【原创】MapReduce实战(一)
应用场景:
用户每天会在网站上产生各种各样的行为,比如浏览网页,下单等,这种行为会被网站记录下来,形成用户行为日志,并存储在hdfs上。格式如下:
17:03:35.012ᄑpageviewᄑ{"device_id":"4405c39e85274857bbef58e013a08859","user_id":"0921528165741295","ip":"61.53.69.195","session_id":"9d6dc377216249e4a8f33a44eef7576d","req_url":"http://www.bigdataclass.com/product/1527235438747427"}
这是一个类Json 的非结构化数据,主要内容是用户访问网站留下的数据,该文本有device_id,user_id,ip,session_id,req_url等属性,前面还有17:03:20.586ᄑpageviewᄑ,这些非结构化的数据,我们想把该文本通过mr程序处理成被数仓所能读取的格式,比如Json串形式输出,具体形式如下:
{"time_log":1527584600586,"device_id":"4405c39e85274857bbef58e013a08859","user_id":"0921528165741295","active_name":"pageview","ip":"61.53.69.195","session_id":"9d6dc377216249e4a8f33a44eef7576d","req_url":"http://www.bigdataclass.com/my/0921528165741295"}
代码工具:intellij idea, maven,jdk1.8
操作步骤:
- 配置 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>netease.bigdata.course</groupId>
<artifactId>etl</artifactId>
<version>1.0-SNAPSHOT</version> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.6</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.4</version>
</dependency>
</dependencies> <build>
<sourceDirectory>src/main</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>
jar-with-dependencies
</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin> </plugins>
</build> </project>
2.编写主类这里为了简化代码量,我将方法类和执行类都写在ParseLogJob.java类中
package com.bigdata.etl.job; import com.alibaba.fastjson.JSONObject;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat; public class ParseLogJob extends Configured implements Tool {
//日志解析函数 (输入每一行的值)
public static Text parseLog(String row) throws ParseException {
String[] logPart = StringUtils.split(row, "\u1111");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
long timeLog = dateFormat.parse(logPart[0]).getTime();
String activeName = logPart[1];
JSONObject bizData=JSONObject.parseObject(logPart[2]);
