java 解析富文本处理 img 标签
很多项目都需要到富文本来添加内容,就好比新闻啊,旅游景点之类的,都需要使用富文本去添加数据,然而怎么我这边就发现了两个问题
1)怎样将富文本的图片的 src 获取出来?
2)后台上传的时候用的是相对路径,前端显示需要的是最对路径
我下面就记录一下解决这两个问题的方法
1):怎么将富文本的图片的 src 获取出来?很简单,就一个工具即可
public static List<String> getImgStr(String htmlStr) {
List<String> list = new ArrayList<>();
String img = "";
Pattern p_image;
Matcher m_image;
// String regEx_img = "<img.*src=(.*?)[^>]*?>"; //图片链接地址
String regEx_img = "<img.*src\\s*=\\s*(.*?)[^>]*?>";
p_image = Pattern.compile(regEx_img, Pattern.CASE_INSENSITIVE);
m_image = p_image.matcher(htmlStr);
while (m_image.find()) {
// 得到<img />数据
img = m_image.group();
// 匹配<img>中的src数据
Matcher m = Pattern.compile("src\\s*=\\s*\"?(.*?)(\"|>|\\s+)").matcher(img);
while (m.find()) {
list.add(m.group(1));
}
}
return list;
}
即可获取到以下结果

2)后台上传的时候用的是相对路径,前端显示需要的是最对路径,下面来看看我们怎么动态去修改富文本的 img 标签的 src ,也很简单,也是一个工具即可
这里需要一个叫做 jsoup 的 jar, maven 项目的话,直接引进来就行了
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.2</version>
</dependency>
下面是工具类
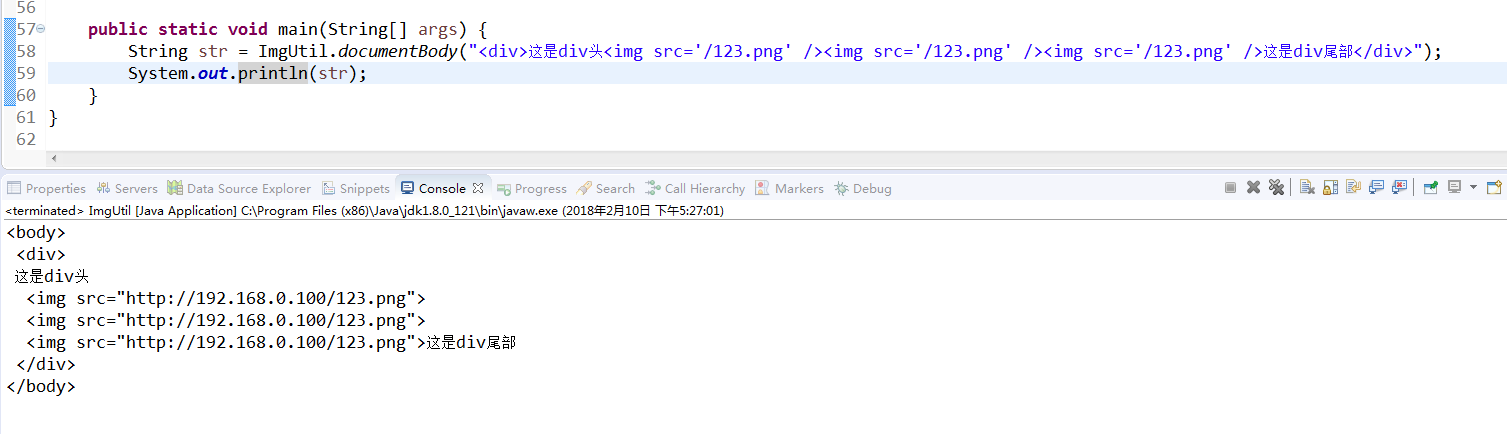
public static String documentBody (String newsBody) {
Element doc = Jsoup.parseBodyFragment(newsBody).body();
Elements pngs = doc.select("img[src]");
String httpHost = "http://192.168.0.100";
for (Element element : pngs) {
String imgUrl = element.attr("src");
if (imgUrl.trim().startsWith("/")) { // 会去匹配我们富文本的图片的 src 的相对路径的首个字符,请注意一下
imgUrl =httpHost + imgUrl;
element.attr("src", imgUrl);
}
}
return newsBody = doc.toString();
}
即可获取到以下结果
好了,以上就是这两个问题的解决方式
不喜勿喷!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
java 解析富文本处理 img 标签的更多相关文章
- 从文本中提取图片路径(java 解析富文本处理 img 标签)
很多项目都需要到富文本来添加内容,就好比新闻啊,旅游景点之类的,都需要使用富文本去添加数据,然而怎么我这边就发现了两个问题 怎样将富文本的图片的 src 获取出来? 方法一: 利用正则表达式: pub ...
