA FROM FOO WHERE ? <= ID AND ID <= ?",
1, 100, 3,
(r: ResultSet) => { r.getInt(1) } ).count()
查看JdbcPartition实现,相比Partition,主要多了lower和upper这两个字段。
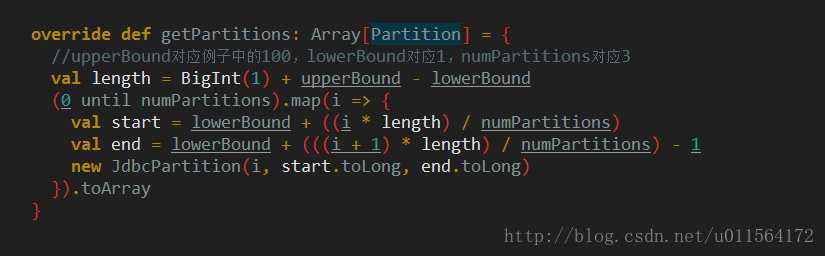
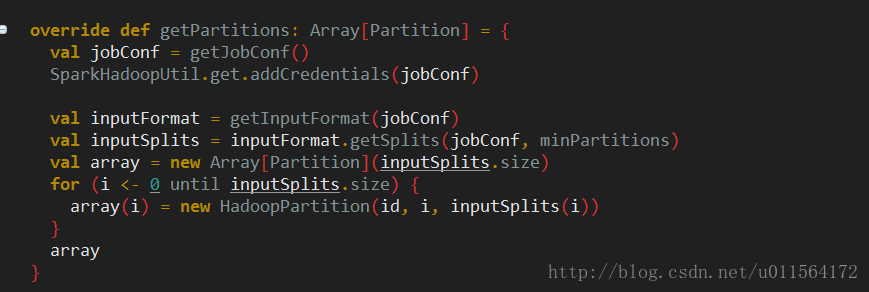
查看JdbcRDD的getPartitions,按照如上图所示算法将1到100分为3份(partition数量),结果为(1,33)、(34,66)、(67,100),封装为JdbcPartition并返回,这样数据切分的部分就完成了。
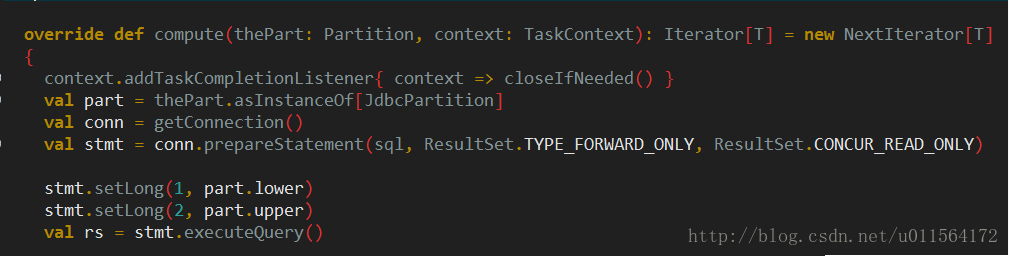
查看JdbcRDD的compute方法,逻辑清晰,将Partition强转为JdbcPartition,获取连接并预处理sql,将
例子中的”SELECT DATA FROM FOO WHERE ? <= ID AND ID <= ?”问号分别用Partition的lower和upper替换(即getPartitions切分好的(1,33)、(34,66)、(67,100))并执行查询。至此,JdbcPartition如何发挥作用就分析完了。HadoopPartition例子
举个简单例子val sc = new SparkContext("local[1]", "test")
sc.textFile("hdfs://your-file-path").count()- 1
- 2
相比Partition,HadoopPartition则多了InputSplit。
spark切分hdfs文件,调用的是Hadoop的API,对这块不熟的同学查看上面InputSplit的链接。
执行计算的逻辑也很简单,将Partition强转为HadoopPartition,HadoopPartition内有InputSplit对象。调用Hadoop API三个读取数据的相关对象,InputSplit、InputFormat和Reader,读取对应split的数据。这块需要你对Hadoop的掌握,另外我在下面会讲Hadoop split的策略。


决定partition数量的因素
Partition数量可以在初始化RDD时指定(如JdbcPartition例子),不指定的话(如HadoopPartition例子),则
读取spark.default.parallelism配置,不同类型资源管理器取值不同,如下
了解了默认的partition数量,再看一些具体API的partition行为

- RDD初始化相关
| Spark API | partition数量 |
| sc.parallelize(…) | sc.defaultParallelism |
| sc.textFile(…) | max(传参, block数) |
| val hbaseRDD = sc.newAPIHadoopRDD(…) | max(传参, block数) |
| val jdbcRDD = new JdbcRDD(…) | 传参 |
- 通用transformation
| filter(),map(),flatMap(),distinct() | 和父RDD相同 |
| rdd.union(otherRDD) | rdd.partitions.size + otherRDD. partitions.size |
| rdd.intersection(otherRDD) | max(rdd.partitions.size, otherRDD. partitions.size) |
| rdd.subtract(otherRDD) | rdd.partitions.size |
| rdd.cartesian(otherRDD) | rdd.partitions.size * otherRDD. partitions.size |
- Key-based Transformations
| reduceByKey(),foldByKey(),combineByKey(), groupByKey() | 和父RDD相同 |
| sortByKey() | 同上 |
| mapValues(),flatMapValues() | 同上 |
| cogroup(), join(), ,leftOuterJoin(), rightOuterJoin() | 所有父RDD按照其partition数降序排列,从partition数最大的RDD开始查找是否存在partitioner,存在则partition数由此partitioner确定,否则,所有RDD不存在partitioner,由spark.default.parallelism确定,若还没设置,最后partition数为所有RDD中partition数的最大值 |