JSONObject logData = new JSONObject(); logData.put("active_name",activeName);
logData.put("time_log",timeLog);
logData.putAll(bizData);
return new Text(logData.toJSONString());
} //输入key类型,输入value类型,输出。。(序列化类型)
public static class LogMapper extends Mapper<LongWritable,Text,NullWritable,Text>{
//输入key值 输入value值 map运行的上下文变量
public void map(LongWritable key ,Text value ,Context context) throws IOException,InterruptedException{
try {
Text parseLog = parseLog(value.toString());
context.write(null,parseLog);
} catch (ParseException e) {
e.printStackTrace();
} }
} public int run(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration config = getConf();
Job job= Job.getInstance(config);
job.setJarByClass(ParseLogJob.class);
job.setJobName("parseLog");
job.setMapperClass(LogMapper.class);
//设置reduce 为0
job.setNumReduceTasks(0);
//命令行第一个参数作为输入路径
FileInputFormat.addInputPath(job,new Path(args[0]));
//第二个参数 输出路径
Path outPutPath = new Path(args[1]);
FileOutputFormat.setOutputPath(job,outPutPath);
//防止报错 删除输出路径
FileSystem fs = FileSystem.get(config);
if (fs.exists(outPutPath)){
fs.delete(outPutPath,true);
}
if (!job.waitForCompletion(true)){
throw new RuntimeException(job.getJobName()+"fail");
}
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new ParseLogJob(), args);
System.exit(res);
}
}
3.打包上传到服务器
4.执行程序
我们在hdfs 中创建了input和output做为输入输出路径
hadoop jar ./etl-1.0-SNAPSHOT-jar-with-dependencies.jar com.bigdata.etl.job.ParseLogJob /user/1141690160/input /user/1141690160/output
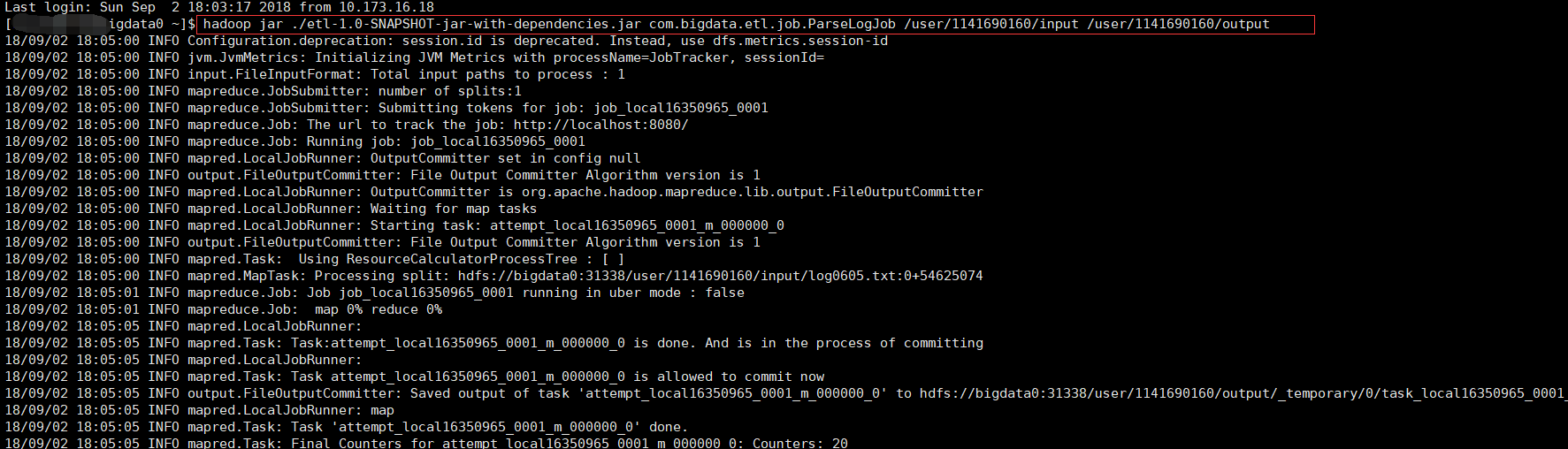
程序已经map完,因为我们没有对reduce进行操作,所以reduce为0
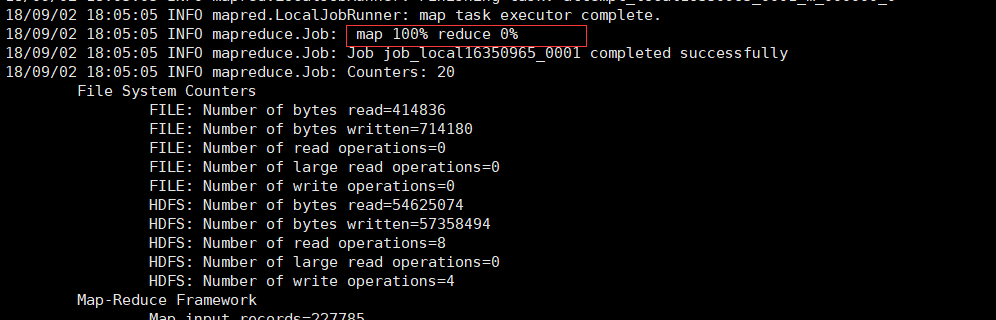
去hdfs 查看一下我们map完的文件

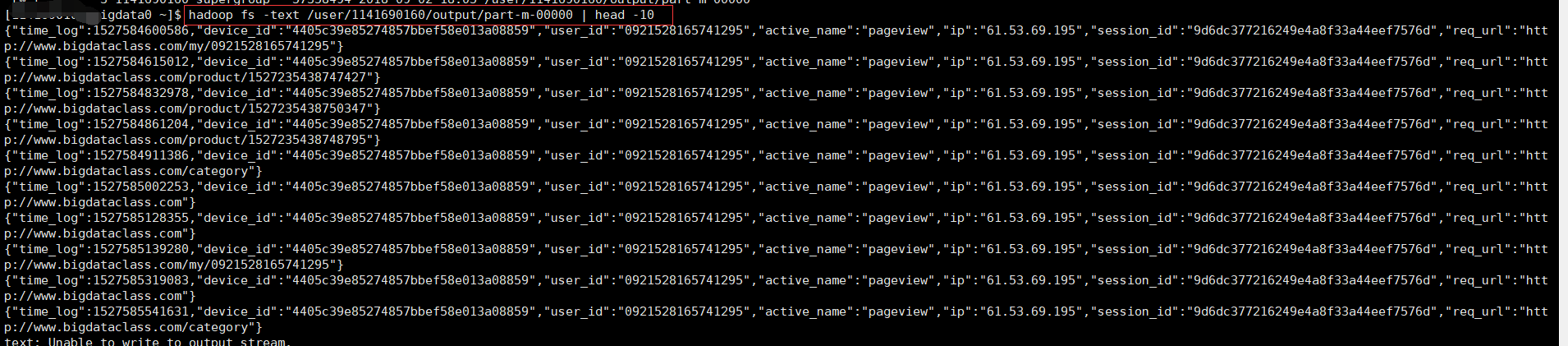
至此,一个简单的mr程序跑完了。
【原创】MapReduce实战(一)的更多相关文章
- MapReduce实战:邮箱统计及多输出格式实现
紧接着上一篇博文我们学习了MapReduce得到输出格式之后,在这篇博文里,我们将通过一个实战小项目来熟悉一下MultipleOutputs(多输出)格式的用法. 项目需求: 假如这里有一份邮箱数据文 ...
