深度学习笔记 (二) 在TensorFlow上训练一个多层卷积神经网络
上一篇笔记主要介绍了卷积神经网络相关的基础知识。在本篇笔记中,将参考TensorFlow官方文档使用mnist数据集,在TensorFlow上训练一个多层卷积神经网络。
下载并导入mnist数据集
首先,利用input_data.py来下载并导入mnist数据集。在这个过程中,数据集会被下载并存储到名为"MNIST_data"的目录中。
import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
其中mnist是一个轻量级的类,其中以Numpy数组的形式中存储着训练集、验证集、测试集。
进入一个交互式的TensorFlow会话
TensorFlow实际上对应的是一个C++后端,TensorFlow使用会话(Session)与后端连接。通常,我们都会先创建一个图,然后再在会话(Session)中启动它。而InteractiveSession给了我们一个交互式会话的机会,使得我们可以在运行图(Graph)的时候再插入计算图,否则就要在启动会话之前构建整个计算图。使用InteractiveSession会使得我们的工作更加便利,所以大部分情况下,尤其是在交互环境下,我们都会选择InteractiveSession。
import tensorflow as tf
sess = tf.InteractiveSession()
利用占位符处理输入数据
关于占位符的概念,官方给出的解释是“不是特定的值,而是可以在TensorFlow运行某一计算时根据该占位符输入具体的值”。这里也比较容易理解。
x = tf.placeholder("float", shape=[None,784])
x代表的是输入图片的浮点数张量,因此定义dtype为"float"。其中,shape的None代表了没有指定张量的shape,可以feed任何shape的张量,在这里指batch的大小未定。一张mnist图像的大小是2828,784是一张展平的mnist图像的维度,即2828=784。
y_ = tf.placeholder("float", shape=[None,10])
由于mnist数据集是手写数字的数据集,所以分的类别也只有10类,分别代表了0~9十个数字。
权重与偏置项初始化
在对权重初始化的过程中,我们加入少量的噪声来打破对称性与避免梯度消失,在这里我们设定权重的标准差为0.1。 由于我们使用的激活函数是ReLU,而ReLU的定义是$$y=
\begin{cases}
0& (x\ge0)\
x& (x<0)
\end{cases}$$
ReLU对应的图像是下图左边的函数图像。

但是我们可以注意到,ReLU在\(x<0\)的部分是硬饱和的,所以随着训练推进,部分输入可能会落到硬饱和区,导致权重无法更新,出现“神经元死亡”。虽然在之后的研究中,有人提出了PReLU和ELU等新的激活函数来改进,但我们在这里的训练,还是应该用一个较小的正数来初始化偏置项,避免神经元节点输出恒为0的问题。
#初始化权重
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev = 0.1)
return tf.Variable(initial)
#初始化偏置项
def bias_variable(shape):
initial = tf.constant(0.1, shape = shape )
return tf.Variable(initial)
卷积与池化
在这里,我们使用步长为1、相同填充(padding='SAME')的办法进行卷积,关于相同填充和有效填充的区别在上一篇笔记讲得比较清楚了,在这里就不赘述了。与此同时,使用2x2的网格以max pooling的方法池化。
#卷积过程
def conv2d(x,w):
return tf.nn.conv2d(x,w,
strides=[1,1,1,1],padding='SAME')
#池化过程
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],
strides=[1,2,2,1],padding='SAME')
第一层卷积
(1 #28x28->32 #28x28)
首先在每个5x5网格中,提取出32张特征图。其中weight_variable中前两维是指网格的大小,第三维的1是指输入通道数目,第四维的32是指输出通道数目(也可以理解为使用的卷积核个数、得到的特征图张数)。每个输出通道都有一个偏置项,因此偏置项个数为32。
w_conv1 = weight_variable([5,5,1,32])
b_conv1=bias_variable([32])
为了使之能用于计算,我们使用reshape将其转换为四维的tensor,其中第一维的-1是指我们可以先不指定,第二三维是指图像的大小,第四维对应颜色通道数目,灰度图对应1,rgb图对应3.
