HBase1.4.6安装搭建及shell命令使用
HBase1.4.6安装搭建
- HBase1.4.6安装搭建
- hbase shell
- 1、help命令
- 2、general 类
- 3、DDL相关
- 3.1创建表create
- 3.2修改(添加、删除)表结构Schema alter
- 3.3 获取表的描述describe
- 3.4 列举所有表list
- 3.5 表是否存在exists
- 3.6 启用表enable和禁用表disable
- 3.7 禁用满足正则表达式的所有表disable_all
- 3.8 启用满足正则表达式的所有表enable_all
- 3.9 删除表drop
- 3.10 删除满足正则表达式的所有表drop_all
- 3.11 获取某个表赋值给一个变量 get_table
- 3.12 获取rowKey所在的区 locate_region
- 3.13 显示hbase所支持的所有过滤器show_filters
- 4、 namespace
- 5、DML
一、前期准备(Hadoop,zookeeper,jdk)
启动hadoop
start-all.sh
验证
http://master:50070
启动zookeeper(三台分别启动)
zkServer.sh start
检查状态
zkServer.sh status
搭建Hbase
1、上传解压
tar -zxvf hbase-1.4.6-bin.tar.gz
2、配置环境变量
export HBASE_HOME=/usr/local/soft/hbase-1.4.6
$HBASE_HOME/bin
source /etc/profile
3、修改hbase-env.sh文件
增加java配置
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
关闭默认zk配置(原本是注释的,放开修改false)
export HBASE_MANAGES_ZK=false
4、修改hbase-site.xml文件
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1,node2,master</value>
</property>
5、修改regionservers文件
如果是伪分布式版本,增加master即可
node1
node2
6、同步到所有节点(如果是伪分布式不需要同步)
scp -r hbase-1.4.6 node1:`pwd`
scp -r hbase-1.4.6 node2:`pwd`
7、启动hbase集群 , 在master上执行
start-hbase.sh
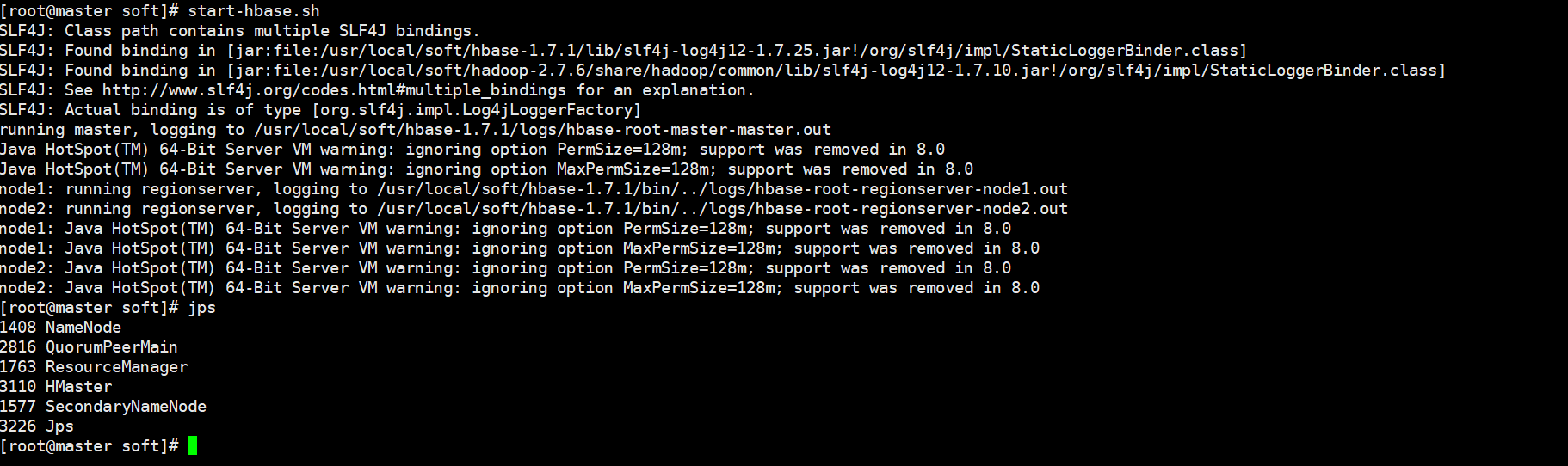
8、验证hbase
http://master:16010
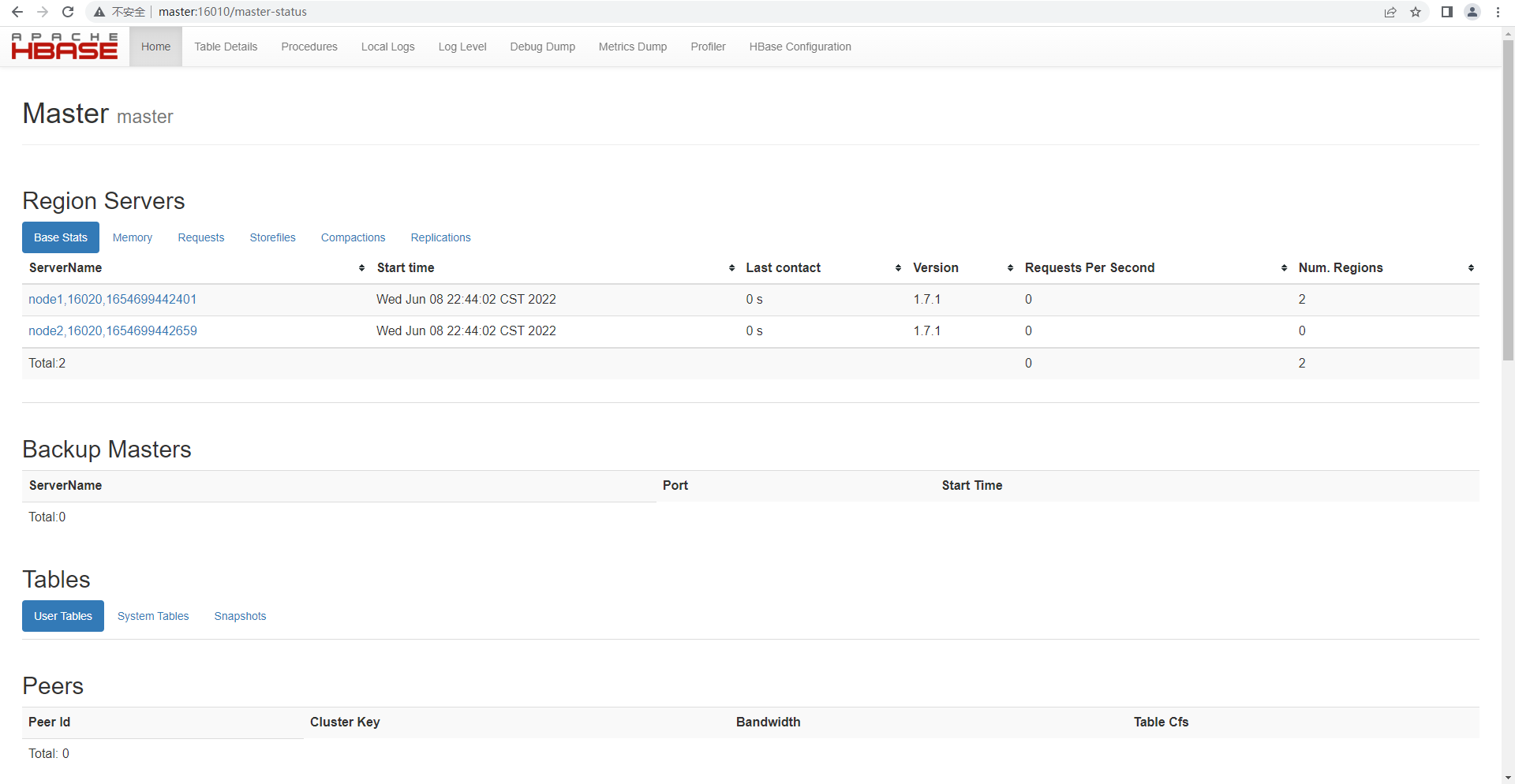
hbase日志文件所在的目录: /usr/local/soft/hbase-1.7.1/logs
9、关闭集群的命令
stop-hbase.sh
二、启动顺序
启动顺序
Hadoop及hbase集群启动顺序 zookeepeer -> hadoop -> hbase
停止顺序
Hadoop及hbase集群关闭顺序 hbase -> hadoop -> zookeepeer
三、重置hbase
1、关闭hbase集群
1)杀死进程
2)stop-hbase.sh
2、删除数据 hdfs
hdfs dfs -rmr /hbase
3、删除元数据 zk
zkCli.sh
rmr /hbase
4、重新启动hbase
start-hbase.sh
时间同步
yum install ntp -y
ntpdate -u time.windows.com
hbase shell
| 命名 | 描述 | 语法 |
|---|---|---|
| help ‘命名名’ | 查看命令的使用描述 | help ‘命令名’ |
| whoami | 我是谁 | whoami |
| version | 返回hbase版本信息 | version |
| status | 返回hbase集群的状态信息 | status |
| table_help | 查看如何操作表 | table_help |
| create | 创建表 | create ‘表名’, ‘列族名1’, ‘列族名2’, ‘列族名N’ |
| alter | 修改列族 | 添加一个列族:alter ‘表名’, ‘列族名’ 删除列族:alter ‘表名’, {NAME=> ‘列族名’, METHOD=> ‘delete’} |
