Spark Streaming源码解读之Job动态生成和深度思考
本期内容 :
- Spark Streaming Job生成深度思考
- Spark Streaming Job生成源码解析
Spark Core中的Job就是一个运行的作业,就是具体做的某一件事,这里的JOB由于它是基于Spark Core所以Spark Streaming对其进行了封装。
大数据开发应用中少不了定时任务,是否相当于流式处理,只是期间的时间间隔的不同而已,所以数据都可以认为是流式处理。
一、 JobGenerator 作业动态生成的一个类 :
JobGenerator是个普通的类,作业调度的核心是提交作业、作业生成的方方面面、生成后的Job提交到集群都是由JobSchedule决定的,
这个类JobGenerator是基于 DStreams生成Jobs ,基于Spark Streaming编程时都会产生一系列的DStreams 。
DStreams有三种类型 :
1、 输入的DStreams,可以有各种不同的数据来源来构建
2、 输出的DStreams是一种逻辑级别的 ,它是Spark Streaming框架级别的,它的底层会翻译成为物理级别的Action,即RDD的Action;
3、 中间是业务逻辑的转换过程,及状态转换;
JobGenerator类源码 :

二、 Spark Streams是基于时间为触发器的 :
大数据开发应用中少不了定时任务,是否相当于流式处理,只是期间的时间间隔的不同,所有的数据都会成为流式处理,都基于Times为基准。
无论是时间还是事件都统一为一种抽象的统一标准;
DStreams 的Action也是逻辑级别的操作,Spark Streams会产生一个逻辑级别的Job ,但是它不会运行,而是由底层物理级别的RDD Action去触发的。
Job的这种特性让你有机会对其进行各种调度与优化。
基于时间窗口, 每5秒钟都会产生一个Job :

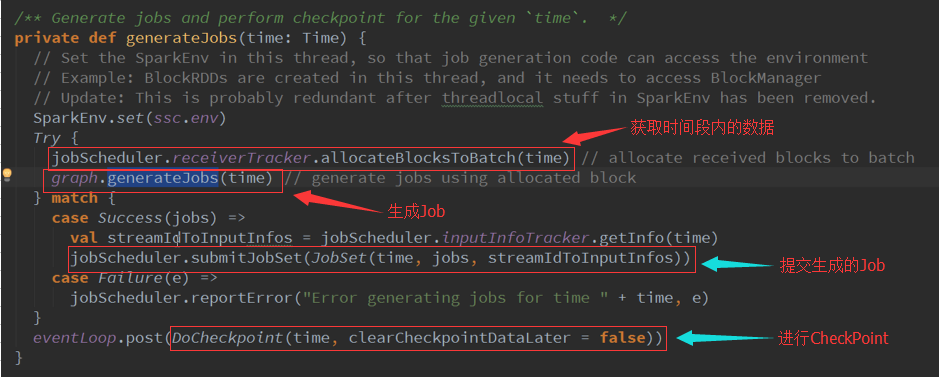
当把DStreams Action逻辑级别翻译成物理级别的最后一个的RDD的Action时,就会立即触发Job执行,如果直接就执行了Job,那就不存在队列 ,源数据也就不受管理了。既要完成翻译也要进行管理,所以把DStreams的依赖关系变成RDD间的依赖关系,最后一个RDD Action的操作翻译成最后一个Action级别的操作,这个翻译后的内容它是放在方法体内。因只是定义还没有执行,所以它里面的Action不会执行触发Job。当我们的JobGenerator 看见要调度的这个Job时再转过来在线程池中拿出一条线程执行刚才的封装的方法。
1、 JobGenerator基于时间运行源码 :

2、 使用方法进行封装,内部的方法不应该直接去调用,这个方法会基于我们的DStreams(逻辑级别)的操作物化成RDD(物理级别),GenerateJob源码:

3、 基于时间生成后会缓存起来 :

