caffe使用
训练时, solver.prototxt中使用的是train_val.prototxt
./build/tools/caffe/train -solver ./models/bvlc_reference_caffenet/solver.prototxt
使用上面训练的网络提取特征,使用的网络模型是deploy.prototxt
./build/tools/extract_features.bin models/bvlc_refrence_caffenet.caffemodel models/bvlc_refrence_caffenet/deploy.prototxt

Caffe finetune
1、准备finetune的数据
image文件夹子里面放好来finetune的图片
train.txt中放上finetune的训练图片绝对路径,及其对应的类别
test.txt中放上finetune的测试图片绝对路径,及其对应的类别
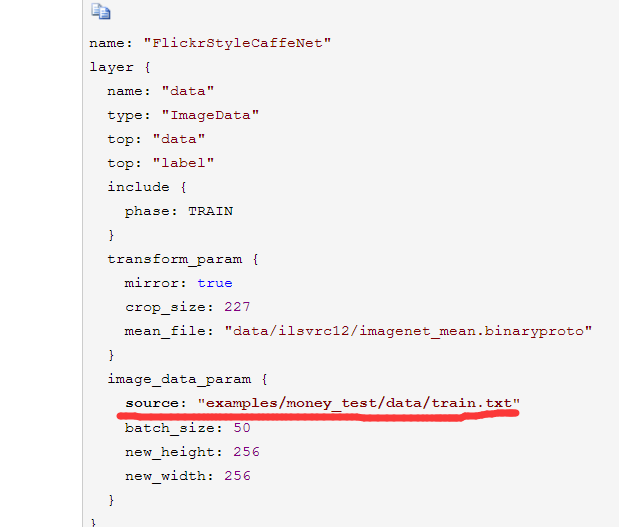
2、更改train_val.prototxt
更改最后一层

a)输出个数改变
b)最后一层学习率变大,由2变成20
3、更改solver.prototxt
a)stepsize变小:由100000变成20000
b)max_iter变小:450000变成50000
c)base_lr变小:0.01变成0.001
d)test_iter变小:1000变成100
4、调用命令finetune
caffe % ./build/tools/caffe train -solver models/finetune_flickr_style/solver.prototxt -weights models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel -gpu 0
注意:学习率有两个是一个是weight,一个是bias的学习率,一般bias的学习率是weight的两倍
decay是权值衰减,是加了正则项目,防止overfitting
the global weight_decay multiplies the parameter-specific decay_mult
solver.prototxt具体设置解释:

