flink调优之RocksDB设置
一、开启监控
RocksDB是基于LSM Tree实现的,写数据都是先缓存到内存中,所以RocksDB的写请求效率比较高。RocksDB使用内存结合磁盘的方式来存储数据,每次获取数据时,先从内存中blockcache中查找,如果内存中没有再去磁盘中查询。使用
RocksDB时,状态大小仅受可用磁盘空间量的限制,性能瓶颈主要在于RocksDB对磁盘的读请求,每次读写操作都必须对数据进行反序列化或者序列化。当处理性能不够时。仅需要横向扩展并行度即可提高整个Job的吞吐量。
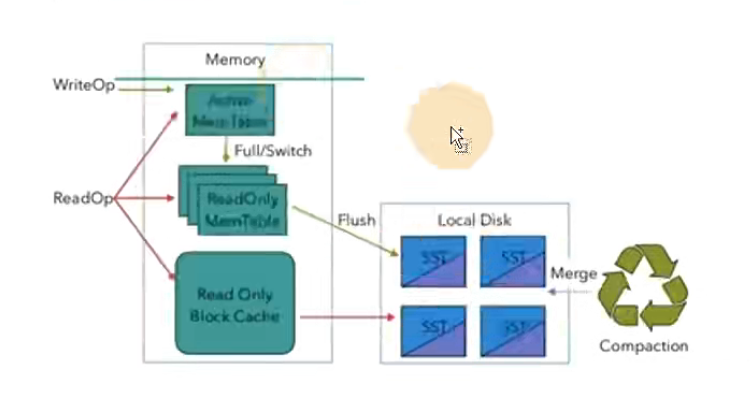
flink1.13中引入了State访问的性能监控,即latency tracking state、此功能不局限于State Backend的类型,自定义实现的State Backend也可以复用此功能。
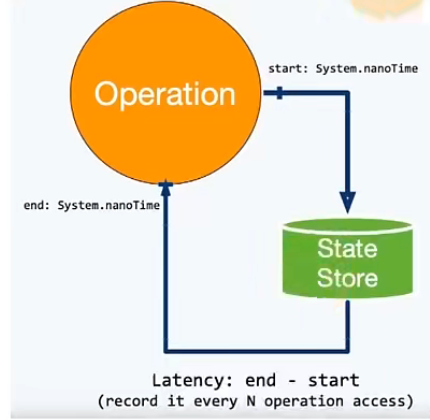
state访问的性能监控会产生一定的性能影响,所以默认每100次做一次抽样sample,对不同的state Backend性能损失影响不同。
对于RocksDB State Backend,性能损失大概在1%左右
对于heap State Backend,性能损失最多可达10%(内存本身速度比较快,一点损失影响就很大)
关于性能监控的一些参数,正常开启第一个参数即可,
