基于nodejs将mongodb的数据实时同步到elasticsearch
一、前言
因公司需要选用elasticsearch做全文检索,持久化存储选用的是mongodb,但是希望mongodb里面的数据发生改变可以实时同步到elasticsearch上,一开始主要使用elasticsearch v1.7.2的版本,mongo-river可以搞定这个问题。随着elasticsearch的升级,发现elasticsearch已经放弃了mongo-river,咋整......Google之后发现一神器mongo-connector,国外大神用python写的工具而且MongoDB官网也极力推荐使用。But,我们需要把文档中的附件信息也同步到elasticsearch上,mongo-connector对附件同步支持的不是很好。能不能有个nodejs版本的数据同步?GitHub上发现一个大神写的node-elasticsearch-sync很好用,但是功能太简单了,不支持复杂的数据筛选,也不支持附件同步。活人不能被尿憋死,参考node-elasticsearch-sync自己写了一个同步工具node-mongodb-es-connector。
二、准备工作
2.1 安装mongodb
安装mongodb可以去官网下载:
PS:关于如何搭建mongodb replica集群:
https://www.cnblogs.com/ljhdo/p/4503317.html
2.2 安装elasticsearch
安装elasticsearch可以去官网下载:
https://www.elastic.co/cn/downloads
PS:关于elasticsearch-head、kibana、logstash等相关安装请自己google吧
2.3 安装nodejs
安装nodejs可以去官网下载:
PS:别忘记安装npm,如何安装请自己google吧
以上是使用node-mongodb-es-connector的前提
2.4 node-mongodb-es-connector下载地址
github: https://github.com/zhr85210078/node-mongodb-es-connector
npm: https://www.npmjs.com/package/es-mongodb-sync?activeTab=readme
三、文件结构
├── crawlerDataConfig 项目构建配置(这里添加你要同步数据的配置)
│ ├── mycarts.json 一个index一个配置文件(唯一需要自己增加或者修改的配置文件,这个文件只是提供了一个例子,不用可以删除)
│ └── ……
├── lib
│ ├── pool
│ │ ├── elasticsearchPool.js elasticsearch连接池
│ │ ├── mongoDBPool.js mongodb连接池
│ ├── promise
│ │ ├── elasticsearchPromise.js elasticsearch方法类(增删改查)
│ │ ├── mongoPromise.js mongodb方法类(增删改查)
│ ├── util
│ │ ├── fsWatcher.js 配置文件监控类(主要监控crawlerDataConfig目录里面的配置文件)
│ │ ├── logger.js 日志类
│ │ ├── oplogFactory.js mongo-oplog触发事件之后的执行方法(增删改)
│ │ ├── tail.js 监听mongodb数据是否发生变化
│ │ ├── util.js 工具类
│ ├── main.js 主方法(主要是第一次启动立刻同步mongodb里面的数据到elasticsearch)
├── logs
│ ├── logger-2018-03-23.log 同步数据打印日志
│ └── ……
├── test
│ ├── img
│ │ ├── elasticsearch.jpg 图片不解释
│ │ ├── mongoDB.jpg 图片不解释
│ │ └── structure.jpg 图片不解释
│ └── test.js 测试类(啥也没写)
├── app.js 启动文件
├── index.js 接口文件(只提供配置文件的增删改)
├── package-lock.json
├── package.json
├── ReadMe.md 英文文档(markdown)
├── README.zh-CN.md 中文文档(markdown)
└── LICENSE
mycarts.json文件(这个文件只是提供了一个例子)
{
"mongodb": {
"m_database": "myTest",
"m_collectionname": "carts",
"m_filterfilds": {
"version" : "2.0"
},
"m_returnfilds": {
"cName": 1,
"cPrice": 1,
"cImgSrc": 1
},
"m_connection": {
"m_servers": [
"localhost:29031",
"localhost:29032",
"localhost:29033"
],
"m_authentication": {
"username": "UserAdmin",
"password": "pass1234",
"authsource": "admin",
"replicaset": "my_replica",
"ssl":false
}
},
"m_documentsinbatch": 5000,
"m_delaytime": 1000
},
"elasticsearch": {
"e_index": "mycarts",
"e_type": "carts",
"e_connection": {
"e_server": "http://localhost:9200",
"e_httpauth": {
"username": "EsAdmin",
"password": "pass1234"
}
},
"e_pipeline": "mypipeline",
"e_iscontainattachment": true
}
}
- m_database - MongoDB里需要监听的数据库.