| describe | 显示表相关的详细信息 | describe ‘表名’ |
| list | 列出hbase中存在的所有表 | list |
| exists | 测试表是否存在 | exists ‘表名’ |
| put | 添加或修改的表的值 | put ‘表名’, ‘行键’, ‘列族名’, ‘列值’ put ‘表名’, ‘行键’, ‘列族名:列名’, ‘列值’ |
| scan | 通过对表的扫描来获取对用的值 | scan ‘表名’ 扫描某个列族: scan ‘表名’, {COLUMN=>‘列族名’} 扫描某个列族的某个列: scan ‘表名’, {COLUMN=>‘列族名:列名’} 查询同一个列族的多个列: scan ‘表名’, {COLUMNS => [ ‘列族名1:列名1’, ‘列族名1:列名2’, …]} |
| get | 获取行或单元(cell)的值 | get ‘表名’, ‘行键’ get ‘表名’, ‘行键’, ‘列族名’ |
| count | 统计表中行的数量 | count ‘表名’ |
| incr | 增加指定表行或列的值 | incr ‘表名’, ‘行键’, ‘列族:列名’, 步长值 |
| get_counter | 获取计数器 | get_counter ‘表名’, ‘行键’, ‘列族:列名’ |
| delete | 删除指定对象的值(可以为表,行,列对应的值,另外也可以指定时间戳的值) | 删除列族的某个列: delete ‘表名’, ‘行键’, ‘列族名:列名’ |
| deleteall | 删除指定行的所有元素值 | deleteall ‘表名’, ‘行键’ |
| truncate | 重新创建指定表 | truncate ‘表名’ |
| enable | 使表有效 | enable ‘表名’ |
| is_enabled | 是否启用 | is_enabled ‘表名’ |
| disable | 使表无效 | disable ‘表名’ |
| is_disabled | 是否无效 | is_disabled ‘表名’ |
| drop | 删除表 | drop的表必须是disable的 disable ‘表名’ drop ‘表名’ |
| shutdown | 关闭hbase集群(与exit不同) | |
| tools | 列出hbase所支持的工具 | |
| exit | 退出hbase shell |
HBase Shell 是官方提供的一组命令,用于操作HBase。如果配置了HBase的环境变量了,就可以知己在命令行中输入hbase shell 命令进入命令行。
hbase shell

在hbase中如果输入错误,按住ctrl+退格 才能删除
1、help命令
可以通过
help '命名名称'来查看命令行的具体使用,包括命令的作用和用法。
通过help ‘hbase’ 命名来查看hbase shell 支持的所有命令,hbase将命令进行分组,其中ddl、dml使用较多。
help 'list'
2、general 类
2.1显示集群状态status

2.2 查询数据库版本version

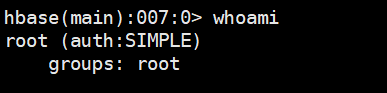
2.3显示当前用户与组 whoami
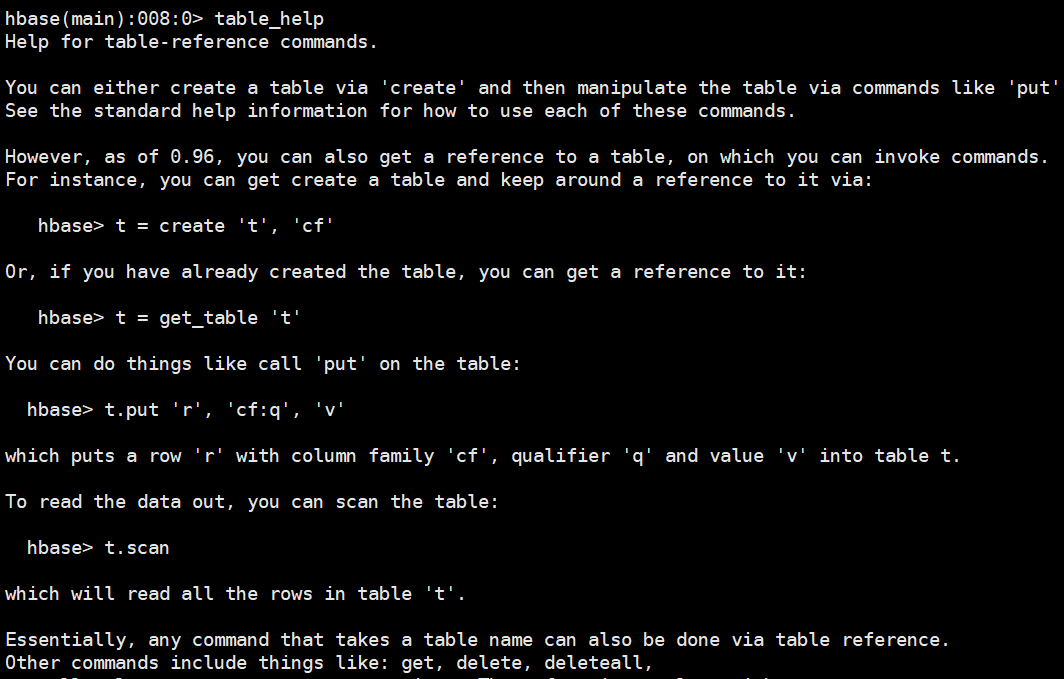
2.4查看操作表的命令table_help
2.5退出HBase Shell exit

3、DDL相关
3.1创建表create
注意:创建表时只需要指定列族名称,不需要指定列名。
# 语法
create '表名', {NAME => '列族名1'}, {NAME => '列族名2'}, {NAME => '列族名3'}
# 此种方式是上上面的简写方式,使用上面方式可以为列族指定更多的属性,如VERSIONS、TTL、BLOCKCACHE、CONFIGURATION等属性
create '表名', '列族名1', '列族名2', '列族名3'
create '表名', {NAME => '列族名1', VERSIONS => 版本号, TTL => 过期时间, BLOCKCACHE => true}
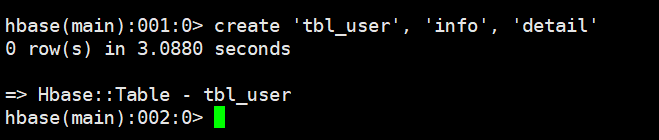
# 示例
create 'tbl_user', 'info', 'detail'
create 't1', {NAME => 'f1', VERSIONS => 1, TTL => 2592000, BLOCKCACHE => true}