state.backend.latency-track.keyed-state-enabled:true //启用访问状态的性能监控
state.backend.latency-track.sample-interval:100 //采样间隔
state.backend.latency-track.histroy-size:128 //保留的采样数据个数,越大越精确
state.backend.latency-track.state-name-as-variable:true //将状态名作为变量
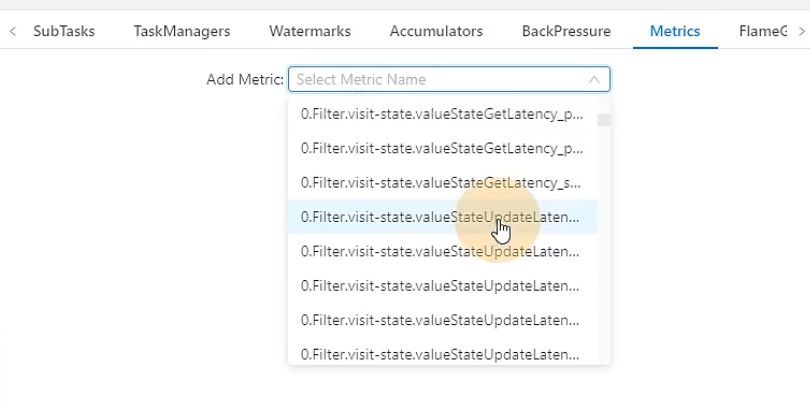
0代表是任务编号,filter.visit-state是定义的状态的变量名
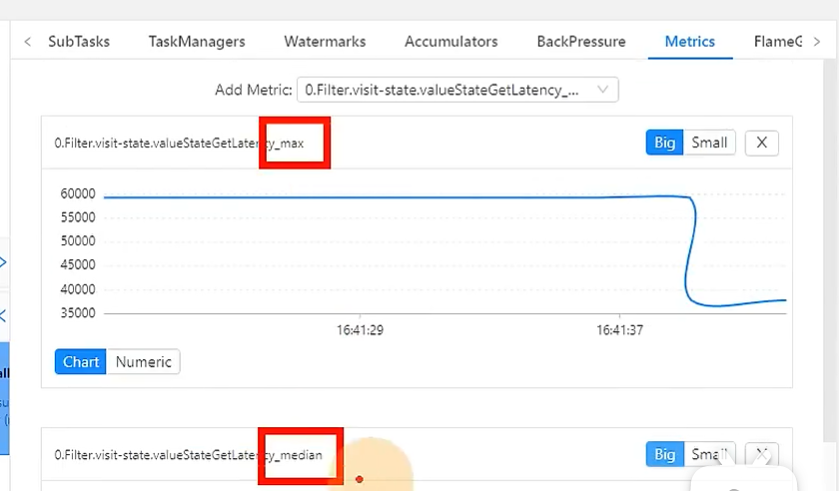
有很多这种统计值可以查看,中位值,75分位值等。
二、RocksDB状态优化
①开启增量检查点:
RocksDB是目前唯一可用于支持有状态流处理应用程序增量检查点的状态后端,可以修改参数开启增量检查点:
state.backend.incremental:true //默认false,可以改为true
或代码中指定 new EmbededRocksDBStateBackend(true)
②开启本地恢复:当flink任务失败时,可以基于本地的状态信息进行恢复任务。可能不需要从hdfs拉取数据。本地恢复目前仅涵盖键值类型的状态后端(RocksDB)。MemoryStateBackend不支持本地恢复并忽略此选项