x_image=tf.reshape(x,[-1,28,28,1])
而后,我们利用ReLU激活函数,对其进行第一次卷积。
h_conv1=tf.nn.relu(conv2d(x_image,w_conv1)+b_conv1)
第一次池化
(32 #28x28->32 #14x14)
比较容易理解,使用2x2的网格以max pooling的方法池化。
h_pool1=max_pool_2x2(h_conv1)
第二层卷积与第二次池化
(32 #14x14->64 #14x14->64 #7x7)
与第一层卷积、第一次池化类似的过程。
w_conv2=weight_variable([5,5,32,64])
b_conv2=bias_variable([64])
h_conv2=tf.nn.relu(conv2d(h_pool1,w_conv2)+b_conv2)
h_pool2=max_pool_2x2(h_conv2)
密集连接层
此时,图片是7x7的大小。我们在这里加入一个有1024个神经元的全连接层。之后把刚才池化后输出的张量reshape成一个一维向量,再将其与权重相乘,加上偏置项,再通过一个ReLU激活函数。
w_fc1=weight_variable([7*7*64,1024])
b_fc1=bias_variable([1024])
h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64])
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,w_fc1)+b_fc1)
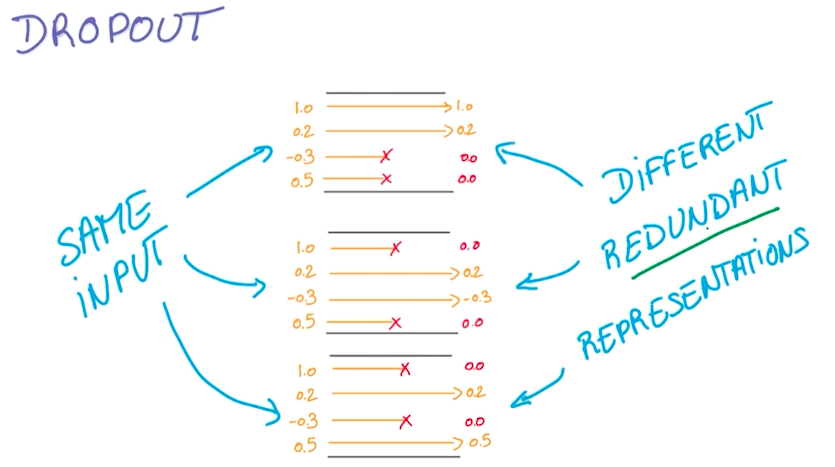
Dropout
keep_prob=tf.placeholder("float")
h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob)
这是一个比较新的也非常好用的防止过拟合的方法,想出这个方法的人基本属于非常crazy的存在。在Udacity-Deep Learning的课程中有提到这个方法——完全随机选取经过神经网络流一半的数据来训练,在每次训练过程中用0来替代被丢掉的激活值,其它激活值合理缩放。
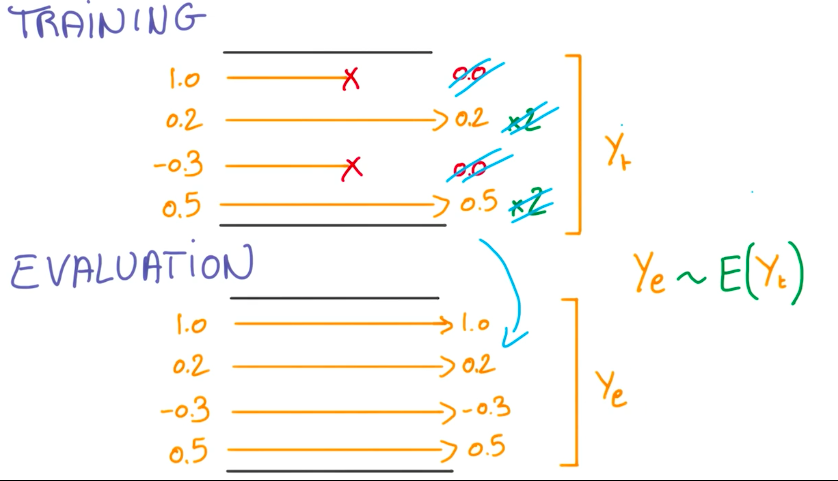
类别预测与输出
应用了简单的softmax,输出。
w_fc2=weight_variable([1024,10])
b_fc2=bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop,w_fc2)+b_fc2)
模型的评价
#计算交叉熵的代价函数
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
#使用优化算法使得代价函数最小化
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
#找出预测正确的标签
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
#得出通过正确个数除以总数得出准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.initialize_all_variables())
#每100次迭代输出一次日志,共迭代20000次
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print "step %d, training accuracy %g"%(i, train_accuracy)
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print "test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})
本文代码与部分内容来源或参考自:
TensorFlow官方文档
深度学习中的激活函数导引
Udacity-Deep Learning
深度学习笔记 (二) 在TensorFlow上训练一个多层卷积神经网络的更多相关文章
- 《SQL必知必会》学习笔记二)
<SQL必知必会>学习笔记(二) 咱们接着上一篇的内容继续.这一篇主要回顾子查询,联合查询,复制表这三类内容. 上一部分基本上都是简单的Select查询,即从单个数据库表中检索数据的单条语 ...