3.2修改(添加、删除)表结构Schema alter
3.2.1 添加一个列簇
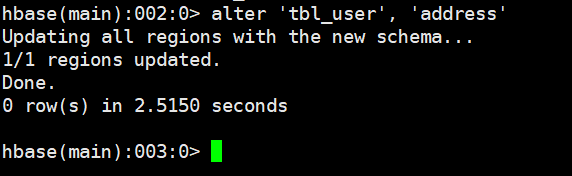
# 语法
alter '表名', '列族名'
# 示例
alter 'tbl_user', 'address'
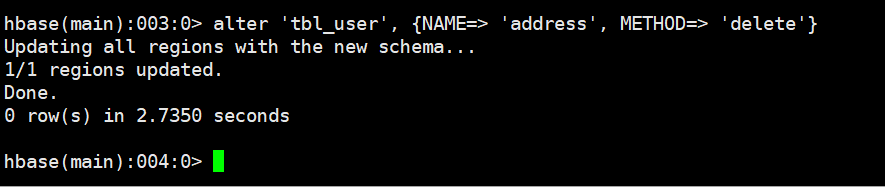
3.2.2 删除一个列簇
# 语法
alter '表名', {NAME=> '列族名', METHOD=> 'delete'}
# 示例
alter 'tbl_user', {NAME=> 'address', METHOD=> 'delete'}
3.2.3 修改列族的属性
可以修改列族的VERSIONS、IN_MEMORY
# 修改f1列族的版本为5
alter 't1', NAME => 'f1', VERSIONS => 5
# 修改多个列族,修改f2为内存,版本号为5
alter 't1', 'f1', {NAME => 'f2', IN_MEMORY => true}, {NAME => 'f3', VERSIONS => 5}
# 也可以修改table-scope属性,例如MAX_FILESIZE, READONLY,MEMSTORE_FLUSHSIZE, DEFERRED_LOG_FLUSH等。
# 例如,修改region的最大大小为128MB:
alter 't1', MAX_FILESIZE => '134217728'
3.3 获取表的描述describe
# 语法
describe '表名'
# 示例
describe 'tbl_user'

3.4 列举所有表list
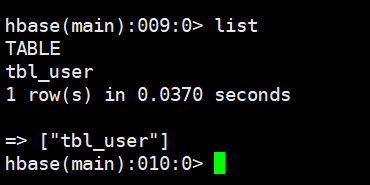
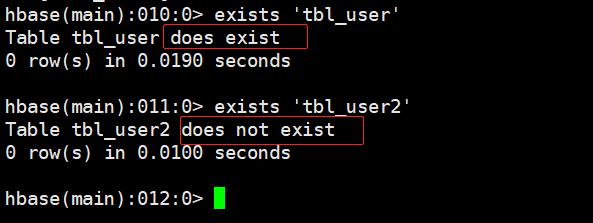
3.5 表是否存在exists
# 语法
exists '表名'
# 示例
exists 'tbl_user'
3.6 启用表enable和禁用表disable
通过enable和disable来启用/禁用这个表,相应的可以通过is_enabled和is_disabled来检查表是否被禁用。
# 语法
enable '表名'
is_enabled '表名'
disable '表名'
is_disabled '表名'
# 示例
disable 'tbl_user'
is_disabled 'tbl_user'
enable 'tbl_user'
is_enabled 'tbl_user'
3.7 禁用满足正则表达式的所有表disable_all
.匹配除“\n”和"\r"之外的任何单个字符*匹配前面的子表达式任意次
# 匹配以t开头的表名
disable_all 't.*'
# 匹配指定命名空间ns下的以t开头的所有表
disable_all 'ns:t.*'
# 匹配ns命名空间下的所有表
disable_all 'ns:.*'
3.8 启用满足正则表达式的所有表enable_all
enable_all 't.*'
enable_all 'ns:t.*'
enable_all 'ns:.*'
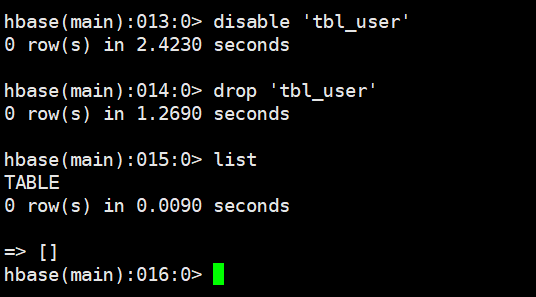
3.9 删除表drop
需要先禁用表,然后再删除表,启用的表是不允许删除的
# 语法
disable '表名'
drop '表名'
# 示例
disable 'tbl_user'
drop 'tbl_user'
直接删除报错:
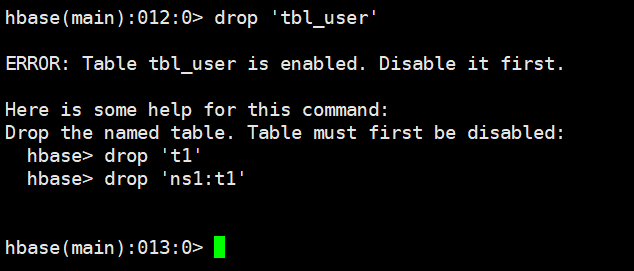
先禁用后删除
3.10 删除满足正则表达式的所有表drop_all
drop_all 't.*'
drop_all 'ns:t.*'
drop_all 'ns:.*'
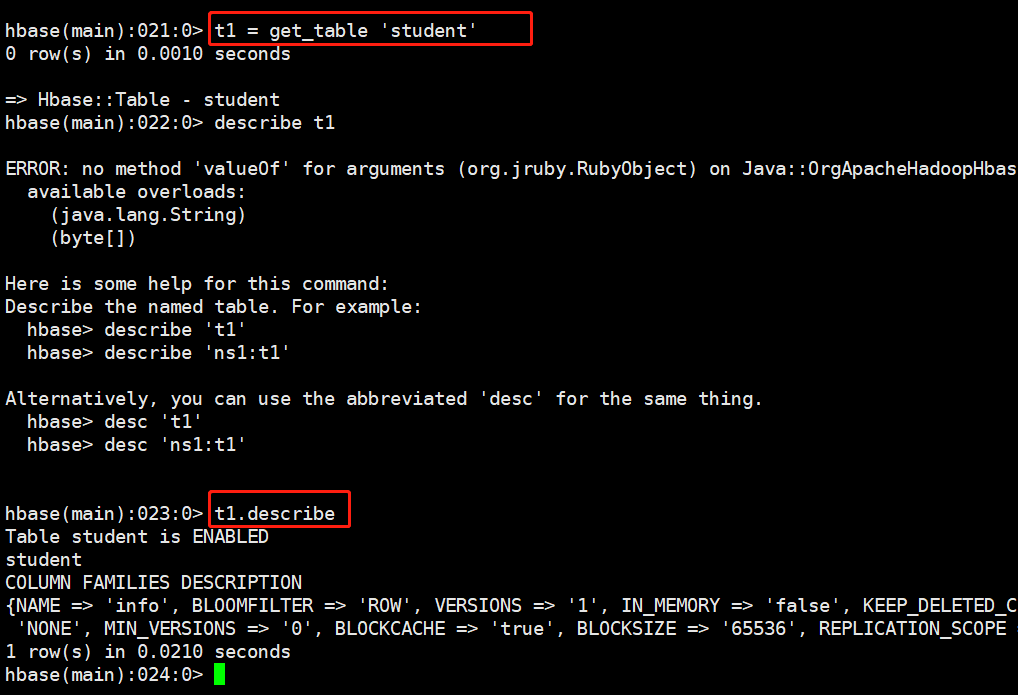
3.11 获取某个表赋值给一个变量 get_table
通过 var = get_table ‘表名’ 赋值给一个变量对象,然后对象.来调用,就像面向对象编程一样,通过对象.方法来调用,这种方式在操作某个表时就不必每次列举表名了。
3.12 获取rowKey所在的区 locate_region
locate_region '表名', '行键'
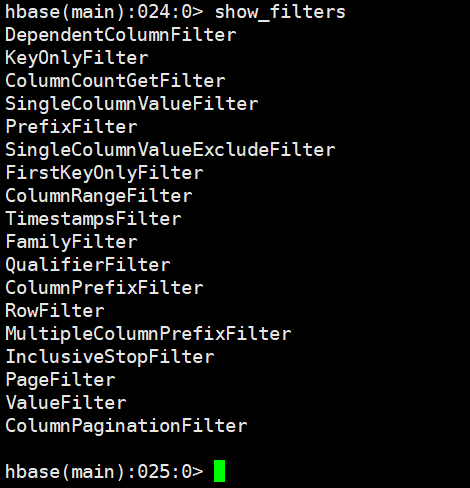
3.13 显示hbase所支持的所有过滤器show_filters
过滤器用于get和scan命令中作为筛选数据的条件,类型关系型数据库中的where的作用