上面的Partition行为我们从中挑一个细分析,就是sc.textFile(…, numPartitions)读取hdfs时的Partition数,上表给出的答案是numPartitions和block数较大者,如果不指定numPartitions,则numPartitions<=2, 分析这个问题,其实跟spark无关,要查看Hadoop源码FileInputFormat类中getSplits方法
指定numPartitions
totalSize为待处理文件总大小,numSplits就是我们所指定的numPartitions,得到了平均的文件大小goalSize,接下来
比较计算得到的goalSize和block大小blockSize,取其中较小者,再和minSize(由属性mapreduce.input.fileinputformat.split.minsize确定,默认值为0,则minSize默认值为1)取较大的。
假设待处理文件大小fSize=512M(视为一个大文件,不考虑1.1系数),block大小bSize=128M,sc.textFile(…, 3)
根据上面的公式goalSize=512M/3 > bSize=128M
取其较小者bSize,则按照bSize切分,split数=512M/128=4,即partition数=4sc.textFile(…, 5)
根据上面的公式goalSize=512M/5 < bSize=128M
取其较小者goalSize,则按照goalSize切分,split数=512M/(512M/5)=5,即partition数=5
可见指定numPartitions,小于block数时无效,大于则生效。
不指定numPartitions
默认,传给FileInputFormat类getSplits方法的numSplits值是sc.defaultParallelism和2的较小值,所以spark.default.parallelism几乎是没用的,Partition数就是block数。那么为什么是这样的呢,感兴趣的同学看下这个讨论



Partition数量影响及调整
上面分析了决定Partition数量的因数,接下来就该考虑Partition数量的影响以及合适的值。
Partition数量的影响
- Partition数量太少
太少的影响显而易见,就是资源不能充分利用,例如local模式下,有16core,但是Partition数量仅为8的话,有一半的core没利用到。 - Partition数量太多
太多,资源利用没什么问题,但是导致task过多,task的序列化和传输的时间开销增大。
那么多少的partition数是合适的呢,这里我们参考spark doc给出的建议,Typically you want 2-4 partitions for each CPU in your cluster。
- Partition数量太少
- Partition调整
- repartition
reparation是coalesce(numPartitions, shuffle = true),repartition不仅会调整Partition数,也会将Partitioner修改为hashPartitioner,产生shuffle操作。 - coalesce
coalesce函数可以控制是否shuffle,但当shuffle为false时,只能减小Partition数,无法增大。
- repartition
总结
Partition对应的是不同数据源的split逻辑,首先以JdbcPartition和HadoopPartition为例,介绍了Partition的组成,以及如何发挥作用,接下来分析了常见API的Partition行为,最后简单介绍了Partition数量的影响及调整。
参考:
https://techmagie.wordpress.com/2015/12/19/understanding-spark-partitioning/
https://jaceklaskowski.gitbooks.io/mastering-apache-spark/content/spark-rdd-partitions.html
https://spark.apache.org/docs/latest/tuning.html
https://www.mapr.com/developercentral/code/loading-hbase-tables-spark
注:图片中代码均为Spark、Hadoop源码,我稍作处理,如去掉log、metric等,使逻辑更清晰。
Spark-RDD之Partition源码分析的更多相关文章
- spark的存储系统--BlockManager源码分析
spark的存储系统--BlockManager源码分析 根据之前的一系列分析,我们对spark作业从创建到调度分发,到执行,最后结果回传driver的过程有了一个大概的了解.但是在分析源码的过程中也 ...
