【spark】共享变量
Spark中的两个重要抽象是RDD和共享变量。
一般情况下,当Spark在集群的多个不同节点的多个任务上并行运行一个函数的时候,
它会把函数中涉及到的每个变量在每个节点每个任务上都生成一个副本。
Spark 操作实际上操作的是这个函数所用变量的一个独立副本。
这些变量被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。
通常跨任务的读写变量是低效的。
但是,有时候我们需要在多个任务之间共享变量,或者在任务和任务控制节点之间共享变量。
为了满足这种需求,Spark提供了两种有限的共享变量:广播变量( broadcast variable )和累加器( accumulator )。
1.广播变量
广播变量用来把变量在所有节点的内存之间进行共享。
广播变量允许开发人员在每台机器上缓存一个只读的变量,而不是为每台机器上每个任务生成一个副本 。
Spark的任务操作一般会跨越多个阶段,对于每个阶段内的所有任务所需要的公共数据,Spark都会自动进行广播。
语法:
SparkContext.broadcase(v);
广播变量就是对普通变量v的一个包装器,通过调用value方法就可以获取这个广播变量的值。
//建立内容为Array(1,2,3)的广播变量
val broadcastVal = sc.broadcast(Array(1,2,3))
//获取广播变量的值
broadcastVal.value()
注意:我们在把变量v建立成广播变量后,在集群中的任何函数,都应该使用broadcase(v),而不是v本身,
这样就不会把v重复的分发到使用变量v的节点上。此外,我们一旦建立了broadcase(v)之后,就不行再次发生修改。
2.累加器
累加器支持在所有不同节点之间进行累加操作。
累加器是仅仅被相关操作累加的变量,通常可以被用来实现计数器和求和。
Spark原生地支持数值型(numeric)的累加器,也可以自己编写对新类型的累加器。
可以通过SparkContext.longAccumulator()或者SparkContext.doubleAccumulator()来创建累加器。
参数有两个(Int,String),第一个参数为初始累加值,默认为0,第二个参数为累加器的名字。
运行在集群中的任务,就可以使用add()方法来把数值累加到累加器上。
但是任务节点执行做累加操作,不能读取累加器的值,只有任务控制节点(Driver Program)可以使用value方法来读取。
import org.apache.spark._
object MyRdd {
def main(args:Array[String]): Unit ={
//初始化配置:设置主机名和程序主类的名字
val conf = new SparkConf().setMaster("local").setAppName("MyRdd");
//通过conf来创建sparkcontext
val sc = new SparkContext(conf);
val accum = sc.longAccumulator("My Accumulator");//后边是计数器的名字
val list = List(1,2,3,4,5);
val rdd = sc.parallelize(list);
rdd.foreach(x => accum.add(x));//调用累加器求和
accum.value;//注意只有任务控制节点(Driver节点)才能使用value方法来获取累加器的值
}
}
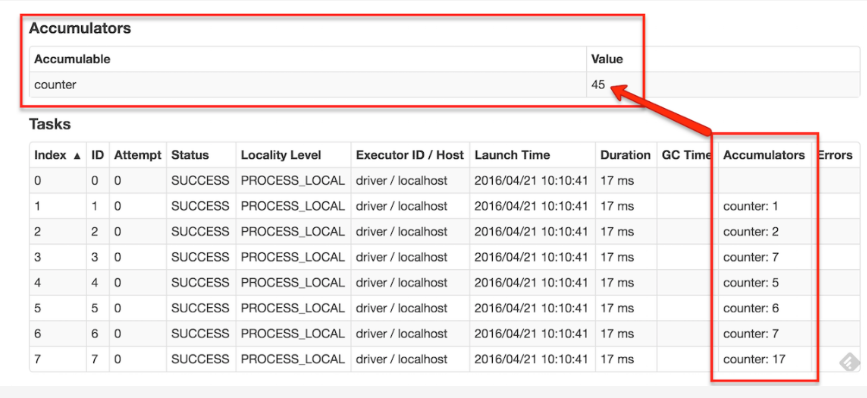
如果创建了一个具名的累加器,它可以在spark的UI中显示。这对于理解运行阶段(running stages)的过程有很重要的作用。
【spark】共享变量的更多相关文章
- spark共享变量
boradcast例子代码: scala版本 spark共享变量之Accumulator 例子代码: scala版本
- 7.spark共享变量
spark共享变量 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- Spark——共享变量
Spark执行不少操作时都依赖于闭包函数的调用,此时如果闭包函数使用到了外部变量驱动程序在使用行动操作时传递到集群中各worker节点任务时就会进行一系列操作: 1.驱动程序使将闭包中使用变量封装成对 ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- SPARK共享变量:广播变量和累加器
Shared Variables Spark does provide two limited types of shared variables for two common usage patte ...
- Spark分布式编程之全局变量专题【共享变量】
转载自:http://www.aboutyun.com/thread-19652-1-1.html 问题导读 1.spark共享变量的作用是什么?2.什么情况下使用共享变量?3.如何在程序中使用共享变 ...
- 9.Spark Streaming
Spark Streaming 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性 ...
- 8.Spark SQL
Spark SQL 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- 5.spark弹性分布式数据集
弹性分布式数据集 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- 4.Apache Spark的工作原理
Apache Spark的工作原理 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark ...
随机推荐
- 我的Android进阶之旅------>Android通用流行框架大全
Android通用流行框架大全 缓存 图片加载 图片处理 网络请求 网络解析 数据库 依赖注入 图表 后台处理 事件总线 响应式编程 Log框架 测试框架 调试框架 性能优化 本文转载于lavor的博 ...
- django使用celery实现异步操作
需求: django支持的http请求都是同步的,对于需要耗时较长的操作可能会导致阻塞.为此我们需要引入异步处理机制,即收到客户端请求后立即给予响应,具体任务交给另一个进程处理. 使用方法: 1. 安 ...
- Pantone色卡——安全装备的面板、丝印及铭牌颜色设计参考
可以参考上传文件<Pantone色卡电子版下载>
- 通信—HTTP与HTTPS
HTTP是客户端浏览器或其他程序与Web服务器之间的应用层通信协议.在Internet上的Web服务器上存放的都是超文本信息,客户机需要通过HTTP协议传输所要访问的超文本信息. HTTPS(全称:H ...
- 基于视觉反馈的步进电机X-Y平台控制
关键词:步进电机.XY平台.视觉反馈 用途:工业自动化 文章类型:原理介绍.随笔纪念 @Author:VShawn(singlex@foxmail.com) @Date:2017-05-01 @Lab ...
- Bytes to be written to the stream exceed the Content-Length bytes size specified 解决方法
context.Response.ContentType = encode; using (StreamWriter writer = new StreamWriter( ...
- 【转】解决Gradle报错找不到org.gradle.api.internal.project.ProjectInternal.getPluginManager()方法问题
源地址:http://www.mamicode.com/info-detail-1178200.html 一.概述 因为本地的AndroidStudio很久没用了,所以想要研究下github上的某个代 ...
- 搭建自己的npm仓库
第一步:安装Erlang环境 首先,安装必要的库 yum install build-essential yum install libncurses5-dev yum install libssl- ...
- dogo 官方翻译 Ajax with dojo/request
require(["dojo/request"], function(request){ request("helloworld.txt").then( fun ...
- Entity FrameWork 配置 之连接字符串隐藏或重用
C/S项目中使用EF,默认回生成app.config文件夹,软件打包安装成功之后就回生成一个对应exe.config.里面会包含配置的一些信息. 这里介绍给大家一种隐藏连接字符串的方式. 代码如下: ...