4、 namespace
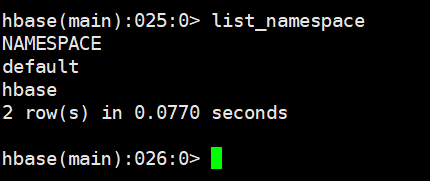
hbase中没有数据库的概念 , 可以使用namespace来达到数据库分类别管理表的作用
4.1 列举命名空间 list_namespace
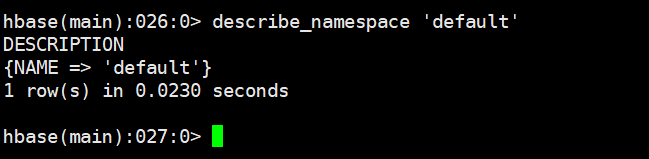
4.2 获取命名空间描述 describe_namespace
describe_namespace 'default'
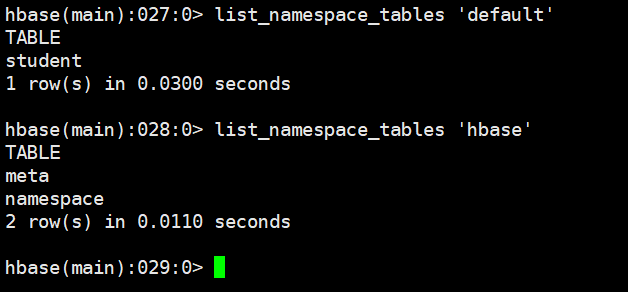
4.3 查看命名空间下的所有表 list_namespace_tables
list_namespace_tables 'default'
list_namespace_tables 'hbase'
4.4 创建命名空间create_namespace
create_namespace 'bigdata17'
4.5 删除命名空间drop_namespace
drop_namespace '命名空间名称'
5、DML
5.1 插入或者修改数据put

# 语法
# 当列族中只有一个列时'列族名:列名'使用'列族名'
put '表名', '行键', '列族名', '列值'
put '表名', '行键', '列族名:列名', '列值'
# 示例
# 创建表
create 'users', 'info', 'detail', 'address'
# 第一行数据
put 'users', 'rk1001', 'info:id', '1'
put 'users', 'rk1001', 'info:name', '张三'
put 'users', 'rk1001', 'info:age', '28'
put 'users', 'rk1001', 'detail:birthday', '1990-06-26'
put 'users', 'rk1001', 'detail:email', 'abc@163.com'
put 'users', 'rk1001', 'detail:create_time', '2019-03-04 14:26:10'
put 'users', 'rk1001', 'address', '上海市'
# 第二行数据
put 'users', 'rk1002', 'info:id', '2'
put 'users', 'rk1002', 'info:name', '李四'
put 'users', 'rk1002', 'info:age', '27'
put 'users', 'rk1002', 'detail:birthday', '1990-06-27'
put 'users', 'rk1002', 'detail:email', 'xxx@gmail.com'
put 'users', 'rk1002', 'detail:create_time', '2019-03-05 14:26:10'
put 'users', 'rk1002', 'address', '北京市'
# 第三行数据
put 'users', 'rk1003', 'info:id', '3'
put 'users', 'rk1003', 'info:name', '王五'
put 'users', 'rk1003', 'info:age', '26'
put 'users', 'rk1003', 'detail:birthday', '1990-06-28'
put 'users', 'rk1003', 'detail:email', 'xyz@qq.com'
put 'users', 'rk1003', 'detail:create_time', '2019-03-06 14:26:10'
put 'users', 'rk1003', 'address', '杭州市'
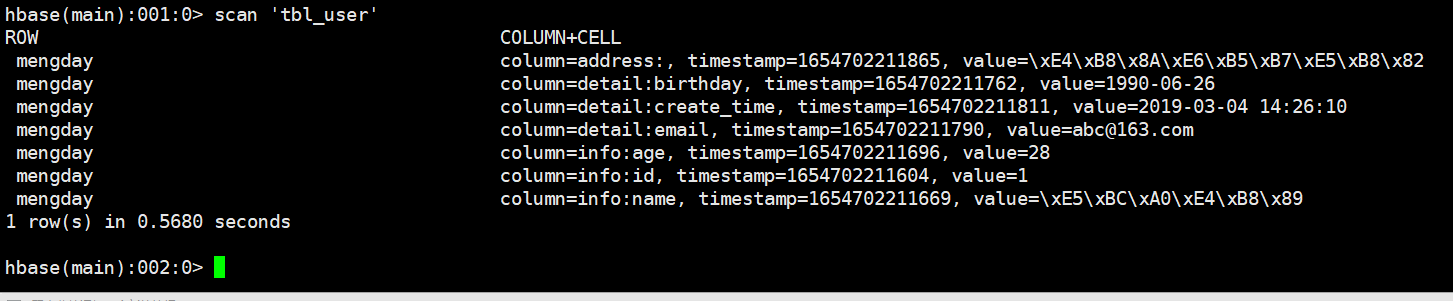
5.2 全表扫描scan
# 语法
scan '表名'
# 示例
scan 'users'
扫描整个列簇
# 语法
scan '表名', {COLUMN=>'列族名'}
# 示例
scan 'users', {COLUMN=>'info'}
扫描整个列簇的某个列
# 语法
scan '表名', {COLUMN=>'列族名:列名'}
# 示例
scan 'users', {COLUMN=>'info:age'}
5.3 获取数据get
# 语法
get '表名', '行键'
# 示例
get 'users', 'xiaoming'
根据某一行某列族的数据