- Spark MLlib - Decision Tree源码分析
http://spark.apache.org/docs/latest/mllib-decision-tree.html 以决策树作为开始,因为简单,而且也比较容易用到,当前的boosting或ran ...
- spark(1.1) mllib 源码分析(一)-卡方检验
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/4019131.html 在spark mllib 1.1版本中增加stat包,里面包含了一些统计相关的函数 ...
- 【Spark篇】---Spark中资源和任务调度源码分析与资源配置参数应用
一.前述 Spark中资源调度是一个非常核心的模块,尤其对于我们提交参数来说,需要具体到某些配置,所以提交配置的参数于源码一一对应,掌握此节对于Spark在任务执行过程中的资源分配会更上一层楼.由于源 ...
- spark(1.1) mllib 源码分析(二)-相关系数
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/4024733.html 在spark mllib 1.1版本中增加stat包,里面包含了一些统计相关的函数 ...
- spark(1.1) mllib 源码分析(三)-朴素贝叶斯
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/4042467.html 本文主要以mllib 1.1版本为基础,分析朴素贝叶斯的基本原理与源码 一.基本原 ...
- Spark 1.6.1 源码分析
由于gitbook网速不好,所以复制自https://zx150842.gitbooks.io/spark-1-6-1-source-code/content/,非原创,纯属搬运工,若作者要求,可删除 ...
- spark(1.1) mllib 源码分析(三)-决策树
本文主要以mllib 1.1版本为基础,分析决策树的基本原理与源码 一.基本原理 二.源码分析 1.决策树构造 指定决策树训练数据集与策略(Strategy)通过train函数就能得到决策树模型Dec ...
- 66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一.数据处理原理剖析 每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval ...
随机推荐
- Zuul介绍
1. Zuul是什么 Zuul是所有从设备和web站点到Netflix流媒体应用程序后端请求的前门.作为一个边缘服务应用程序,Zuul被构建来支持动态路由.监视.弹性和安全性.它还可以根据需要将请求 ...
- 在阿里云 ECS 搭建 nginx https nodejs 环境 (一、 nginx)
首先介绍下相关环境.软件的版本 1.阿里云 ECS . ubuntu-14.04.5 LTS 2.nginx 版本 1.9.2 可能会遇到的问题: 一.在 ssh 服务器上的时候,提示 这个时候需要将 ...
- #12 Python函数
前言 矩形的面积 S = ab,只要知道任一矩形的的长和宽,就可以带入上式求得面积.这样有什么好处呢?一个公式,适用于全部矩形,一个公式,重复利用,减少了大脑的记忆负担.像这类用变量代替不变量的思想在 ...
- .Net语言 APP开发平台——Smobiler学习日志:如何快速实现手机上的资源上传功能
最前面的话:Smobiler是一个在VS环境中使用.Net语言来开发APP的开发平台,也许比Xamarin更方便 一.目标样式 我们要实现上图中的效果,需要如下的操作: 1.从工具栏上的“Smobil ...
- 解决ajax跨域问题
JQuery ajax支持get方式的跨域,采用了jsonp来完成.完成跨域请求的有两种方式实现.一种是使用Jquery ajax最底层的Api实现跨域的请求,而另一种则是JQuery ajax的高级 ...
- C# 操作Excel图形——绘制、读取、隐藏、删除图形
简介 本篇文章将介绍C# 如何处理Excel图形相关的问题,包括以下内容要点: 1.绘制图形 1.1 绘制图形并添加文本到图形 1.2 添加图片到图形 1.3 设置图形阴影效果 1.4 设置图形透明度 ...
- 使用Canvas绘制简单的时钟控件
Canvas是HTML5新增的组件,它就像一块幕布,可以用JavaScript在上面绘制各种图表.动画等. 没有Canvas的年代,绘图只能借助Flash插件实现,页面不得不用JavaScript和F ...
- iOS-----------计算两个时间的时间差
UIButton * nameButton = [UIButton buttonWithType:UIButtonTypeCustom]; nameButton.frame = CGRectMake( ...
- (办公)SpringBoot与mybatisGenerator自动生成.
20181206-自动生成,少写一点代码. (以下的内容主要参考csdn上的<[完美]SpringBoot+Mybatis-Generator自动生成>这篇文章,还有简书上的mbatis- ...
- Go-Ethereum 1.7.2 结合 Mist 0.9.2 实现众筹合约的实例
目录 目录 1.什么是ICO? 2.众筹的奖励-代币 3.众筹合约的完善 3.1.设置众筹合约中使用的代币 3.2.众筹合约的基本设置 3.3.让众筹合约接收以太币 3.4.检测众筹合约是否完成 3. ...