- MapReduce实战项目:查找相同字母组成的字谜
实战项目:查找相同字母组成的字谜 项目需求:一本英文书籍中包含有成千上万个单词或者短语,现在我们要从中找出相同字母组成的所有单词. 数据集和期望结果举例: 思路分析: 1)在Map阶段,对每个word ...
- MapReduce实战:统计不同工作年限的薪资水平
1.薪资数据集 我们要写一个薪资统计程序,统计数据来自于互联网招聘hadoop岗位的招聘网站,这些数据是按照记录方式存储的,因此非常适合使用 MapReduce 程序来统计. 2.数据格式 我们使用的 ...
- mapreduce实战:统计美国各个气象站30年来的平均气温项目分析
气象数据集 我们要写一个气象数据挖掘的程序.气象数据是通过分布在美国各地区的很多气象传感器每隔一小时进行收集,这些数据是半结构化数据且是按照记录方式存储的,因此非常适合使用 MapReduce 程序来 ...
- MapReduce实战--倒排索引
本文地址:http://www.cnblogs.com/archimedes/p/mapreduce-inverted-index.html,转载请注明源地址. 1.倒排索引简介 倒排索引(Inver ...
- MapReduce实战(三)分区的实现
需求: 在实战(一)的基础 上,实现自定义分组机制.例如根据手机号的不同,分成不同的省份,然后在不同的reduce上面跑,最后生成的结果分别存在不同的文件中. 对流量原始日志进行流量统计,将不同省份的 ...
- MapReduce实战:自定义输入格式实现成绩管理
1. 项目需求 我们取有一份学生五门课程的期末考试成绩数据,现在我们希望统计每个学生的总成绩和平均成绩. 样本数据如下所示,每行数据的数据格式为:学号.姓名.语文成绩.数学成绩.英语成绩.物理成绩.化 ...
- 《OD大数据实战》MapReduce实战
一.github使用手册 1. 我也用github(2)——关联本地工程到github 2. Git错误non-fast-forward后的冲突解决 3. Git中从远程的分支获取最新的版本到本地 4 ...
- MapReduce实战1
MapReduce编程规范: (1)用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端) (2)Mapper的输入数据是KV对的形式(KV的类型可自定义) ...
随机推荐
- jquery加载方式,选择器,样式操作
原生js和css不兼容,jquery已经过测试,可放心使用 https://code.jquery.com 这个网站可以下载jquery的源码,比如把源码下载到js文件夹中,文件名为jquery- ...
- uC/OS-II 函数之时间相关函数
获得更多资料欢迎进入我的网站或者 csdn或者博客园 对于有热心的小伙伴在微博上私信我,说我的uC/OS-II 一些函数简介篇幅有些过于长应该分开介绍.应小伙伴的要求,特此将文章分开进行讲解.上文主要 ...
- bootstrap-table教程演示
Bootstrap Admin 效果展示 Table of contents Create Remove Update Export Tree Create 相关插件 bootstrap-valida ...
- php-elasticsearch scroll分页详解
背景 ps:首先我们在一个索引里面写入一万条以上的数据.作为数据源 现在我想看到第一万零一条数据,首先第一想法是,from 10000 size 1 ,这样做会包下面错误.显然是不成立的.此时便会用到 ...
- thinkphp3.2.3----图片上传并生成缩率图
public function uploadify(){ if(!IS_POST){ $this->error('非法!'); } $upload = $this->_upload(); ...
- 吃奶酪 状压dp
题目描述 房间里放着n块奶酪.一只小老鼠要把它们都吃掉,问至少要跑多少距离?老鼠一开始在(0,0)点处. 输入输出格式 输入格式: 第一行一个数n (n<=15) 接下来每行2个实数,表示第i块 ...
- 集合之四:List接口
查阅API,看List的介绍.有序的 collection(也称为序列).此接口的用户可以对列表中每个元素的插入位置进行精确地控制.用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的 ...
- yum安装pip命令
pip命令是python里的命令,类似于linux系统里的yum命令 我们只需要安装python-pip这个包即可. yum -y install python-pip 在linux下还有一个命令: ...
- Jmeter打开url时提示“请在微信客户端打开链接问题”
前提: 1.HTTP信息头管理器已添加了“User-Agent” 2.工作台添加HTTP代理服务器(注意端口和客户端填写的代理端口要一致) 但是运行的时候总是提示“请在微信客户端打开链接” 查阅各种资 ...
- JAVA中 package 和 import 的使用
1.打包--package 包名一般为小写,而类名的第一个字母一般为大写,这样在引用时,可以明显的分辨出包名和类名.如果在类的定义之前没有使用package定义包名,那么该类就属于缺 省的包. 1.1 ...