2、CDH组件安装
一、zookeeper
1、安装
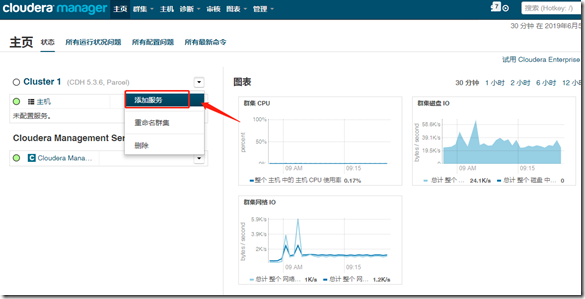
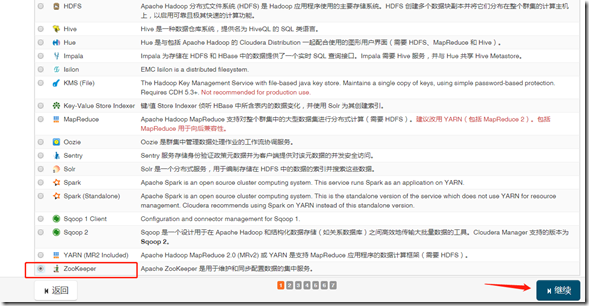
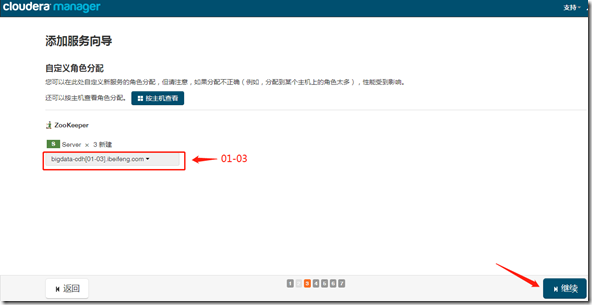
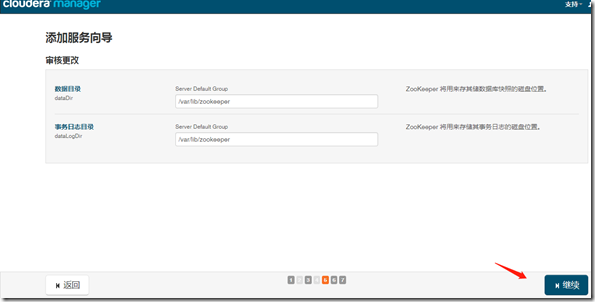
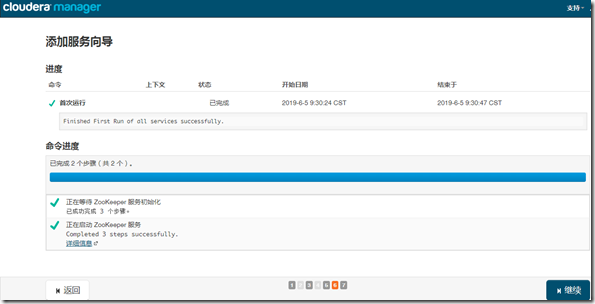
继续—>完成;
二、HDFS
1、安装

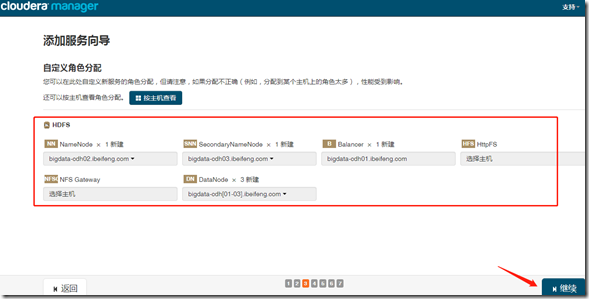
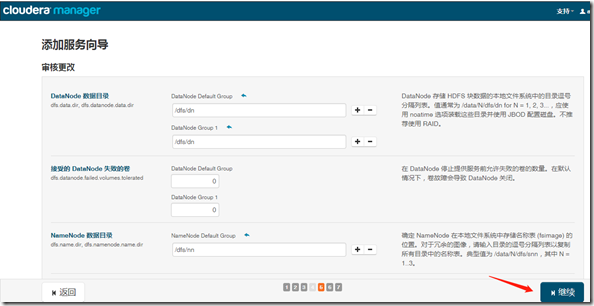
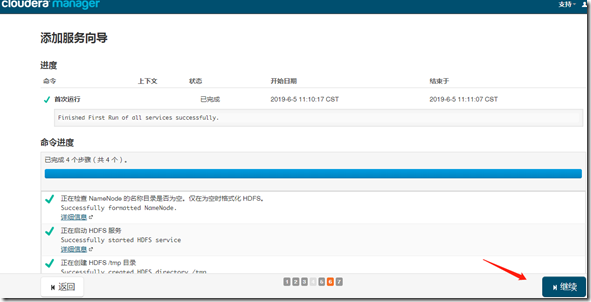
继续—>完成;
三、yarn、hive
1、安装yarn
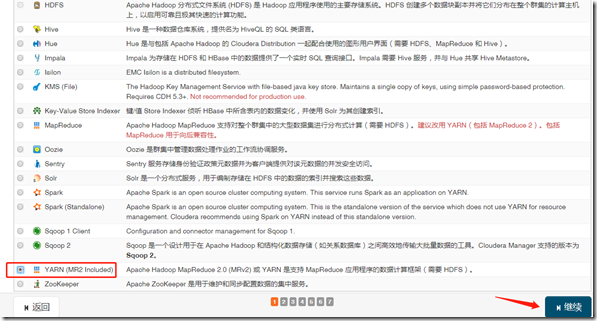
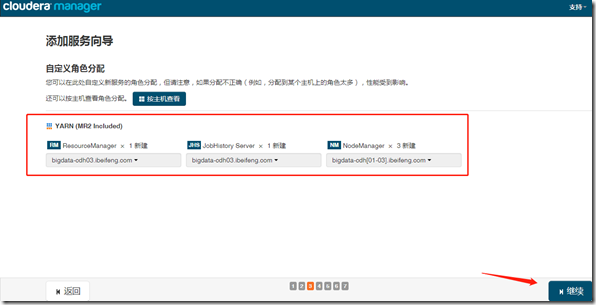
继续—>完成;
2、安装hive

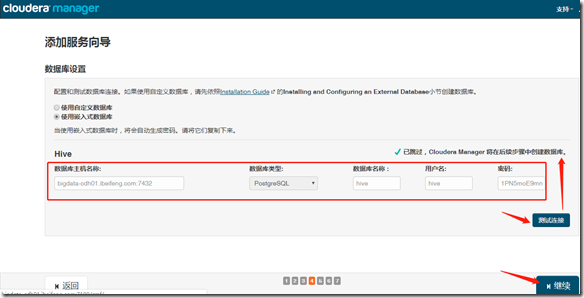
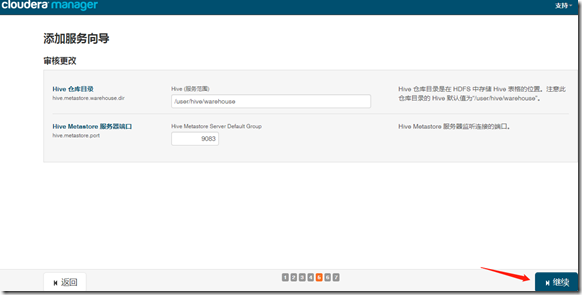
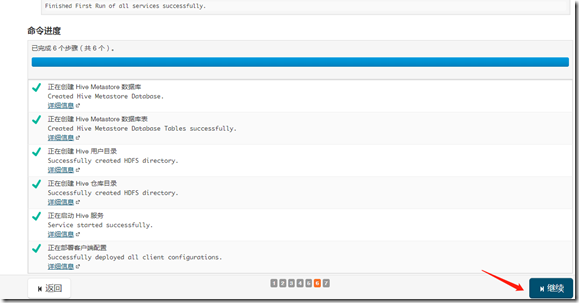
继续—>完成;
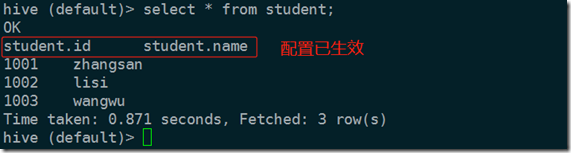
3、测试hive
hive> show tables;
OK
Time taken: 0.41 seconds hive> create table student(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
OK
Time taken: 0.168 seconds hive> show tables;
