Spark——共享变量
Spark执行不少操作时都依赖于闭包函数的调用,此时如果闭包函数使用到了外部变量驱动程序在使用行动操作时传递到集群中各worker节点任务时就会进行一系列操作:
1、驱动程序使将闭包中使用变量封装成对象,驱动程序序列化对象,传给worker节点任务;
2、worker节点任务接收到对象,执行闭包函数;
由于使用外部变量势必会通过网络、序列化、反序列化,如外部变量过大或过多使用外部变量将会影响Spark程序的性能;
Spark提供了两种类型的共享变量(Shared Variables):广播变量(Broadcast Variables)、累加器(Accumulators );
广播变量(Broadcast Variables)
Spark提供的广播变量可以解决闭包函数引用外部大变量引起的性能问题;广播变量将只读变量缓存在每个worker节点中,Spark使用了高效广播算法分发变量从而提高通信性能;如直接在闭包函数中使用外部 变量该变量会缓存在每个任务(jobTask)中如果多个任务同时使用了一个大变量势必会影响到程序性能;
广播变量:每个worker节点中缓存一个副本,通过高效广播算法提高传输效率,广播变量是只读的;
Spark Scala Api与Java Api默认使用了Jdk自带序列化库,通过使用第三方或使用自定义的序列化库还可以进一步提高广播变量的性能;
广播变量使用示例:
val sc = SparkContext("");
val eigenValue = sc.bradcast(loadEigenValue())
val eigen = computer.map{x =>
val temp = eigenValue.value
...
...
}
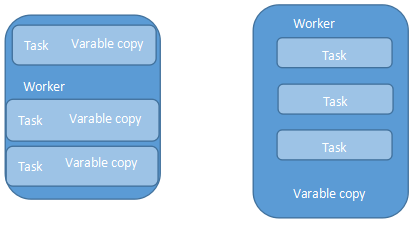
左节点不使用广播变量,右使用广播变量
累加器(Accumulators)
累加器可以使得worker节点中指定的值聚合到驱动程序中,如统计Spark程序执行过程中的事件总数等;
val sc = new SparkContext(...)
val file = sc.textFile("xxx.txt")
val eventCount = sc.accumulator(0,"EventAccumulator") //累加器初始值为0
val formatEvent = file.flatMap(line => {
if(line.contains("error")){
eventCount +=1
}
})
formatEvent.saveAsTextFile("eventData.txt")
println("error event count : " + eventCount);
在使用累加器(Accumulators)时需要注意,只有在行动操作中才会触发累加器,也就是说上述代码中由于flatMap()为转换操作因为Spark惰性特征所以只用当saveAsTextFile() 执行时累加器才会被触发;累加器只有在驱动程序中才可访问,worker节点中的任务不可访问累加器中的值;
Spark原生支持了数字类型的的累加器如:Int、Double、Long、Float等;此外Spark还支持自定义累加器用户可以通过继承AccumulableParam特征来实现自定义的累加器此外Spark还提供了accumulableCollection()累加集合用于;创建累加器时可以使用名字也可以不是用名字,当使用了名字时在Spark UI中可看到当中程序中定义的累加器, 广播变量存储级别为MEMORY_AND_DISK;
文章首发地址:Solinx
http://www.solinx.co/archives/570
Spark——共享变量的更多相关文章
- spark共享变量
boradcast例子代码: scala版本 spark共享变量之Accumulator 例子代码: scala版本
- 7.spark共享变量
spark共享变量 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- SPARK共享变量:广播变量和累加器
Shared Variables Spark does provide two limited types of shared variables for two common usage patte ...
- Spark分布式编程之全局变量专题【共享变量】
转载自:http://www.aboutyun.com/thread-19652-1-1.html 问题导读 1.spark共享变量的作用是什么?2.什么情况下使用共享变量?3.如何在程序中使用共享变 ...
- 9.Spark Streaming
Spark Streaming 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性 ...
- 8.Spark SQL
Spark SQL 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- 5.spark弹性分布式数据集
弹性分布式数据集 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- 4.Apache Spark的工作原理
Apache Spark的工作原理 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark ...
随机推荐
- JavaScript 闭包深入浅出
闭包是什么? 闭包是内部函数可以访问外部函数的变量.它可以访问三个作用域:首先可以访问自己的作用域(也就是定义在大括号内的变量),它也能访问外部函数的变量,和它能访问全局变量. 内部函数不仅可以访问外 ...
- Vue插件开发入门
相对组件来说,Vue 的插件开发受到的关注要少一点.但是插件的功能是十分强大的,能够完成许多 Vue 框架本身不具备的功能. 大家一般习惯直接调用现成的插件,比如官方推荐的 vue-router.vu ...
- T-sql语句查询执行顺序
前言 数据库的查询执行,毋庸置疑是程序员必备技能之一,然而数据库查询执行的过程绚烂多彩,却是很少被人了解,今天哥哥要带你装逼带你飞,深入一下这sql查询的来龙去脉,为查询的性能优化处理打个基础,或许面 ...
- Python遇到字符编码出问题的一个相对万能的办法
在使用Python做爬虫的过程中,经常遇到字符编码出问题的情况. UnicodeEncodeError: 'ascii' codec can't encode character u'\u6211' ...
- Git(远程仓库:git@oschina)-V2.0
1.注册git@osc(也就是“码云”) 这里会提示注册密码==push密码,反正一定要记住的东西. 2.安装git 这里要设置个人信息 git config --list //查看git信息 g ...
- linux poll函数
poll函数与select函数差不多 函数原型: #include <poll.h> int poll(struct pollfd fd[], nfds_t nfds, int timeo ...
- MVC5网站开发之一 总体概述
由于前几次都没能写完,这次年底总算有自由时间了,又想继续捣鼓一下.于是下载了VS 2015专业版(不知为什么我特别钟爱专业版,而不喜欢企业版).由于以前的教训,我这次决定写一个极简的Deom,简到什么 ...
- 【CSS进阶】试试酷炫的 3D 视角
写这篇文章的缘由是因为看到了这个页面: 戳我看看(移动端页面,使用模拟器观看) 运用 CSS3 完成的 3D 视角,虽然有一些晕3D,但是使人置身于其中的交互体验感觉非常棒,运用在移动端制作一些 H5 ...
- 翻唱曲练习:龙珠改主题曲 【Dragon Soul】龙之魂
首先这是个人翻唱曲: 这个是原版(燃): 伴奏: 翻唱合成为动漫AMV 出镜翻唱: 全民K歌链接: http://kg.qq.com/node/play?s=aYpbMWb6UwoU&g_f ...
- 13.JAVA之GUI编程将程序打包jar
jar基本命令: 目标:将下列MyMenuDemo.java代码打包成jar. 方法如下: 1.把java代码放到d:\myclass目录下. 2.按下快捷键ctrl+r,打开运行窗口,输入cmd后回 ...