# 语法
get '表名', '行键', '列族名'
# 示例
get 'users', 'xiaoming', 'info'
# 创建表,c1版本为4, 元数据mykey=myvalue
hbase(main):009:0> create 't1', {NAME => 'c1', VERSIONS => 4}, METADATA => { 'mykey' => 'myvalue' }
0 row(s) in 2.2810 seconds
=> Hbase::Table - t1
# 添加列族c2, c3
hbase(main):010:0> alter 't1', 'c2', 'c3'
Updating all regions with the new schema...
1/1 regions updated.
Done.
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 3.8320 seconds
# 出入数据,c1 插入4个版本的值
hbase(main):011:0> put 't1', 'r1', 'c1', 'v1'
0 row(s) in 0.1000 seconds
hbase(main):012:0> put 't1', 'r1', 'c1', 'v11'
0 row(s) in 0.0180 seconds
hbase(main):013:0> put 't1', 'r1', 'c1', 'v111'
0 row(s) in 0.0140 seconds
hbase(main):014:0> put 't1', 'r1', 'c1', 'v1111'
0 row(s) in 0.0140 seconds
# 插入c2、c3的值
hbase(main):015:0> put 't1', 'r1', 'c2', 'v2'
0 row(s) in 0.0140 seconds
hbase(main):016:0> put 't1', 'r1', 'c3', 'v3'
0 row(s) in 0.0210 seconds
# 获取rowKey=r1的一行记录
hbase(main):017:0> get 't1', 'r1'
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
c2: timestamp=1552819392398, value=v2
c3: timestamp=1552819398244, value=v3
3 row(s) in 0.0550 seconds
# 获取rowKey=r1并且 1552819392398 <= 时间戳范围 < 1552819398244
hbase(main):018:0> get 't1', 'r1', {TIMERANGE => [1552819392398, 1552819398244]}
COLUMN CELL
c2: timestamp=1552819392398, value=v2
1 row(s) in 0.0090 seconds
# 获取指定列的值
hbase(main):019:0> get 't1', 'r1', {COLUMN => 'c1'}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
1 row(s) in 0.0160 seconds
# 获取指定列的值,多个值使用数组表示
hbase(main):020:0> get 't1', 'r1', {COLUMN => ['c1', 'c2', 'c3']}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
c2: timestamp=1552819392398, value=v2
c3: timestamp=1552819398244, value=v3
3 row(s) in 0.0170 seconds
# 获取c1的值,获取4个版本的值,默认是按照时间戳降续排序的
hbase(main):021:0> get 't1', 'r1', {COLUMN => 'c1', VERSIONS => 4}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
c1: timestamp=1552819376343, value=v111
c1: timestamp=1552819368993, value=v11
c1: timestamp=1552819362975, value=v1
4 row(s) in 0.0180 seconds
