MIT6.824 Distributed-System(Lab1)-MapReduce
Lab address: http://nil.csail.mit.edu/6.824/2020/labs/lab-mr.html
paper: MapReduce: Simplified Data Processing on Large Clusters
Job: Your job is to implement a distributed MapReduce, consisting of two programs, the master and the worker. There will be just one master process, and one or more worker processes executing in parallel. In a real system the workers would run on a bunch of different machines, but for this lab you'll run them all on a single machine. The workers will talk to the master via RPC. Each worker process will ask the master for a task, read the task's input from one or more files, execute the task, and write the task's output to one or more files. The master should notice if a worker hasn't completed its task in a reasonable amount of time (for this lab, use ten seconds), and give the same task to a different worker.
简而言之,就是要构建一个MapReduce系统
What is MapReduce?
那么什么是MapReduce?且看论文描述:
MapReduce is a programming model and an associated implementation for processing and generating large data sets.
MapReduce是一个编程模型,是一个用于处理和生成大型数据集的相关实现
那么它是用来干什么的?
Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key.
用户指定一个map(映射)函数和一个reduce(归约)函数,前者用于生成一个一系列中间键值对,后者用于归并所有的与中间键相关联的中间值
The computation takes a set of input key/value pairs, and produces a set of output key/value pairs.
这个程序的输入是一系列的键值对,输出也是一系列键值对
那么基于此,将MapReduce划分为一个Map和一个Reduce,编程模型是怎样的?
Map, written by the user, takes an input pair and produces a set of intermediate key/value pairs. The MapReduce library groups together all intermediate values associated with the same intermediate key I and passes them to the Reduce function.
Map是用户自定义的,将一个输入的键值对映射为一系列键值对的集合,MapReduce 库将与同一中间键 I 关联的所有中间值组合在一起,并将它们传递给 Reduce 函数
The Reduce function, also written by the user, accepts an intermediate key I and a set of values for that key. It merges together these values to form a possibly smaller set of values. Typically just zero or one output value is produced per Reduce invocation. The intermediate values are supplied to the user’s reduce function via an iterator. This allows us to handle lists of values that are too large to fit in memory.
Reduce函数同样是用户自定义的,接收一个中间键I及其一组值,将它们合并在一起形成一组可能更小的值,通常每次Reduce调用只有0或1个输出值,中间值通过迭代器提供给用户的 reduce 函数。 这使我们能够处理太大而无法放入内存的值列表
Execution Overview
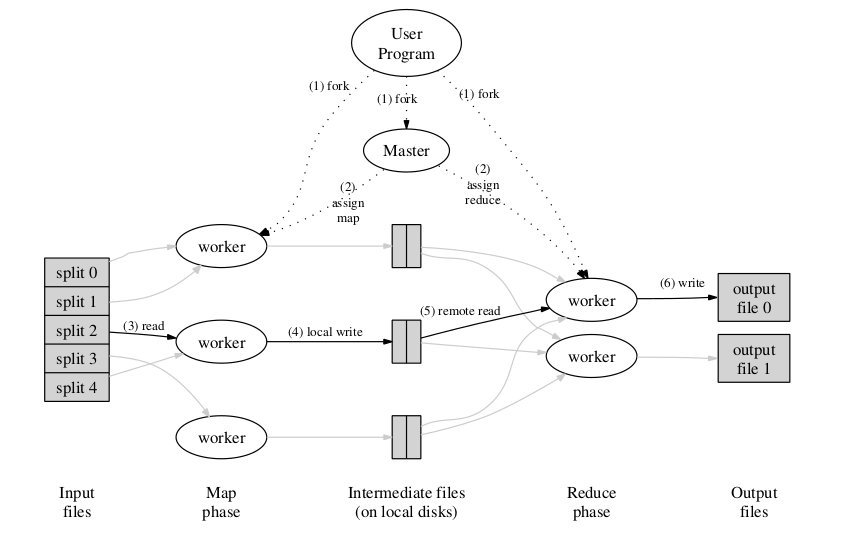
The Map invocations are distributed across multiple machines by automatically partitioning the input data into a set of M splits.The input splits can be processed in parallel by different machines. Reduce invocations are distributed by partitioning the intermediate key space into R pieces using a partitioning function (e.g,hash(key) mod R). The number of partitions (R) and the partitioning function are specified by the user.