- m_collectionname - MongoDB里需要监听的collection.
- m_filterfilds - MongoDB里的查询条件,目前支持一些简单的查询条件.(默认值为
null) - m_returnfilds - MongoDB需要返回的字段.(默认值为
null) - m_connection
- m_servers - MongoDB服务器的地址.(replica结构,数组格式)
- m_authentication - 如果需要MongoDB的登录验证使用下面配置(默认值为
null).- username - MongoDB连接的用户名.
- password - MongoDB连接的密码.
- authsource - MongoDB用户认证,默认为
admin. - replicaset - MongoDB的repliac结构的名字.
- ssl - MongoDB的ssl.(默认值为false)
- m_documentsinbatch - 一次性从mongodb往Elasticsearch里传入数据的条数. (你可以设置比较大的值,默认为1000.).
- m_delaytime- 每次进elasticsearch数据的间隔时间(默认值为1000ms).
- e_index - ElasticSearch里的index.
- e_type - ElasticSearch里的type,这里的type主要为了使用bulk.
- e_connection
- e_server - ElasticSearch的连接字符串.
- e_httpauth - 如果ElasticSearch需要登录验证使用下面配置(默认值为
null).- username - ElasticSearch连接的用户名.
- password - ElasticSearch连接的密码.
- e_pipeline - ElasticSearch 中pipeline的名称.(没有pipeline就填null)
- e_iscontainattachment - pipeline是否包含附件规则(默认值为false).
四、如何使用
用户可以事先在/crawlerDataConfig目录下编辑好自己的配置文件,文件必须以json格式存放.
在文件根目录下,打开cmd命令窗口,输入以下信息:
node app.js
项目启动后,修改配置文件 (如:mycarts.json),数据也会实时同步。或者修改mongodb中的某一条数据,也会实时同步到elasticsearch中。
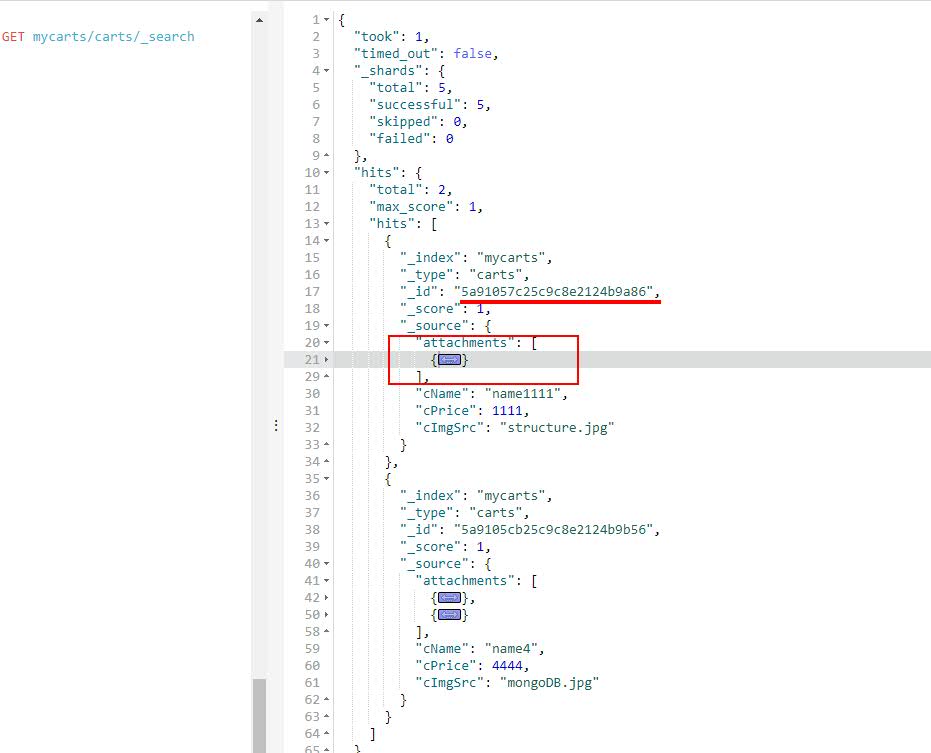
PS:如何把mongodb的主文档和附件信息都同步到elasticsearch中?