# 获取c1的3个版本值
hbase(main):027:0* get 't1', 'r1', {COLUMN => 'c1', VERSIONS => 3}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
c1: timestamp=1552819376343, value=v111
c1: timestamp=1552819368993, value=v11
3 row(s) in 0.0090 seconds
# 获取指定时间戳版本的列
hbase(main):022:0> get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => 1552819376343}
COLUMN CELL
c1: timestamp=1552819376343, value=v111
1 row(s) in 0.0170 seconds
hbase(main):023:0> get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => 1552819376343, VERSIONS => 4}
COLUMN CELL
c1: timestamp=1552819376343, value=v111
1 row(s) in 0.0130 seconds
# 获取rowKey=r1中的值等于v2的所有列
hbase(main):024:0> get 't1', 'r1', {FILTER => "ValueFilter(=, 'binary:v2')"}
COLUMN CELL
c2: timestamp=1552819392398, value=v2
1 row(s) in 0.0510 seconds
hbase(main):025:0> get 't1', 'r1', {COLUMN => 'c1', ATTRIBUTES => {'mykey'=>'myvalue'}}
COLUMN CELL
c1: timestamp=1552819382575, value=v1111
1 row(s) in 0.0100 seconds
5.4 删除某个列族中的某个列delete
# 语法
delete '表名', '行键', '列族名:列名'
delete 'users','xiaoming','info:age'
create 'tbl_test', 'columnFamily1'
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value1'
put 'tbl_test', 'rowKey1', 'columnFamily1:column2', 'value2'
delete 'tbl_test', 'rowKey1', 'columnFamily1:column1'
5.5 删除某行数据deleteall
# 语法
deleteall '表名', '行键'
# 示例
deleteall 'users', 'xiaoming'
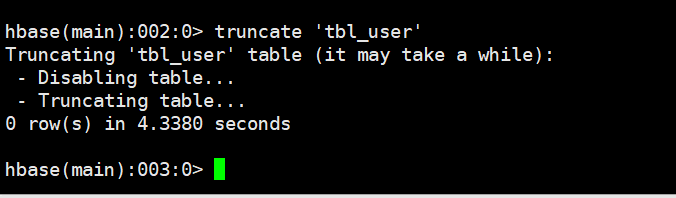
5.6 清空整个表的数据truncate
先disable表,然后再drop表,最后重新create表
truncate '表名'
5.7 自增incr
# 语法
incr '表名', '行键', '列族:列名', 步长值
# 示例
# 注意:incr 可以对不存的行键操作,如果行键已经存在会报错,如果使用put修改了incr的值再使用incr也会报错
# ERROR: org.apache.hadoop.hbase.DoNotRetryIOException: Field is not a long, it's 2 bytes wide
incr 'tbl_user', 'xiaohong', 'info:age', 1
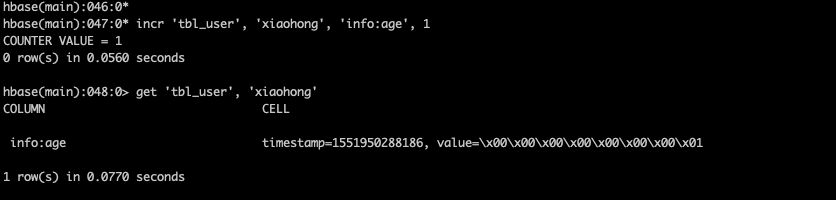
5.8 计数器get_counter
# 点击量:日、周、月
create 'counters', 'daily', 'weekly', 'monthly'
incr 'counters', '20110101', 'daily:hits', 1
incr 'counters', '20110101', 'daily:hits', 1
get_counter 'counters', '20110101', 'daily:hits'
5.9 修饰词
1、修饰词