通过将输入数据自动划分为M片,Map调用被分布在多台机器上,输入的多个分片能够被不同的机器不行处理
通过使用划分函数将中间键的空间划分为R片,来分布Reduce函数,R和划分函数有用户指定
The MapReduce library in the user program first splits the input files into M pieces of typically 16 megabytes to 64 megabytes (MB) per piece (controllable by the user via an optional parameter). It then starts up many copies of the program on a cluster of machines.
用户程序中的MapReduce库将输入的文件划分为M个片段,通常每片为16MB到64MB,可由用户控制。之后它在集群上启动诸多副本
One of the copies of the program is special – the master. The rest are workers that are assigned work by the master. There are M map tasks and R reduce tasks to assign. The master picks idle workers and assigns each one a map task or a reduce task.
该程序有一份拷贝是特殊的,那就是Master,剩下的是被Master分配工作的Worker。有M个Map任务和R个Reduce任务要分配,Master会选择空闲的Woker分配任务,每一个Worker分配一个Map任务或者一个Reduce任务
A worker who is assigned a map task reads the contents of the corresponding input split. It parses key/value pairs out of the input data and passes each pair to the user-defined Map function. The intermediate key/value pairs produced by the Map function are buffered in memory.
一个被分配map任务的Worker会读取对应输入片段的内容,从输入数据中解析出键值对,并传给用户定义的Map函数。Map函数产生的键值对被缓存在内存中
Periodically, the buffered pairs are written to local disk, partitioned into R regions by the partitioning function. The locations of these buffered pairs on the local disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.
缓存的键值对会被定期写入被划分为R个分区的本地磁盘,并且传给用户定义的Map函数,这些缓存的键值对的位置被传回给Master,Master再负责将这些位置转发给Reduce worker
When a reduce worker is notified by the master about these locations, it uses remote procedure calls to read the buffered data from the local disks of the map workers. When a reduce worker has read all intermediate data, it sorts it by the intermediate keys so that all occurrences of the same key are grouped together. The sorting is needed because typically many different keys map to the same reduce task. If the amount of intermediate data is too large to fit in memory, an external sort is used.
当一个reduce worker被master通知这些位置,将使用远程过程调用来从map worker的本地磁盘中读取这些缓存数据。当一个reduce worker读完了所有的中间数据,它会按中间键对其进行排序,以至于所有的相同的键都排放在一起。之所以需要排序,是因为通常许多不同的键映射到同一个 reduce 任务。 如果中间数据量太大而无法放入内存,则使用外部排序
The reduce worker iterates over the sorted intermediate data and for each unique intermediate key encountered, it passes the key and the corresponding set of intermediate values to the user’s Reduce function. The output of the Reduce function is appended to a final output file for this reduce partition.
reduce worker迭代这些排序好的中间数据并且,对于遇到的每一个中间键,将和键相对应的key和中间值集合传给reduce函数,这些reduce函数的输出被追加到此reduce分区的最终输出文件中
Example
MIT在github中给出了示例代码,对MapReduce简单的实现
如下是src/main/mrsequential.go
package main
// for sorting by key.
type ByKey []mr.KeyValue
// for sorting by key.
func (a ByKey) Len() int { return len(a) }
func (a ByKey) Swap(i, j int) { a[i], a[j] = a[j], a[i] }
func (a ByKey) Less(i, j int) bool { return a[i].Key < a[j].Key }
func main() {
if len(os.Args) < 3 {
fmt.Fprintf(os.Stderr, "Usage: mrsequential xxx.so inputfiles...\n")
os.Exit(1)
}
mapf, reducef := loadPlugin(os.Args[1])
//
// read each input file,
// pass it to Map,
// accumulate the intermediate Map output.
//
intermediate := []mr.KeyValue{}
for _, filename := range os.Args[2:] {
file, err := os.Open(filename)
if err != nil {
log.Fatalf("cannot open %v", filename)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("cannot read %v", filename)
}
file.Close()
kva := mapf(filename, string(content))
intermediate = append(intermediate, kva...)
}
//
// a big difference from real MapReduce is that all the
// intermediate data is in one place, intermediate[],
// rather than being partitioned into NxM buckets.
//
sort.Sort(ByKey(intermediate))
oname := "mr-out-0"
ofile, _ := os.Create(oname)
//
// call Reduce on each distinct key in intermediate[],
// and print the result to mr-out-0.