OK
student
Time taken: 0.019 seconds, Fetched: 1 row(s) hive> load data local inpath '/home/stu.txt' into table student;
Loading data to table default.student
Table default.student stats: [numFiles=1, numRows=0, totalSize=36, rawDataSize=0]
OK
Time taken: 0.471 seconds hive> select * from student;
OK
1001 zhangsan
1002 lisi
1003 wangwu ###hive on yarn
[root@bigdata-cdh03 ~]# su - hdfs hive
19/06/05 13:33:23 WARN conf.HiveConf: DEPRECATED: Configuration property hive.metastore.local no longer has any effect. Make sure to provide a valid value for hive.metastore.uris if you are connecting to a remote metastore. Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-5.3.6-1.cdh5.3.6.p0.11/jars/hive-common-0.13.1-cdh5.3.6.jar!/hive-log4j.properties
hive> select count(1) from student;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1559705875106_0001, Tracking URL = http://bigdata-cdh03.ibeifeng.com:8088/proxy/application_1559705875106_0001/
Kill Command = /opt/cloudera/parcels/CDH-5.3.6-1.cdh5.3.6.p0.11/lib/hadoop/bin/hadoop job -kill job_1559705875106_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-06-05 13:33:46,429 Stage-1 map = 0%, reduce = 0%
2019-06-05 13:33:51,610 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.86 sec
2019-06-05 13:33:57,788 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.16 sec
MapReduce Total cumulative CPU time: 2 seconds 160 msec
Ended Job = job_1559705875106_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.16 sec HDFS Read: 264 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 160 msec
OK
3
Time taken: 20.502 seconds, Fetched: 1 row(s)
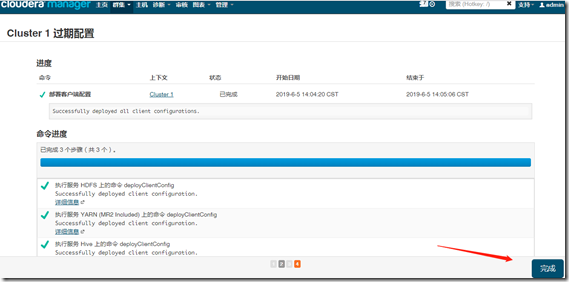
4、服务组件配置
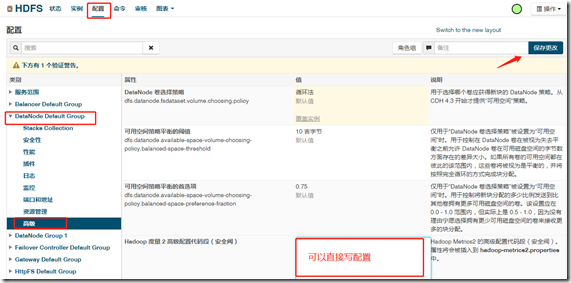