rmsprop:
net: "examples/mnist/lenet_train_test.prototxt"
test_iter: 100
test_interval: 500
#The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.0
weight_decay: 0.0005
#The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
display: 100
max_iter: 10000
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet_rmsprop"
solver_mode: GPU
type: "RMSProp"
rms_decay: 0.98 Adam:
net: "examples/mnist/lenet_train_test.prototxt"
test_iter: 100
test_interval: 500
#All parameters are from the cited paper above
base_lr: 0.001
momentum: 0.9
momentum2: 0.999
#since Adam dynamically changes the learning rate, we set the base learning
#rate to a fixed value
lr_policy: "fixed"
display: 100
#The maximum number of iterations
max_iter: 10000
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
type: "Adam"
solver_mode: GPU multistep:
net: "examples/mnist/lenet_train_test.prototxt"
test_iter: 100
test_interval: 500
#The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
#The learning rate policy
lr_policy: "multistep"
gamma: 0.9
stepvalue: 5000
stepvalue: 7000
stepvalue: 8000
stepvalue: 9000
stepvalue: 9500
# Display every 100 iterations
display: 100
#The maximum number of iterations
max_iter: 10000
#snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet_multistep"
#solver mode: CPU or GPU
solver_mode: GPU
卷积层的group参数,可以实现channel-wise的卷积操作
caffe使用的更多相关文章
- 基于window7+caffe实现图像艺术风格转换style-transfer
这个是在去年微博里面非常流行的,在git_hub上的代码是https://github.com/fzliu/style-transfer 比如这是梵高的画 这是你自己的照片 然后你想生成这样 怎么实现 ...
- caffe的python接口学习(7):绘制loss和accuracy曲线
使用python接口来运行caffe程序,主要的原因是python非常容易可视化.所以不推荐大家在命令行下面运行python程序.如果非要在命令行下面运行,还不如直接用 c++算了. 推荐使用jupy ...
- 基于Caffe的Large Margin Softmax Loss的实现(中)
小喵的唠叨话:前一篇博客,我们做完了L-Softmax的准备工作.而这一章,我们开始进行前馈的研究. 小喵博客: http://miaoerduo.com 博客原文: http://www.miao ...
- 基于Caffe的Large Margin Softmax Loss的实现(上)
小喵的唠叨话:在写完上一次的博客之后,已经过去了2个月的时间,小喵在此期间,做了大量的实验工作,最终在使用的DeepID2的方法之后,取得了很不错的结果.这次呢,主要讲述一个比较新的论文中的方法,L- ...
- 基于Caffe的DeepID2实现(下)
小喵的唠叨话:这次的博客,真心累伤了小喵的心.但考虑到知识需要巩固和分享,小喵决定这次把剩下的内容都写完. 小喵的博客:http://www.miaoerduo.com 博客原文: http://ww ...
- 基于Caffe的DeepID2实现(中)
小喵的唠叨话:我们在上一篇博客里面,介绍了Caffe的Data层的编写.有了Data层,下一步则是如何去使用生成好的训练数据.也就是这一篇的内容. 小喵的博客:http://www.miaoerduo ...
- 基于Caffe的DeepID2实现(上)
小喵的唠叨话:小喵最近在做人脸识别的工作,打算将汤晓鸥前辈的DeepID,DeepID2等算法进行实验和复现.DeepID的方法最简单,而DeepID2的实现却略微复杂,并且互联网上也没有比较好的资源 ...
- 基于英特尔® 至强™ 处理器 E5 产品家族的多节点分布式内存系统上的 Caffe* 培训
原文链接 深度神经网络 (DNN) 培训属于计算密集型项目,需要在现代计算平台上花费数日或数周的时间方可完成. 在最近的一篇文章<基于英特尔® 至强™ E5 产品家族的单节点 Caffe 评分和 ...
- 基于英特尔® 至强 E5 系列处理器的单节点 Caffe 评分和训练
原文链接 在互联网搜索引擎和医疗成像等诸多领域,深度神经网络 (DNN) 应用的重要性正在不断提升. Pradeep Dubey 在其博文中概述了英特尔® 架构机器学习愿景. 英特尔正在实现 Prad ...
- Caffe Python MemoryDataLayer Segmentation Fault
转载请注明出处,楼燚(yì)航的blog,http://home.cnblogs.com/louyihang-loves-baiyan/ 因为利用Pyhon来做数据的预处理比较方便,因此在data_l ...
随机推荐
- 给深度学习入门者的Python快速教程 - numpy和Matplotlib篇
始终无法有效把word排版好的粘贴过来,排版更佳版本请见知乎文章: https://zhuanlan.zhihu.com/p/24309547 实在搞不定博客园的排版,排版更佳的版本在: 给深度学习入 ...
- VIJOS1476旅游规划[树形DP 树的直径]
描述 W市的交通规划出现了重大问题,市政府下决心在全市的各大交通路口安排交通疏导员来疏导密集的车流.但由于人员不足,W市市长决定只在最需要安排人员的路口安放人员.具体说来,W市的交通网络十分简单,它包 ...
- 使用C#向ACCESS中插入数据
使用C#向ACCESS中插入数据 1.创建并打开一个OleDbConnection对象 string strConn = " Provider = Microsoft.Jet.OLEDB ...
- Integer.parseInt(String s) 和 Integer.valueOf(String s) 的区别
通过查看java.lang.Integer的源码可以发现, 它们最终调用的都是 /** * Parses the string argument as a signed integer in the ...
- BZOJ 1251: 序列终结者
1251: 序列终结者 Time Limit: 20 Sec Memory Limit: 162 MB Submit: 3773 Solved: 1579 [Submit][Status][Dis ...
- Incorrect string value异常解决
mysql数据库的一个问题 1366-Incorrect string value:'\xE5\x8D\xA1\xE5......' for column 'filename' at row 1 问题 ...
- 从大公司做.NET 开发跳槽后来到小公司的做.NET移动端微信开发的个人感慨
从14年11月的实习到正式的工作的工作我在上一家公司工作一年多了.然而到16年5月20跳槽后自己已经好久都没有在写博客了,在加上回学校毕业答辩3天以及拿档案中途耽搁了几天的时间,跳槽后虽然每天都在不停 ...
- 大新闻!HoloLens即将入华商用
昨天微软搞了大新闻,Terry和Alexi到了深圳,在WinHEC大会上宣布了2017上半年HoloLens正式入华商用. 关于HoloLens的技术原理和细节官方文档和报道已经披露很多了,他是一款真 ...
- MVC Form异步请求
@using (Ajax.BeginForm("CreateReviewInfo", "Review", new AjaxOptions { HttpMetho ...
- 比较Windows Azure 网站(Web Sites), 云服务(Cloud Services)and 虚机(Virtual Machines)
Windows Azure提供了几个部署web应用程序的方法,比如Windows Azure网站.云服务和虚拟机.你可能无法确定哪一个最适合您的需要,或者你可能清楚的概念,比如IaaS vs PaaS ...