//
i := 0
for i < len(intermediate) {
j := i + 1
for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {
j++
}
values := []string{}
for k := i; k < j; k++ {
values = append(values, intermediate[k].Value)
}
output := reducef(intermediate[i].Key, values)
// this is the correct format for each line of Reduce output.
fmt.Fprintf(ofile, "%v %v\n", intermediate[i].Key, output)
i = j
}
ofile.Close()
}
//
// load the application Map and Reduce functions
// from a plugin file, e.g. ../mrapps/wc.so
//
func loadPlugin(filename string) (func(string, string) []mr.KeyValue, func(string, []string) string) {
p, err := plugin.Open(filename)
if err != nil {
log.Fatalf("cannot load plugin %v", filename)
}
xmapf, err := p.Lookup("Map")
if err != nil {
log.Fatalf("cannot find Map in %v", filename)
}
mapf := xmapf.(func(string, string) []mr.KeyValue)
xreducef, err := p.Lookup("Reduce")
if err != nil {
log.Fatalf("cannot find Reduce in %v", filename)
}
reducef := xreducef.(func(string, []string) string)
return mapf, reducef
}
该程序实现了一个简单的MapReduce
loadPlugin返回一个map function和reduce function,这里用到了plugin包,在.so文件中通过符号来获取函数,同时用上了断言
这两个函数的实现在wc.go中:
func Map(filename string, contents string) []mr.KeyValue {
// function to detect word separators.
ff := func(r rune) bool { return !unicode.IsLetter(r) }
// split contents into an array of words.
words := strings.FieldsFunc(contents, ff)
kva := []mr.KeyValue{}
for _, w := range words {
kv := mr.KeyValue{w, "1"}
kva = append(kva, kv)
}
return kva
}
//
// The reduce function is called once for each key generated by the
// map tasks, with a list of all the values created for that key by
// any map task.
//
func Reduce(key string, values []string) string {
// return the number of occurrences of this word.
return strconv.Itoa(len(values))
}
Map函数的作用是映射(如上文所述),读取文本中的所有字母,对于每一个单词都建立一个键值对,例如扫描到cat,则建立一个{cat,1}放到集合中
Reduce函数返回字符串类型的集合大小
那么回到mrsequential.go中,该程序读入所有文件,将其内容传入map进行映射,生成了一系列的键值对
之后对键值对集合进行排序,之后将所有key相同的值组成一个集合,使用Reduce得到集合的大小,并和key一起输出,这样就得到了词数
那么MapReduce的工作就完成了
这段代码整合起来大概如下:
package main
import (
"fmt"
"io/ioutil"
"log"
"os"
"sort"
"strconv"
"strings"
"unicode"
)
type Pair struct {
Key string
Value string
}
type ByKey []Pair
func (a ByKey) Len() int { return len(a) }
func (a ByKey) Swap(i, j int) { a[i], a[j] = a[j], a[i] }
func (a ByKey) Less(i, j int) bool { return a[i].Key < a[j].Key }
func main() {
if len(os.Args) < 2 {
fmt.Printf("input files")
os.Exit(1)
}
var intermediate []Pair
for _, filename := range os.Args[2:] {
file, err := os.Open(filename)
if err != nil {
log.Fatalf("cannot open %v", filename)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("cannot read %v", filename)
}
file.Close()
kva := Map(filename, string(content))
intermediate = append(intermediate, kva...)
