PCA算法理解及代码实现
github:PCA代码实现、PCA应用
本文算法均使用python3实现
1. 数据降维
在实际生产生活中,我们所获得的数据集在特征上往往具有很高的维度,对高维度的数据进行处理时消耗的时间很大,并且过多的特征变量也会妨碍查找规律的建立。如何在最大程度上保留数据集的信息量的前提下进行数据维度的降低,是我们需要解决的问题。
对数据进行降维有以下优点:
(1)使得数据集更易使用
(2)降低很多算法的计算开销
(3)去除噪声
(4)使得结果易懂
降维技术作为数据预处理的一部分,即可使用在监督学习中也能够使用在非监督学习中。而降维技术主要有以下几种:主成分分析(Principal Component Analysis,PCA)、因子分析(Factor Analysis),以及独立成分分析(Independent Component Analysis, ICA)。其中主成分分析PCA应用最为广泛,本文也将详细介绍PCA。
2. 主成分分析(PCA)
我们利用一个例子来理解PCA如何进行降维的。
参考下图,对于样本数据 $ D=\lbrace x^{(1)},x^{(2)},...,x^{(m)} \rbrace$ ,其中 $ x^{(i)} = [ x^{(i)}_1 , x^{(i)}_2]^T $
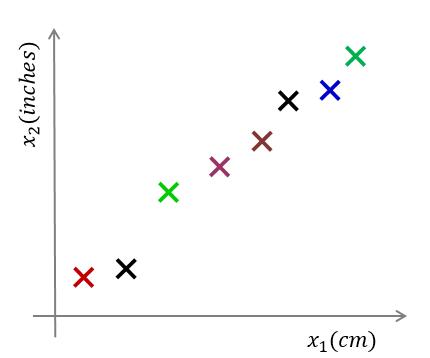
我们需要将上图的样本数据由二维降至一维。即 $ x^{(i)} \to z^{(i)} ,i=1,2,...,m $ ,如下图:

一般来说,这些样本点在坐标图中任意一条向量上都可以投影成一维的,那么我们如何选择最佳投影向量呢?在第1节中我们提到,需要在最大程度上保留数据集的信息量的前提下进行数据维度的降低,因此我们需要有优化目标来对图中的向量进行选择。
而PCA的优化目标就是:
(1)对于 $ 2 $ 维降到 $ 1 $ 维:找到一个投影方向,使得投影误差和最小。
(2)对于 $ n $ 维降到 $ k $ 维:找到 $ k $ 个向量定义的 $ k $ 维投影平面,使得投影误差和最小。
那么投影误差又是什么呢?投影误差即为,每一个样本点到投影向量或者投影平面的距离。而投影误差和即为所有样本点到投影向量或投影平面的距离的和。
为什么要将“投影误差和最小”最为优化目标呢?
我们以以下例子进行解释。下面两幅图展示了两种不同投影向量:
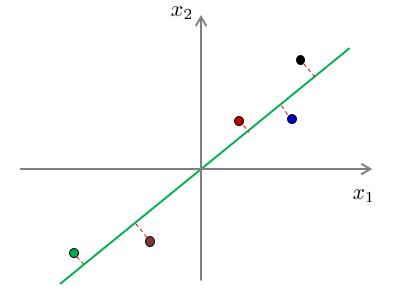
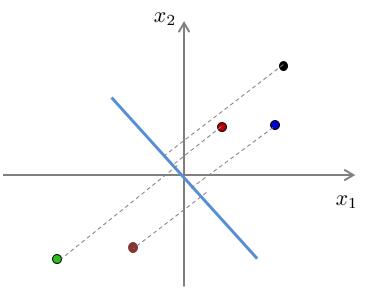
我们能够和清楚地看到,对于第一种向量的投影误差和一定比第二种的投影误差和要小。
对应以上两幅图的投影结果:

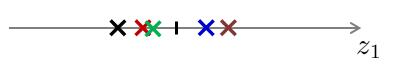
假设对于原样本中,位于第一象限的三个样本点属于类别“A”,位于第三象限的两个样本点属于类别“B”。经过投影后,我们可以看出,对于第一种降维,在降维后仍旧保持了位于原点右侧的三个样本属于类别“A”,位于原点左侧的两个样本属于类别“B”。而对于第二种投影,明显可以看出,已经不能够分辨出样本的类别了。换句话说,第二种投影方式丢失了一些信息。
因此,“投影误差和最小”便成为我们所需要优化的目标。
那么如何寻找投影误差最小的方向呢?