# 语法
scan '表名', {COLUMNS => [ '列族名1:列名1', '列族名1:列名2', ...]}
# 示例
scan 'tbl_user', {COLUMNS => [ 'info:id', 'info:age']}
2、TIMESTAMP 指定时间戳
# 语法
scan '表名',{TIMERANGE=>[timestamp1, timestamp2]}
# 示例
scan 'tbl_user',{TIMERANGE=>[1551938004321, 1551938036450]}
3、VERSIONS
默认情况下一个列只能存储一个数据,后面如果修改数据就会将原来的覆盖掉,可以通过指定VERSIONS时HBase一列能存储多个值。
create 'tbl_test', 'columnFamily1'
describe 'tbl_test'
# 修改列族版本号
alter 'tbl_test', { NAME=>'columnFamily1', VERSIONS=>3 }
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value1'
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value2'
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value3'
# 默认返回最新的一条数据
get 'tbl_test','rowKey1','columnFamily1:column1'
# 返回3个
get 'tbl_test','rowKey1',{COLUMN=>'columnFamily1:column1', VERSIONS=>3}
# 返回2个
get 'tbl_test','rowKey1',{COLUMN=>'columnFamily1:column1', VERSIONS=>2}
4、STARTROW
ROWKEY起始行。会先根据这个key定位到region,再向后扫描
# 语法
scan '表名', { STARTROW => '行键名'}
# 示例
scan 'tbl_user', { STARTROW => 'vbirdbest'}
5、STOPROW :截止到STOPROW行,STOPROW行之前的数据,不包括STOPROW这行数据
# 语法
scan '表名', { STOPROW => '行键名'}
# 示例
scan 'tbl_user', { STOPROW => 'xiaoming'}
6、LIMIT 返回的行数
# 语法
scan '表名', { LIMIT => 行数}
# 示例
scan 'tbl_user', { LIMIT => 2 }
5.10 FILTER条件过滤器
过滤器之间可以使用AND、OR连接多个过滤器。
1、ValueFilter 值过滤器
# 语法:binary 等于某个值
scan '表名', FILTER=>"ValueFilter(=,'binary:列值')"
# 语法 substring:包含某个值
scan '表名', FILTER=>"ValueFilter(=,'substring:列值')"
# 示例
scan 'tbl_user', FILTER=>"ValueFilter(=, 'binary:26')"
scan 'tbl_user', FILTER=>"ValueFilter(=, 'substring:6')"
2、ColumnPrefixFilter 列名前缀过滤器
# 语法 substring:包含某个值
scan '表名', FILTER=>"ColumnPrefixFilter('列名前缀')"
# 示例
scan 'tbl_user', FILTER=>"ColumnPrefixFilter('birth')"
# 通过括号、AND和OR的条件组合多个过滤器
scan 'tbl_user', FILTER=>"ColumnPrefixFilter('birth') AND ValueFilter(=,'substring:26')"
3、rowKey字典排序
Table中的所有行都是按照row key的字典排序的
HBase1.4.6安装搭建及shell命令使用的更多相关文章
- 最新版windows安装支持输入shell命令的工具cygwin教程
首先去官网下载自己对应系统32位或64位系统版本安装包:https://cygwin.com/install.html 下载好后按提示一步一步安装,直到这一步: 初次安装,这里是空的,没有下载的镜像链 ...