如,配置HDFS
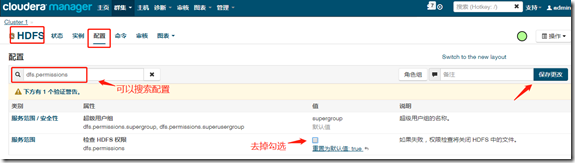
如,配置hive:
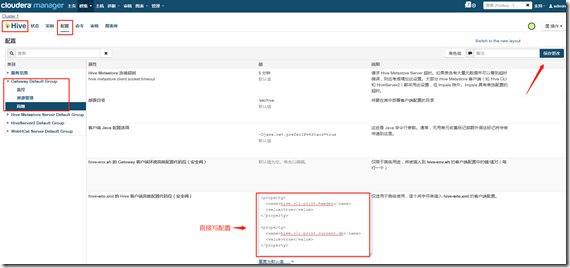
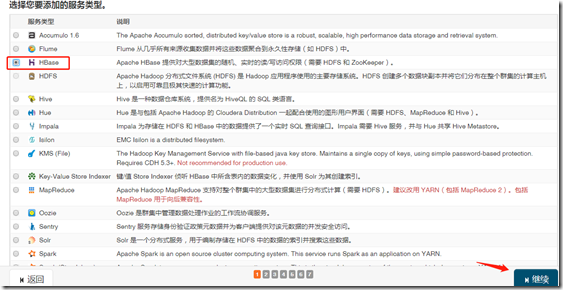
四、HBase
1、安装

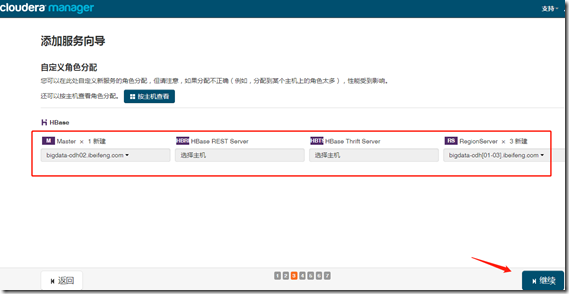
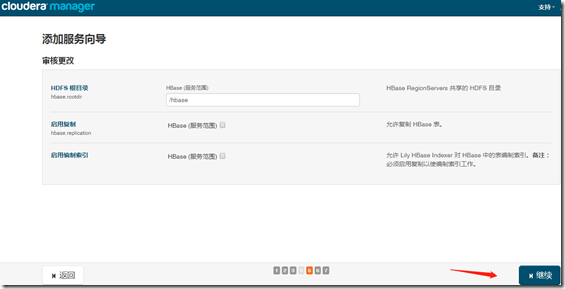
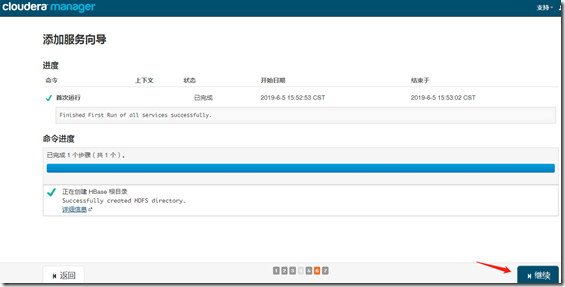
继续—>完成;
2、CDH组件安装的更多相关文章
- Coudera-Manager/CDH的安装和部署
由于之前部署的集群采用的是用apache hadoop的方式来实现,但是考虑到运维的成本问题,下面将apache hadoop转换成cloudera cdh.下面主要讲解一下cloudera cdh的 ...
- cdh 上安装spark on yarn
在cdh 上安装spark on yarn 还是比较简单的,不需要独立安装什么模块或者组件. 安装服务 选择on yarn 模式:上面 Spark 在spark 服务中添加 在yarn 服务中添加 g ...
- Microsoft Visual Studio Web 创作组件安装失败的解决方法
在网上查一下说是Office2007的问题.我把Office2007卸载了还是不行. 然后用Windows Install Clean Up工具清理,还是不行. 郁闷了.然后在安装包中的下面路径下找到 ...
- Gulp及组件安装构建
Gulp 是一款基于任务的设计模式的自动化工具,通过插件的配合解决全套前端解决方案,如静态页面压缩.图片压缩.JS合并.SASS同步编译并压缩CSS.服务器控制客户端同步刷新. Gulp安装 全局安装 ...