利用elasticsearch的pipeline来实现。
首先需要创建一个pipeline到elasticsearch中:
PUT _ingest/pipeline/mypipeline
{
"description" : "Extract attachment information from arrays",
"processors" : [
{
"foreach": {
"field": "attachments",
"processor": {
"attachment": {
"target_field": "_ingest._value.attachment",
"field": "_ingest._value.data"
}
}
}
}
]
}
然后在配置文件中(如:mycarts.json)修改节点数据即可
"e_pipeline": "mypipeline"
五、结果展示
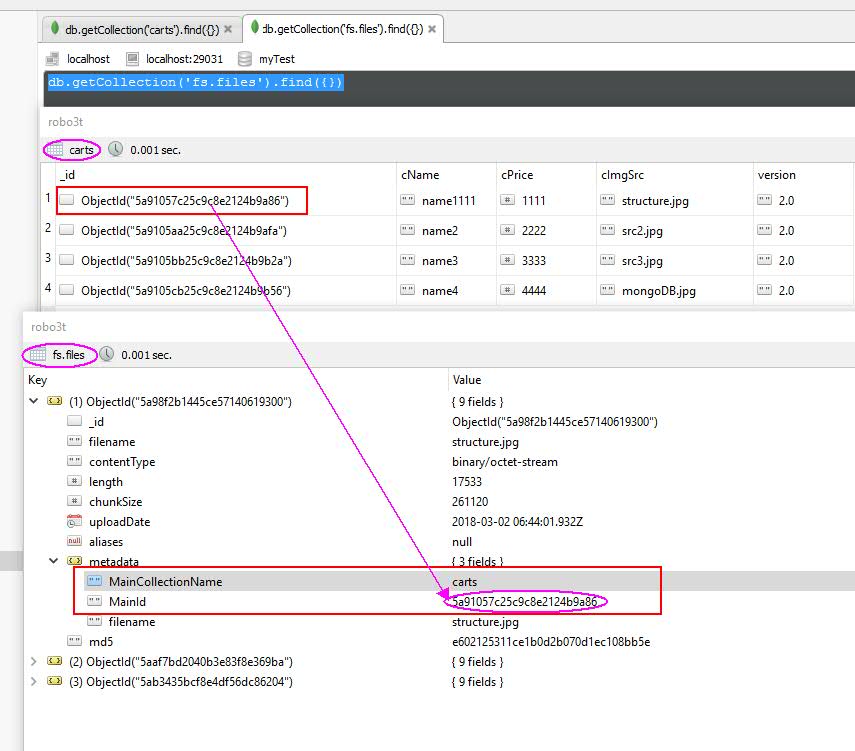
mongodb里面的数据
elasticsearch里面的数据
基于nodejs将mongodb的数据实时同步到elasticsearch的更多相关文章
- mysql数据实时同步到Elasticsearch
业务需要把mysql的数据实时同步到ES,实现低延迟的检索到ES中的数据或者进行其它数据分析处理.本文给出以同步mysql binlog的方式实时同步数据到ES的思路, 实践并验证该方式的可行性,以供 ...
- 基于netcore实现mongodb和ElasticSearch之间的数据实时同步的工具(Mongo2Es)
基于netcore实现mongodb和ElasticSearch之间的数据实时同步的工具 支持一对一,一对多,多对一和多对多的数据传输方式. 一对一 - 一个mongodb的collection对应一 ...
- sersync基于rsync+inotify实现数据实时同步
一.环境描述 需求:服务器A与服务器B为主备服务模式,需要保持文件一致性,现采用sersync基于rsync+inotify实现数据实时同步 主服务器A:192.168.1.23 从服务器B:192. ...