- wxParse解析富文本内容使点击图片可以选中并实现放大缩小
wxParse解析富文本内容不多说,之前写过步骤介绍,主要是在使用过程中发现解析的富文本内容里有图片时有的可以点击放大缩小,有的点击却报错,找不到imgUrls. 经过排查发现:循环解析的富文本内容正 ...
- springmvc 后台实体类接受前端json字符串时,其中一个属性content 接受富文本内容时 标签<p>、<span> 这些标签丢失问题解决
问题描述: 前端一个字段 <script id="editor" type="text/plain" name="content" s ...
- php读取富文本处理html标签问题
thinkphp的一项配置会将富文本编辑器的内容中的html标签进行转义处理 'DEFAULT_FILTER' => 'htmlspecialchars', // 默认参数过滤方法使用htmls ...
- php 解析富文本编辑器中的hmtl内容,富文本样式正确输出
说明:富文本编辑器中的内容在直接获获取后需要解析以后才能在页面中正确显示 我在后端这样处理: $content = htmlspecialchars_decode($info['intro']); h ...
- 微信小程序/支付宝小程序 WxParse解析富文本(html)代码
小程序本身并不太支持html代码,比如html的img.span.p这个时候改这么办呢?需要用到一个小插件WxParse来实现. 小程序高级交流群:336925436 微信小程序支持富文本编辑器代码 ...
- selenium+java解决富文本输入
方法一: Actions actions = new Actions(driver); actions.sendKeys(Keys.TAB).perform(); //鼠标通过tab要先移到富文本框中 ...
- Selenium+java - 关于富文本编辑器的处理
什么是富文本编辑器? 富文本编辑器,Rich Text Editor, 简称 RTE, 是一种可内嵌于浏览器,所见即所得的文本编辑器.具体长啥样,如下图: 通过自动化操作富文本编辑器 模拟场景:在富文 ...
- 小程序里面使用wxParse解析富文本导致页面空白等
在部分安卓手机上会出现白屏的情况且有些ios手机上图文混排上,图片显示不出问题 解决:把插件里面的console.dir去掉即可(原因在于安卓手机无法解析console.dir) 有些图片解析出来下面 ...
随机推荐
- Java基础 -- final关键字
在java的关键字中,static和final是两个我们必须掌握的关键字.不同于其他关键字,他们都有多种用法,而且在一定环境下使用,可以提高程序的运行性能,优化程序的结构.下面我们来了解一下final ...
- Vue过滤器
局部定义: var vm = new Vue({ el:"#app", data:{ proData:'' }, filters: { pro_color(index){ swit ...
- usb描述符简述(二)
title: usb描述符简述 tags: linux date: 2018/12/18/ 18:25:23 toc: true --- usb描述符简述 转载自cnblog 具体描述符 https: ...
- 数据库学习之MySQL进阶
数据库进阶 一.视图 数据库视图是虚拟表或逻辑 ...
- 第二十节: 深入理解并发机制以及解决方案(锁机制、EF自有机制、队列模式等)
一. 理解并发机制 1. 什么是并发,并发与多线程有什么关系? ①. 先从广义上来说,或者从实际场景上来说. 高并发通常是海量用户同时访问(比如:12306买票.淘宝的双十一抢购),如果把一个用户看做 ...
- metasploit 教程之基本参数和扫描
前言 首先我也不知道我目前的水平适不适合学习msf. 在了解一些msf之后,反正就是挺想学的.就写博记录一下.如有错误的地方,欢迎各位大佬指正. 感激不尽.! 我理解的msf msf全程metaspl ...
- MySQL学习9 - 单表查询
一.单表查询的语法 二.关键字的执行优先级(重点) 三.单表查询示例 1.where约束 2.group by分组查询 3.聚合函数 4.HAVING过滤 5.order by查询排序 6.limit ...
- 支持动态调频_配置AXP228电源管理_4核8核兼容设计_iTOP-4418/6818开发板
iTOP-4418/6818开发板 支持动态调频,AXP228电源管理, 系统支持:Android4.4/5.1.1.Linux3.4.39.QT2.2/4.7/5.7.Ubuntu12.04 内存: ...
- 论文笔记:Cross-Domain Visual Matching via Generalized Similarity Measure and Feature Learning
Cross-Domain Visual Matching,即跨域视觉匹配.所谓跨域,指的是数据的分布不一样,简单点说,就是两种数据「看起来」不像.如下图中,(a)一般的正面照片和各种背景角度下拍摄的照 ...
- Spring Cloud Context模块
SpringCloud这个框架本身是建立在SpringBoot基础之上的,所以使用SpringCloud的方式与SpringBoot相仿.也是通过类似如下代码进行启动. SpringApplicati ...