}
sort.Sort(ByKey(intermediate))
oname := "output"
ofile, _ := os.Create(oname)
i := 0
for i < len(intermediate) {
j := i + 1
for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {
j++
}
var values []string
for k := i; k < j; k++ {
values = append(values, intermediate[k].Value)
}
output := Reduce(intermediate[i].Key, values)
fmt.Fprintf(ofile, "%v %v\n", intermediate[i].Key, output)
i = j
}
ofile.Close()
}
func Map(filename string, contents string) []Pair {
f := func(r rune) bool {
return !unicode.IsLetter(r)
}
words := strings.FieldsFunc(contents, f)
var kva []Pair
for _, w := range words {
kv := Pair{w, "1"}
kva = append(kva, kv)
}
return kva
}
func Reduce(key string, values []string) string {
return strconv.Itoa(len(values))
}
输入文件:
$ ls -l files
total 3236
-rw-rw-r-- 1 hwx hwx 138885 Sep 16 19:38 pg-being_ernest.txt
-rw-rw-r-- 1 hwx hwx 453168 Sep 16 19:38 pg-dorian_gray.txt
-rw-rw-r-- 1 hwx hwx 441033 Sep 16 19:38 pg-frankenstein.txt
-rw-rw-r-- 1 hwx hwx 540174 Sep 16 19:38 pg-grimm.txt
-rw-rw-r-- 1 hwx hwx 594262 Sep 16 19:38 pg-huckleberry_finn.txt
-rw-rw-r-- 1 hwx hwx 139054 Sep 16 19:38 pg-metamorphosis.txt
-rw-rw-r-- 1 hwx hwx 581863 Sep 16 19:38 pg-sherlock_holmes.txt
-rw-rw-r-- 1 hwx hwx 412665 Sep 16 19:38 pg-tom_sawyer.txt
执行命令:
$ go run main.go files/pg*.txt
结果被保存在output中:
A 477
ABOUT 2
ACTRESS 1
ACTUAL 7
ADLER 1
ADVENTURE 12
ADVENTURES 7
AFTER 2
AGREE 14
....
Job
这里要借助Go语言的RPC package,简单演示用法,构建一个RPC服务器
服务端代码:
package server
import (
"errors"
)
type Args struct {
A, B int
}
type Quotient struct {
Quo, Rem int
}
type Arith int
func (t *Arith) Multiply(args Args, reply *int) error {
*reply = args.A * args.B
return nil
}
func (t *Arith) Divide(args *Args, quo *Quotient) error {
if args.B == 0 {
return errors.New("divide by zero")
}
quo.Quo = args.A / args.B
quo.Rem = args.A % args.B
return nil
}
入口函数:
package main
import (
"log"
"net"
"net/http"
"net/rpc"
"rpcserver/server"
)
func main() {
arith := new(server.Arith)
err := rpc.Register(arith)
if err != nil {
panic(err)
}
rpc.HandleHTTP()
listen, err := net.Listen("tcp", ":9090")
if err != nil {
log.Fatal("listen error:", err)
}
go http.Serve(listen, nil)
select {}
}
客户端代码:
package main
import (
"fmt"
"log"
"net/rpc"
"rpcserver/server"
)
const serverAddress = "127.0.0.1"
func main() {
client, err := rpc.DialHTTP("tcp", serverAddress+":9090")
if err != nil {
log.Fatal("dialing:", err)
}
args := &server.Args{A: 7, B: 8}
var reply int
err = client.Call("Arith.Multiply", args, &reply) // 调用方法
if err != nil {
log.Fatal("arith error:", err)
}
fmt.Printf("Arith: %d*%d=%d\n", args.A, args.B, reply)
}
运行:
$ go run client.go
Arith: 7*8=56
现在来看看给出的任务
Your job is to implement a distributed MapReduce, consisting of two programs, the master and the worker. There will be just one master process, and one or more worker processes executing in parallel. In a real system the workers would run on a bunch of different machines, but for this lab you'll run them all on a single machine. The workers will talk to the master via RPC. Each worker process will ask the master for a task, read the task's input from one or more files, execute the task, and write the task's output to one or more files. The master should notice if a worker hasn't completed its task in a reasonable amount of time (for this lab, use ten seconds), and give the same task to a different worker.
这里要实现一个master和多个worker,它们是并行运行的,worker将通过RPC与master交流,向master索取任务,从多个文件中读取任务的输入。master要关注worker是否按时完成任务,如果超时了就重新分配任务
MIT6.824 Distributed-System(Lab1)-MapReduce的更多相关文章
- 【MIT-6.824】Lab 1: MapReduce
Lab 1链接:https://pdos.csail.mit.edu/6.824/labs/lab-1.html Part I: Map/Reduce input and output Part I需 ...
- MIT 6.824(Spring 2020) Lab1: MapReduce 文档翻译
首发于公众号:努力学习的阿新 前言 大家好,这里是阿新. MIT 6.824 是麻省理工大学开设的一门关于分布式系统的明星课程,共包含四个配套实验,实验的含金量很高,十分适合作为校招生的项目经历,在文 ...