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 ...
- UFLDL深度学习笔记 (二)SoftMax 回归(矩阵化推导)
UFLDL深度学习笔记 (二)Softmax 回归 本文为学习"UFLDL Softmax回归"的笔记与代码实现,文中略过了对代价函数求偏导的过程,本篇笔记主要补充求偏导步骤的详细 ...
- TensorFlow 深度学习笔记 逻辑回归 实践篇
Practical Aspects of Learning 转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎star,有 ...
- Google TensorFlow深度学习笔记
Google Deep Learning Notes Google 深度学习笔记 由于谷歌机器学习教程更新太慢,所以一边学习Deep Learning教程,经常总结是个好习惯,笔记目录奉上. Gith ...
- 深度学习(二十六)Network In Network学习笔记
深度学习(二十六)Network In Network学习笔记 Network In Network学习笔记 原文地址:http://blog.csdn.net/hjimce/article/deta ...
- 【深度学习笔记】(二)基于MNIST数据集的神经网络实验
一.介绍 MNIST(Mixed National Institute of Standards and Technology database)是网上著名的公开数据库之一,是一个入门级的计算机视觉数 ...
- tensorflow学习笔记二:入门基础 好教程 可用
http://www.cnblogs.com/denny402/p/5852083.html tensorflow学习笔记二:入门基础 TensorFlow用张量这种数据结构来表示所有的数据.用一 ...
- 2020年Yann Lecun深度学习笔记(上)
2020年Yann Lecun深度学习笔记(上)
随机推荐
- NAT和DHCP
涉及的命令 NAT 动态NAT清除:clear ip nat translation * 进入路由器环回接口:int loo 0 静态NAT清除: (config)#No ip nat inside ...
- 关于c++随机种子srand( time(NULL) )的设置问题
设置随机种子srand( time(NULL) ) ,在程序中只需要设置一次就好,而且不能被调用多次,直接看列子. a:每次都重新设置随机种子 #include<iostream> #in ...
- 在centos6.7通过源码安装python3.6.7报错“zipimport.ZipImportError: can't decompress data; zlib not available”
在centos6.7通过源码安装python3.6.7报错: zipimport.ZipImportError: can't decompress data; zlib not available 从 ...
- npm install路径
我们在webpack项目中使用npm install命令安装很多模块 但是很多时候都不知道这些模块安装在哪里,想要删除的时候找不到,所有想要明确的知道npm的安装路径 首先,npm install 安 ...
- .Net Core如何在任意位置获取配置文件的内容
前几天群里有人问,我想在程序里的任意位置读取appsetting.json里的配置,该怎么搞. 话不多说上源码 首先,要想读取配置文件我们要用到IConfiguration 接口,这个接口在Start ...
- 搭建Jupyter Notebook服务器
昨天发了Jupyter的使用,补一篇Jupyter服务器的搭建~ 一.搭建Jupyter 1.安装 使用virtualenv建虚拟环境.在虚拟环境中安装jupyter.matplotlib等等需要的库 ...
- python2x和python3x的一些区别
python2x:各种按照自己代码习惯给python贡献源码 python3x:重写之后的源码,优美,清晰,简单 版本 打印函数 rang函数 输入函数 python2x print 或 print( ...
- ecshop跨站漏洞详情及修补网站漏洞
ecshop目前最新版本为4.0,是国内开源的一套商城系统,很多外贸公司,以及电商平台都在使用,正因为使用的人数较多,很多攻击者都在挖掘该网站的漏洞,就在最近ecshop被爆出高危漏洞,该漏洞利用跨站 ...
- centos配置NTP服务器
时间服务器: NTP(Network Time Protocol,网络时间协议)是用来使用网络中的各个计算机时间同步的一种协议,NTP服务器就是利用NTP协议提供时间同步服务的. 一.环境准备: 1. ...
- 使用OpenLayers发布地图
OpenLayers是用于制作交互式Web地图的开源客户端JavaScript类库,制作的地图几乎可以在所有的浏览器中查看.因为是客户端类库,它不需要特殊的服务器端软件或配置,甚至不用下载任何东西就可 ...