寻找到方差最大的方向即可。方差最大与投影误差最小这两个优化目标其实本质上是一样的,具体可参考周志华著《机器学习》一书,书中证明了最大可分性(误差最大)与最近重构性(投影和最小)两种优化等价。
到此我们就对PCA的降维方式已经有了初步的理解。
3. PCA算法思路与要点
3.1 PCA算法思路
PCA的算法思路主要是:数据从原来的坐标系转换到新的坐标系,由数据本身决定。转换坐标系时,以方差最大的方向作为坐标轴方向,因为数据的最大方差给出了数据的最重要的信息。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴选择的是与第一个新坐标轴正交且方差次大的方向。重复该过程,重复次数为原始数据的特征维数。
通过这种方式获得的新的坐标系,我们发现,大部分方差都包含在前面几个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面的几个含有绝大部分方差的坐标轴。事实上,这样也就相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,也就实现了对数据特征的降维处理。
3.2 PCA算法要点
根据以上PCA算法思路的描述,我们大概可以看出,对于PCA算法,其要点主要是如何找到方差最大的方向。
这里将提到有关线性代数里的一些内容:
(1)协方差矩阵
(1.1)特征 $ X_i $ 与特征 $ X_j $ 的协方差(Covariance): \[ Cov(X_i, X_j) = \frac{\sum_{k=1}^n(X_i^{(k)} - \overline{X}_i)(X_j^{(k)}-\overline{X}_j)}{n-1} \]
其中 $ X_i^{(k)}, X_j^{(k)} $ 表示特征 $ X_i.X_j $ 的第 $ k $ 个样本中的取值。而 $ \overline{X}_i,\overline{X}_j $ 则是表示两个特征的样本均值。
可以看出,当 $ X_i = X_j $ 时,协方差即为方差。
(1.2)对于一个只有两个特征的样本来说,其协方差矩阵为: \[ C = \begin{bmatrix} Cov(X_1,X_1) & Cov(X_1,X_2) \\ Cov(X_2,X_1) & Cov(X_2,X_2) \\ \end{bmatrix} \]
当特征数为 $ n $ 时,协方差矩阵为 $ n \times n $ 维的矩阵,且对角线为各特征的方差值。
(2)特征向量与特征值
对于矩阵 $ A $ ,若满足 $ A \zeta = \lambda \zeta $ ,则称 $ \zeta $ 是矩阵 $ A $ 的特征向量,而 $ \lambda $ 则是矩阵 $ A $ 的特征值。将特征值按照从大到小的顺序进行排序,选择前 $ k $ 个特征值所对应的特征向量即为所求投影向量。
对于特征值与特征向量的求解,主要是:特征值分解(当 $ A $ 为方阵时),奇异值SVD分解(当 $ A $ 不为方阵时)
4. PCA算法过程
输入:训练样本集 $ D ={x^{(1)},x^{(2)},...,x^{(m)}} $ ,低维空间维数 $ d' $ ;
过程:.
1:对所有样本进行中心化(去均值操作): $ x_j^{(i)} \leftarrow x_j^{(i)} - \frac{1}{m} \sum_{i=1}^m x_j^{(i)} $ ;
2:计算样本的协方差矩阵 $ XX^T $ ;
3:对协方差矩阵 $ XX^T $ 做特征值分解 ;
4:取最大的 $ d' $ 个特征值所对应的特征向量 $ w_1,w_2,...,w_{d'} $
5:将原样本矩阵与投影矩阵相乘: $ X \cdot W $ 即为降维后数据集 $ X' $ 。其中 $ X $ 为 $ m \times n $ 维, $ W = [w_1,w_2,...,w_{d'}] $ 为 $ n \times d' $ 维。
5:输出:降维后的数据集 $ X' $
5. PCA算法分析
优点:使得数据更易使用,并且可以去除数据中的噪声,使得其他机器学习任务更加精确。该算法往往作为预处理步骤,在数据应用到其他算法之前清洗数据。
缺点:数据维度降低并不代表特征的减少,因为降维仍旧保留了较大的信息量,对结果过拟合问题并没有帮助。不能将降维算法当做解决过拟合问题方法。如果原始数据特征维度并不是很大,也并不需要进行降维。
引用及参考:
[1]《机器学习》周志华著
[2]《机器学习实战》Peter Harrington著
[3] https://www.cnblogs.com/zy230530/p/7074215.html
[4] http://www.cnblogs.com/zhangchaoyang/articles/2222048.html
[5] https://www.cnblogs.com/terencezhou/p/6235974.html
写在最后:本文参考以上资料进行整合与总结,属于原创,文章中可能出现理解不当的地方,若有所见解或异议可在下方评论,谢谢!