state.backend.local-recovery:true
③如果你有多块磁盘,可以考虑指定本地多目录
state.backend.rocksdb.localdir:
/data1/flink/rocksdb,/data2/flink/rocksdb,/data3/flink/rocksdb
不要配置单块磁盘的多个目录,务必将目录配置到多块不同的磁盘上,让多块磁盘来分担io压力
三、增量检查点优化效果案例
提交一个任务,具体参数如下
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=2048mb \
-Dtaskmanager.memory.process.size=4096mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-Dstate.backend.latency-track.keyed-state-enabled=true \ //开启状态监控
-c com.xxx.xxx.Demo \
在flink ui查看状态的监控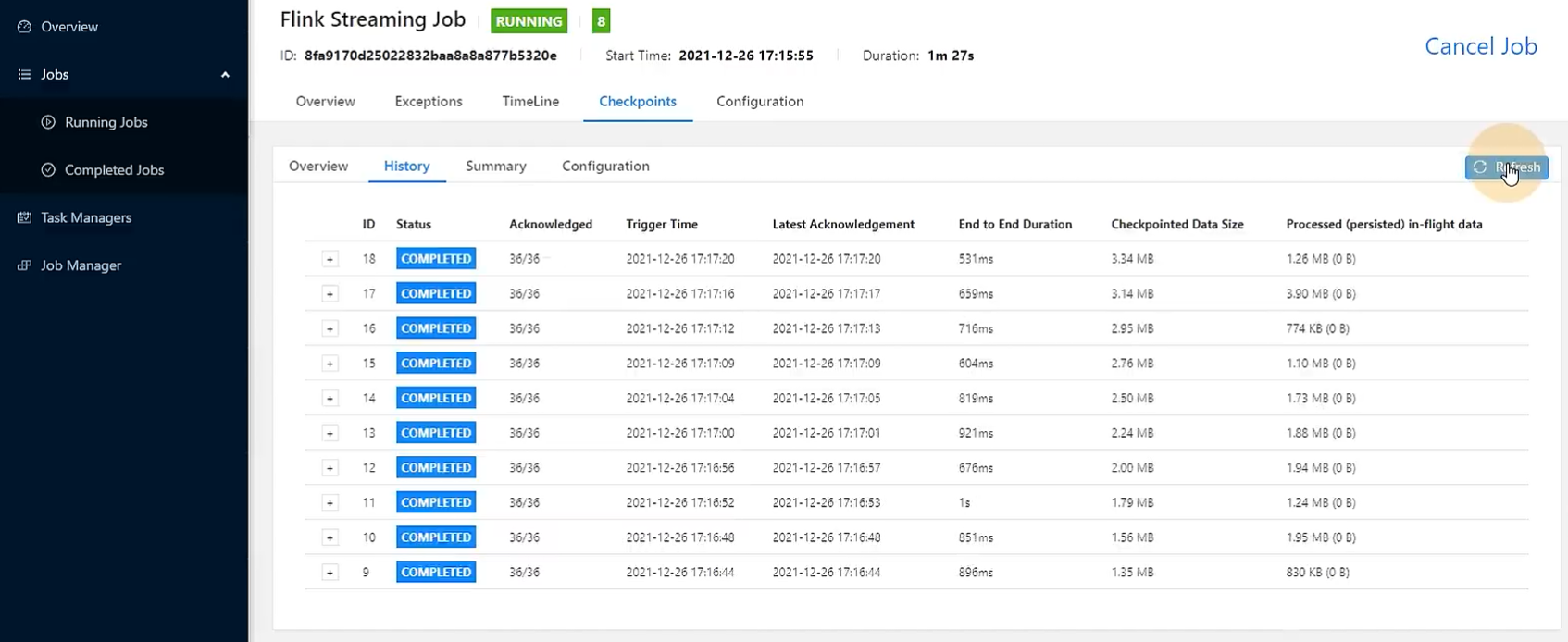
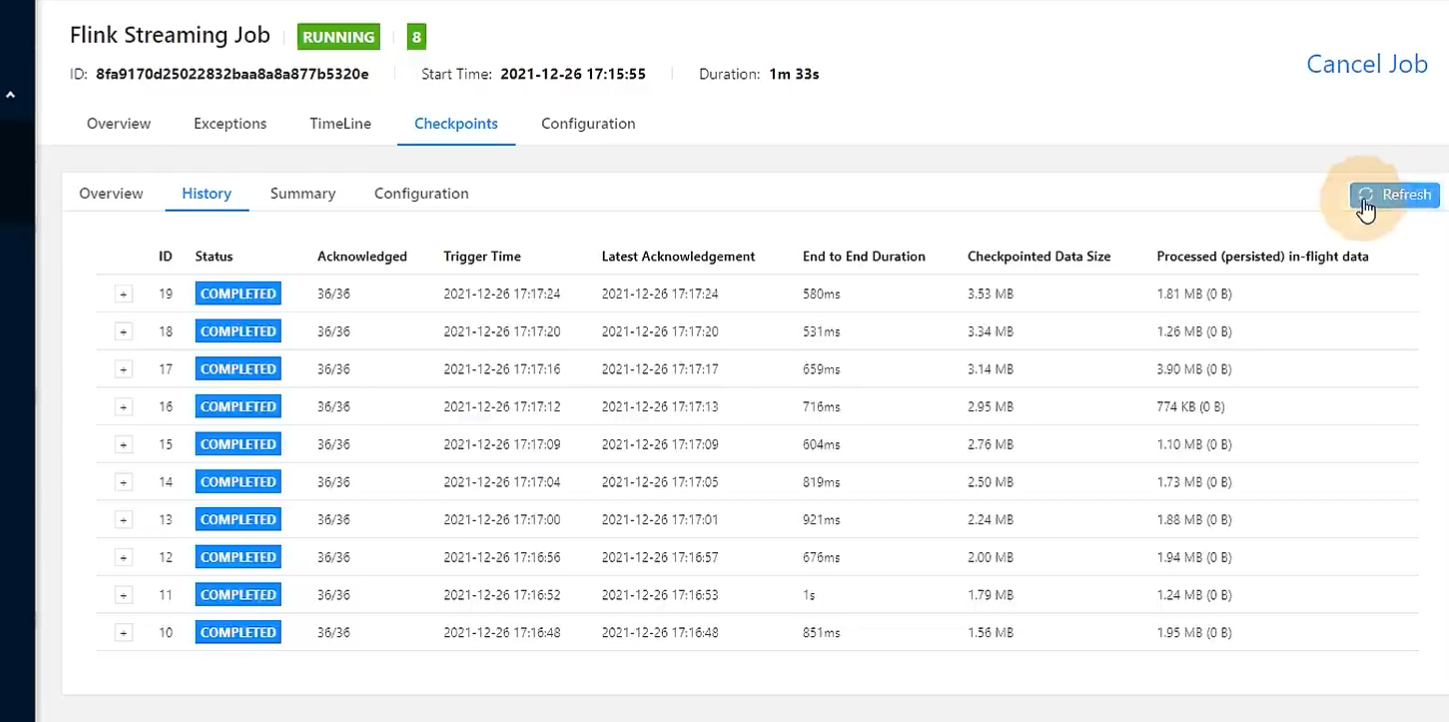
然后重新提交任务,在提交时增加参数:
-Dstate.backend.incremental=true \ //开启增量检查点