- Linux下的暴力密码在线破解工具Hydra安装及其组件安装-使用
Linux下的暴力密码在线破解工具Hydra安装及其组件安装-使用 hydra可以破解: http://www.thc.org/thc-hydra,可支持AFP, Cisco AAA, Cisco a ...
- delphi 组件安装教程详解
学习安装组件的最好方法,就是自己编写一个组件并安装一遍,然后就真正明白其中的原理了. 本例,编写了两个BPL, dclSimpleEdit.bpl 与 SimpleLabel.bpl ,其中,dc ...
- 云计算OpenStack:云计算介绍及组件安装(一)--技术流ken
云计算介绍 当用户能够通过互联网方便的获取到计算.存储等服务时,我们比喻自己使用到了“云计算”,云计算并不能被称为是一种计算技术,而更像是一种服务模式.每个运维人员心里都有一个对云计算的理解,而最普遍 ...
- OpenStack基础组件安装keystone身份认证服务
域名解析 vim /etc/hosts 192.168.245.172 controller01 192.168.245.171 controller02 192.168.245.173 contro ...
- 一、OpenStack环境准备及共享组件安装
一.OpenStack部署环境准备: 1.关闭防火墙所有虚拟机都要操作 # setenforce 0 # systemctl stop firewalld 2.域名解析所有虚拟机都要操作 # cat ...
随机推荐
- python 基础 5.2 类的继承
一. 类的继承 继承,顾名思议就知道是它的意思,举个例子说明,你现在有一个现有的A类,现在需要写一个B类,但是B类是A类的特殊版,我们就可以使用继承,B类继承A类时,B类会自动获得A类的所有属性和方法 ...
- 【BZOJ3992】[SDOI2015]序列统计 NTT+多项式快速幂
[BZOJ3992][SDOI2015]序列统计 Description 小C有一个集合S,里面的元素都是小于M的非负整数.他用程序编写了一个数列生成器,可以生成一个长度为N的数列,数列中的每个数都属 ...
- EasyDSS RTMP流媒体解决方案之Windows服务安装方案
Windows服务安装 EasyDSS_Solution流媒体解决方案,可以通过start一键启动.在实际应用中,我们希望可以设置成系统服务,那么下面我将会介绍,如何在windows中将流媒体解决方案 ...
- 在调用Response.End()时,会执行Thread.CurrentThread.Abort()操作
在调用Response.End()时,会执行Thread.CurrentThread.Abort()操作. 如果将Response.End()放在try...catch中,catch会捕捉Thread ...
- 远程访问(post 传参数) 以及IOUtils复制文件
package com.action; import java.io.File; import java.io.FileOutputStream; import java.io.InputStream ...
- 文件查找工具Everything小工具的使用
Everything 小工具的使用: 首先它是一款基于名称实时定位文件和目录的搜索工具,有以下几个优点: 快速文件索引 快速文件搜索 较低资源占用 轻松分享文件索引 实时跟踪文件更新 通过使用ever ...
- Git with SVN
1)GIT是分布式的,SVN不是: 这 是GIT和其它非分布式的版本控制系统,例如SVN,CVS等,最核心的区别.好处是跟其他同事不会有太多的冲突,自己写的代码放在自己电脑上,一段时间后再提交.合并, ...
- Hadoop实战-Flume之Sink Failover(十六)
a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 # Describe/configure the source a1.sources.r1.type ...
- postgres 备份数据库
https://www.postgresql.org/docs/9.1/static/app-pgdump.html bash-4.2$ pg_dump -Fc xianlan_prod > / ...
- win7下搭建nginx+php的开发环境(转)
在win7下用的是IIS做web服务器,但近来因项目需求的原因,需要在服务器遇到404错误的时候自动做转向(不是在客户端的跳转,而是在服务器收到客户端请求去某目录下读取文件返回时,如果发现目录或目录下 ...