若需转载请注明:https://www.cnblogs.com/lliuye/p/9156763.html
PCA算法理解及代码实现的更多相关文章
- kmeans算法理解及代码实现
github:kmeans代码实现1.kmeans代码实现2(包含二分k-means) 本文算法均使用python3实现 1 聚类算法 对于"监督学习"(supervised ...
- k邻近算法理解及代码实现
github:代码实现 本文算法均使用python3实现 1 KNN KNN(k-nearest neighbor, k近邻法),故名思议,是根据最近的 $ k $ 个邻居来判断未知点属于哪个类别 ...
- 模式识别(1)——PCA算法
作者:桂. 时间:2017-02-26 19:54:26 链接:http://www.cnblogs.com/xingshansi/articles/6445625.html 声明:转载请注明出处, ...
- 三种方法实现PCA算法(Python)
主成分分析,即Principal Component Analysis(PCA),是多元统计中的重要内容,也广泛应用于机器学习和其它领域.它的主要作用是对高维数据进行降维.PCA把原先的n个特征用数目 ...
- Python使用三种方法实现PCA算法[转]
主成分分析(PCA) vs 多元判别式分析(MDA) PCA和MDA都是线性变换的方法,二者关系密切.在PCA中,我们寻找数据集中最大化方差的成分,在MDA中,我们对类间最大散布的方向更感兴趣. 一句 ...
- 机器学习--主成分分析(PCA)算法的原理及优缺点
一.PCA算法的原理 PCA(principle component analysis),即主成分分析法,是一个非监督的机器学习算法,是一种用于探索高维数据结构的技术,主要用于对数据的降维,通过降维可 ...
- PCA算法 | 数据集特征数量太多怎么办?用这个算法对它降维打击!
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第27文章,我们一起来聊聊数据处理领域的降维(dimensionality reduction)算法. 我们都知道,图片 ...
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- PCA算法是怎么跟协方差矩阵/特征值/特征向量勾搭起来的?
PCA, Principle Component Analysis, 主成份分析, 是使用最广泛的降维算法. ...... (关于PCA的算法步骤和应用场景随便一搜就能找到了, 所以这里就不说了. ) ...
随机推荐
- Thinkphp5 使用composer中seeder播种机
前因: 前几天,客户要求做一个会员问答的系统,我就按流程做了,到了需要调用数据库数据时,觉得一个个添加又有点笨~ 解决过程: 后来查了查手册,看看国外blog案例,我搞出来了个不错的方法~~~ 我的使 ...
- thinkphp5使用workerman定时器定时爬取某站点新闻资讯等内容
1.首先通过 composer 安装workerman,在thinkphp5完全开发手册的扩展->coposer包->workerman有详细说明: #在项目根目录执行以下指令compos ...
- Python学习:10.Python装饰器讲解(一)
情景介绍 一天,在你正在努力加班的时候,老板给交给你了一个任务,就是在这段代码里将所有函数开始输出一个‘hello’最后输出当前时间,再输出一个“end”,这段代码里包含了大量的函数,你会怎么做? d ...
- linux进程篇 (三) 进程间的通信3 IPC通信
3 IPC通信 用户空间 进程A <----无法通信----> 进程B -----------------|--------------------------------------|- ...
- c语言杨氏矩阵算法
杨氏矩阵 有一个二维数组.数组的每行从左到右是递增的,每列从上到下是递增的.在这样的数组中查找一个数字是否存在.时间复杂度小于O(N);数组:1 2 32 3 43 4 5 1 3 42 4 54 5 ...
- JavaWeb——升级赛-学生成绩管理系统(2).java---19.01.03
dao.java package Dao; import java.sql.Connection;import java.sql.ResultSet;import java.sql.SQLExcept ...
- [Real World Haskell翻译]第24章 并发和多核编程 第一部分并发编程
第24章 并发和多核编程 第一部分并发编程 当我们写这本书的时候,CPU架构正在以比过去几十年间更快的速度变化. 并发和并行的定义 并发程序需要同时执行多个不相关任务.考虑游戏服务器的例子:它通常是由 ...
- C# 程序关闭托盘图标不会自动消失
c#程序关闭托盘图标不会自动消失,进程的托盘图标却不能随着进程的结束而自动消失 必须将鼠标移到图标上面时才能消失? 请问如何才能做到图标随着进程的结束而自动消失呢(外部强行结束,如在任务管理器将其 ...
- 北京Uber优步司机奖励政策(1月10日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 【Keras案例学习】 CNN做手写字符分类(mnist_cnn )
from __future__ import print_function import numpy as np np.random.seed(1337) from keras.datasets im ...