- hadoop学习第七天-HBase的原理、安装、shell命令
一. hbase的原理知识 1. hbase介绍 hbase是hadoop的一个重要成员,主要用于存储结构化数据,构建在hdfs之上的分布式存储系统,它主要通过横向扩展,通用不断增加廉价服务器增加计算 ...
- 快速掌握mongoDB(一)——mongoDB安装部署和常用shell命令
1.mongoDB简介 mongoDB 是由C++语言编写的,是一种分布式的面向文档存储的开源nosql数据库.nosql是Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统 ...
- mongoDB(一)——mongoDB安装部署和常用shell命令
1.mongoDB简介 mongoDB 是由C++语言编写的,是一种分布式的面向文档存储的开源nosql数据库.nosql是Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统 ...
- HBase 安装与配置及常用Shell命令
HBase 安装与配置 首要配置 配置时间同步(所有节点上执行) yum -y install chrony vi /etc/chrony.conf #写入(7版本用server:8版本用pool): ...
- Android成长记(1)-----android环境搭建与adb shell 命令
整理一下学习android一步一步存下来的自己总结或是从网上摘抄的比较不错的文档,电脑要上交了,最舍不得的就是自己积累的这么点东西了,所以决定发布到黎梓小站,以供大家一起学习以及自己日后忘记了也有地方 ...
- 版本控制-svn服务器搭建和常用命令(centos 6.3)
Svn是比较优秀的版本控制工具,虽然功能和性能上无法和Git媲美,但由于其容易搭建和使用的特性,所以在各个小公司还是很受欢迎的.使用Git可参考<版本控制-Git服务器搭建和常用命令使用> ...
- 版本控制-Git服务器搭建和常用命令使用
Git是目前世界上最先进的分布式版本控制系统(没有之一).使用Svn的请参考<版本控制-svn服务器搭建和常用命令(centos 6.3)>,下面介绍Git的常用命令 常用命令 简单版 升 ...
- HBase shell 命令介绍
HBase shell是HBase的一套命令行工具,类似传统数据中的sql概念,可以使用shell命令来查询HBase中数据的详细情况.安装完HBase之后,如果配置了HBase的环境变量,只要在sh ...
随机推荐
- 温控器/胎压检测/电表/热泵显示控制器等,低功耗高抗干扰断/段码(字段式)LCD液晶显示驱动IC-VK2C22A/B,替代市面16C22,44*4/40*4点显示
产品品牌:永嘉微电/VINKA 产品型号:VK2C22A/B 封装形式:LQFP52/48 产品年份:新年份 概述: VK2C22是一个点阵式存储映射的LCD驱动器,可支持最大176点(44SEGx4 ...
- SpringBoot整合Redis实现常用功能
SpringBoot整合Redis实现常用功能 建议大小伙们,在写业务的时候,提前画好流程图,思路会清晰很多. 文末有解决缓存穿透和击穿的通用工具类. 1 登陆功能 我想,登陆功能是每个项目必备的功能 ...
- rh358 001 Linux网络与systemd设置
358 rhel7 ce ansible 部署服务 dhcp nginx vanish haproxy 打印机服务 服务管理自动化 systemd与systemctl systemctl 来管理sys ...
- Java使用定时任务详解
定时任务 目录 定时任务 SpringBoot定时任务 默认单线程 使用异步多线程 Spring定时任务XML配置(注解形式几乎同上) 使用springTask: ----springTask为spr ...
- iOS 苹果集成登录及苹果图标的制作要求
前言 如果要上架的应用集成了三方登录,那么在审核时,苹果会强制要求应用也要集成苹果登录.如果应用没有集成一般情况下都会被审核团队给打回来. 苹果集成登录 首先,你需要在开发者中心,找到你的应用,勾选上 ...
- 【AGC】使用云调试优惠扣费、华为设备上触发崩溃、无法下载华为应用市场问题小结
1.使用云调试剩余优惠时长还剩300分钟,但还会扣费的情况. 问题描述:用户的云调试账户显示剩余优惠时长还有300分钟,但在使用云调试的过程中,还是产生了扣费的情况. 解决方案: 当开发者成功 ...
- KingbaseES 自增列三种方式
KingbaseES中3种自增长类型sequence,serial,identity的区别: 对象 显示插入 显示插入后更新最大值 清空表后是否重置 是否跟事务一起回滚 多对象共享 支持重置 出现错误 ...
- cnblogs-theme-blogure
cnblogs-theme-blogure 又一个博客园主题 Blogure. 它使用 PetiteVue 和 PicoCSS. 喜欢的话可以帮个点 Star 么? 快速开始 确保博客园有 JS 权限 ...
- C语言的几个入门关于函数调用练习
1.找素数(素数:除了1和本身之外不能被任何整数整除的的数)(被某数整除=除以某数是整数) 问题:输出2到200(包括2和200)的使有素数,从小到大排序. 思路:检查所有比i小的数,取余. 涉及的知 ...
- 04-MyBatisPlus条件构造器
一.wapper介绍 Wrapper : 条件构造抽象类,最顶端父类 AbstractWrapper : 用于查询条件封装,生成 sql 的 where 条件 QueryWrapper : Entit ...