- MIT6.824食用过程
MIT6.824食用过程 Lab1 MapReduce 一.介绍 本实验使用Go语言构建一个mapreduce库,以及一个容错的分布式系统.第一部分完成一个简单的mapreduce程序,第二部分写一个 ...
- 分布式系统(Distributed System)资料
这个资料关于分布式系统资料,作者写的太好了.拿过来以备用 网址:https://github.com/ty4z2008/Qix/blob/master/ds.md 希望转载的朋友,你可以不用联系我.但 ...
- Mit6.824 Lab1-MapReduce
前言 Mit6.824 是我在学习一些分布式系统方面的知识的时候偶然看到的,然后就开始尝试跟课.不得不说,国外的课程难度是真的大,一周的时间居然要学一门 Go 语言,然后还要读论文,进而做MapRed ...
- MIT 6.824 : Spring 2015 lab1 训练笔记
源代码参见我的github: https://github.com/YaoZengzeng/MIT-6.824 Part I: Word count MapReduce操作实际上就是将一个输入文件拆分 ...
- 译《Time, Clocks, and the Ordering of Events in a Distributed System》
Motivation <Time, Clocks, and the Ordering of Events in a Distributed System>大概是在分布式领域被引用的最多的一 ...
- Aysnc-callback with future in distributed system
Aysnc-callback with future in distributed system
- Note: Time clocks and the ordering of events in a distributed system
http://research.microsoft.com/en-us/um/people/lamport/pubs/time-clocks.pdf 分布式系统的时钟同步是一个非常困难的问题,this ...
- MIT6.824 分布式系统实验
LAB1 mapreduce mapreduce中包含了两个角色,coordinator和worker,其中,前者掌管任务的分发和回收,后者执行任务.mapreduce分为两个阶段,map阶段和red ...
随机推荐
- heimaJava-网络编程
Java 网络编程 概念 网络编程可以让程序与网络上的其他设备中的程序进行数据交互 网络通信基本模式 常见的通信模式有如下两种形式,Client-Server(CS),Browser/Server(B ...
- QT网络编程【一】
1.QUdpSocket头文件无法识别怎么解决? 问题原因:qmake没有添加network的模块.在工程配置文件中添加配置即可. 2.选择c++的socket库还是QUdpSocket? 3.同样的 ...
- 让 rtb 不显示 横纵 滚动条的方法
让 rtb 不显示 横纵 滚动条的方法: a.设置属性: tb.ScrollBars=None; b.设置属性:rtb.WordWarp=False; c. 添加事件代码: rtb.ContentsR ...
- 基于C语言的小学四则运算出题器
一.实验目的: 1.帮助老师产出每周随机的300道含有两个运算符的四则运算,. 2.每次题目的产出均为随机,增强同学的四则运算能力. 二.实验环境: Visual C++ 三.实验内容: 1.实现随机 ...
- C# 将实体转xml/xml转实体
xml转实体 /// <summary> /// 把xml转换成实体 /// </summary> /// <typeparam name="T"&g ...
- lnmp重新安装mysql
安装mysql好长时间,一直没去管,后来一直频繁重启,各种网上找方案去解决,最后问题太异常,一顿操作猛如虎之后把mysql彻底搞垮,无奈只能进行重装. whereis mysql mysql: /us ...
- java中取数组第一个元素
java中取数组第一个元素 var a=[1,2,2,3,4];console.log(a);a.shift();console.log(a); pop:删除原数组最后一项,并返回删除元素的值 ...
- ACM需要知道的STL小技巧
天天用stl,但是有一些小技巧如果不知道,偶尔会导致TLE,这里说几个打比赛需要用到的. 主要是大概了解一下其底层原理:https://www.jianshu.com/p/834cc223bb57 就 ...
- 疯一样的向自己发问 - 剖析lsm 索引原理
疯一样的向自己发问 - 剖析lsm 索引原理 lsm简析 lsm 更像是一种设计索引的思想.它把数据分为两个部分,一部分放在内存里,一部分是存放在磁盘上,内存里面的数据检索方式可以利用红黑树,跳表这种 ...
- day10-SpringBoot的异常处理
SpringBoot异常处理 1.基本介绍 默认情况下,SpringBoot提供/error处理所有错误的映射,也就是说当出现错误时,SpringBoot底层会请求转发到/error这个映射路径所关联 ...