- sersync实现数据实时同步
1.1 第一个里程碑:安装sersync软件 1.1.1 将软件上传到服务器当中并解压 1.上传软件到服务器上 rz -E 为了便于管理上传位置统一设置为 /server/tools 中 2.解压软件 ...
- Linux下Rsync+sersync实现数据实时同步
inotify 的同步备份机制有着缺点,于是看了sersync同步,弥补了rsync的缺点.以下转自:http://www.osyunwei.com/archives/7447.html 前言: 一. ...
- Mysql数据实时同步
企业运维的数据库最常见的是 mysql;但是 mysql 有个缺陷:当数据量达到千万条的时候,mysql 的相关操作会变的非常迟缓; 如果这个时候有需求需要实时展示数据;对于 mysql 来说是一种灾 ...
- CentOS 6.5 rsync+inotify实现数据实时同步备份
CentOS 6.5 rsync+inotify实现数据实时同步备份 rsync remote sync 远程同步,同步是把数据从缓冲区同步到磁盘上去的.数据在内存缓存区完成之后还没有写入到磁盘 ...
- Rsync+sersync实现数据实时同步
前言: 一.为什么要用Rsync+sersync架构? 1.sersync是基于Inotify开发的,类似于Inotify-tools的工具 2.sersync可以记录下被监听目录中发生变化的(包括增 ...
- Linux下Rsync+Inotify-tools实现数据实时同步
Linux下Rsync+Inotify-tools实现数据实时同步 注意:下面的三个案例都是rsync 每次都是全量的同步(这就坑爹了),而且 file列表是循环形式触发rsync ,等于有10个文件 ...
随机推荐
- redis5.0集群配置
介绍 redis自3.0版本以来支持主从模式的集群,可用哨兵监控集群健康状态,但这种方式的集群很不成熟,数据备份需要全量拷贝.在之后的版本才真正支持集群分片. 在redis5.0中去除了以redis- ...
- Springcloud 引导上下文
SpringCloud为我们提供了bootstrap.properties的属性文件,我们可以在该属性文件里做我们的服务配置.可是,我们知道SpringBoot已经为我们提供了做服务配置的属性文件ap ...
- CAN总线上的消息单帧某个信号的值计算(C#)
public static ulong GetMotorolaSignalValue(byte[] data, int startBit, int bitLength) { ; , j =; i ...
- IdentityServer4同时使用多个GrantType进行授权和IdentityModel.Client部分源码解析
首先,介绍一下问题. 由于项目中用户分了三个角色:管理员.代理.会员.其中,代理又分为一级代理.二级代理等,会员也可以相互之间进行推荐. 将用户表分为了两个,管理员和代理都属于后台,在同一张表,会员单 ...
- vue使用layer主动关闭弹窗
关闭当前框的弹出层 layer.close(layer.index); 刷新父层 parent.location.reload(); // 父页面刷新 关闭iframe 弹出的全屏层 var inde ...
- Array + two points leetcode.18 - 4Sum
题面 Given an array nums of n integers and an integer target, are there elements a, b, c, and d in num ...
- Java中程序、进程、线程的区别。
程序.进程.线程的区别. 程序(program):是一个指令的集合.程序不能独立执行,只有被加载到内存中,系统为他分配资源后才能执行. 进程(process):一个执行中的程序称为进程. 进程是系统分 ...
- Cisco建网3层模型
网络畅通条件: 沿途路由器必须知道到达目标网络下一跳给谁 沿途路由器必须知道回来的数据包下一跳给谁 Router0~2均手动添加了到192.168.1.0/24网段的路由 分析1:PC0 ping B ...
- Kinect for Windows SDK开发入门(三):基础知识 下
原文来自:http://www.cnblogs.com/yangecnu/archive/2012/04/02/KinectSDK_Application_Fundamentals_Part2.htm ...
- LOAD DATA INFILE读取CSV中一千万条数据至mysql
作业要求 构建一个关系模式和课本中的关系movies(title,year,length,movietype,studioname,producerC)一样的关系,名称自定,在这个关系中插入1000万 ...