4、 GenerateJob : 生成RDD的实例,RDD的DAG依赖关系:
Spark Streaming源码解读之Job动态生成和深度思考的更多相关文章
- Spark Streaming源码解读之JobScheduler内幕实现和深度思考
本期内容 : JobScheduler内幕实现 JobScheduler深度思考 JobScheduler 是整个Spark Streaming调度的核心,需要设置多线程,一条用于接收数据不断的循环, ...
- 15、Spark Streaming源码解读之No Receivers彻底思考
在前几期文章里讲了带Receiver的Spark Streaming 应用的相关源码解读,但是现在开发Spark Streaming的应用越来越多的采用No Receivers(Direct Appr ...
- Spark Streaming源码解读之流数据不断接收和全生命周期彻底研究和思考
本节的主要内容: 一.数据接受架构和设计模式 二.接受数据的源码解读 Spark Streaming不断持续的接收数据,具有Receiver的Spark 应用程序的考虑. Receiver和Drive ...
- 11.Spark Streaming源码解读之Driver中的ReceiverTracker架构设计以及具体实现彻底研究
上篇文章详细解析了Receiver不断接收数据的过程,在Receiver接收数据的过程中会将数据的元信息发送给ReceiverTracker: 本文将详细解析ReceiverTracker的的架构 ...
- Spark Streaming源码解读之流数据不断接收全生命周期彻底研究和思考
本期内容 : 数据接收架构设计模式 数据接收源码彻底研究 一.Spark Streaming数据接收设计模式 Spark Streaming接收数据也相似MVC架构: 1. Mode相当于Rece ...
- Spark Streaming源码解读之Receiver生成全生命周期彻底研究和思考
本期内容 : Receiver启动的方式设想 Receiver启动源码彻底分析 多个输入源输入启动,Receiver启动失败,只要我们的集群存在就希望Receiver启动成功,运行过程中基于每个Tea ...
- Spark Streaming源码解读之生成全生命周期彻底研究与思考
本期内容 : DStream与RDD关系彻底研究 Streaming中RDD的生成彻底研究 问题的提出 : 1. RDD是怎么生成的,依靠什么生成 2.执行时是否与Spark Core上的RDD执行有 ...
- 16.Spark Streaming源码解读之数据清理机制解析
原创文章,转载请注明:转载自 听风居士博客(http://www.cnblogs.com/zhouyf/) 本期内容: 一.Spark Streaming 数据清理总览 二.Spark Streami ...
- 14:Spark Streaming源码解读之State管理之updateStateByKey和mapWithState解密
首先简单解释一下)) //要使用updateStateByKey方法,必须设置Checkpoint. ssc.checkpoint("/checkpoint/") val sock ...
随机推荐
- 在你决定从事iOS开发前需要清楚的几个问题
作者:David McGraw 翻译:丁丁(jackiehoo) 原文:http://www.xmcgraw.com/what-you-need-to-know-to-start-learning- ...
- 2014年3月份第4周51Aspx源码发布详情
足购库存管理系统源码 2014-3-24 [VS2010]功能介绍:这是为一个卖鞋子的朋友设计的,本来要用SQL数据库的,可是他说他不想安装,怕拖电脑速度,没办法,用了Access,在数据同步上和S ...
- Jdk内置性能测试工具的介绍
(一) JConsole JConsole使用JVM的可扩展性Java管理扩展(JMX)工具来提供关于运行于Java平台的应用程序的性能和资源消耗的信息. 在J2SE 5.0软件中,你需要启动使用-D ...
- 原生javascript加载运行
原生javascript加载运行 (function(){ //TODO sometings }()); 在要运行相应代码的位置加入script标签,创建函数并自执行; 关于window.onload ...
- 标准IO的简单应用,动静态库,读取系统时间并打印,模拟ls -l功能
2015.2.27星期五,小雨 标准IO实现的复制功能: #include <stdio.h>#include <errno.h> #define N 64 int main( ...
- [转]一个简单的Linux多线程例子 带你洞悉互斥量 信号量 条件变量编程
一个简单的Linux多线程例子 带你洞悉互斥量 信号量 条件变量编程 希望此文能给初学多线程编程的朋友带来帮助,也希望牛人多多指出错误. 另外感谢以下链接的作者给予,给我的学习带来了很大帮助 http ...
- Magento文件系统目录结构
magento │ .htaccess│ cron.php //系统cron程序,修改 linux的cron运行,加入magento的一些定时处理│ cron.sh│ favicon.ico ...
- 移动开发框架,Hammer.js 移动设备触摸手势js库
hammer.js是一个多点触摸手势库,能够为网页加入Tap.DoubleTap.Swipe.Hold.Pinch.Drag等多点触摸事件,免去自己监听底层touchstart.touchmove.t ...
- codeforces mysterious present 最长上升子序列+倒序打印路径
link:http://codeforces.com/problemset/problem/4/D #include <iostream> #include <cstdio> ...
- Codeforces Round #163 (Div. 2)
A. Stones on the Table \(dp(i)\)表示最后颜色为\(i\)的最长长度. B. Queue at the School 模拟. C. Below the Diagonal ...