-Dstate.backend.local-recovery=true \ //开启本地恢复
代码中增加 env.setStateBackend(new EmbeddedRocksDBStateBackend()) //状态后端使用RocksDB
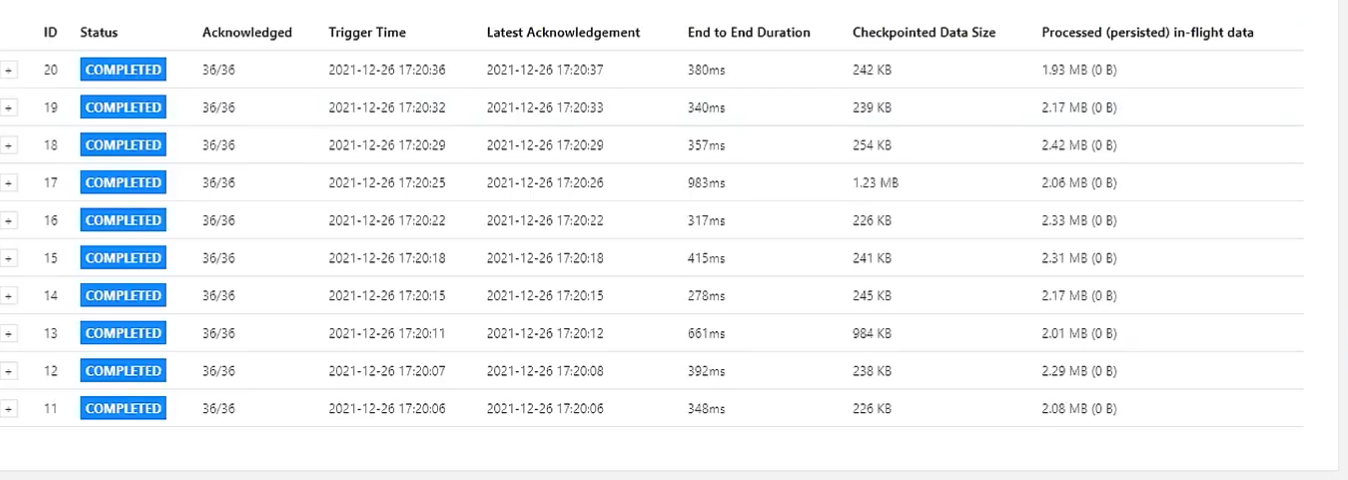
查看两张图的checkpointed data size,可以发现,第一次任务(第一张图)checkpoint时是全量备份,所以状态是越来越大的,从1m+增加到了3m+, 而第二次任务它每次checkpoint的状态大小是有大有小的,范围在200kb-1.2m之间
再查看End to End Duration,第一次任务的状态后端是内存存储,而时间却略大于第二次任务,说明增量的RocksDB的效果有可能好于全量的memory
四、调整RockSDB的预定义选项。
预定义选项就是一个选项集合,如果调整预定义选项达不到预期,再去调整block、writebuffer等参数。
当前支持的预定义选项有支持的选项有:
DEFAULT
SPINING_DISK_OPTIMIZED
SPINNING_DISK_OPTIMIZED_HIGH_MEM
FLASH_SSD_OPTIMIZED (有条件使用ssd的可以使用这个选项)
我们一般使用第三个SPINNING_DISK_OPTIMIZED_HIGH_MEM,设置为机械硬盘+内存模式
该模式下flink会帮我们设置一些它认为比较ok的参数(选项集合),具体如下:
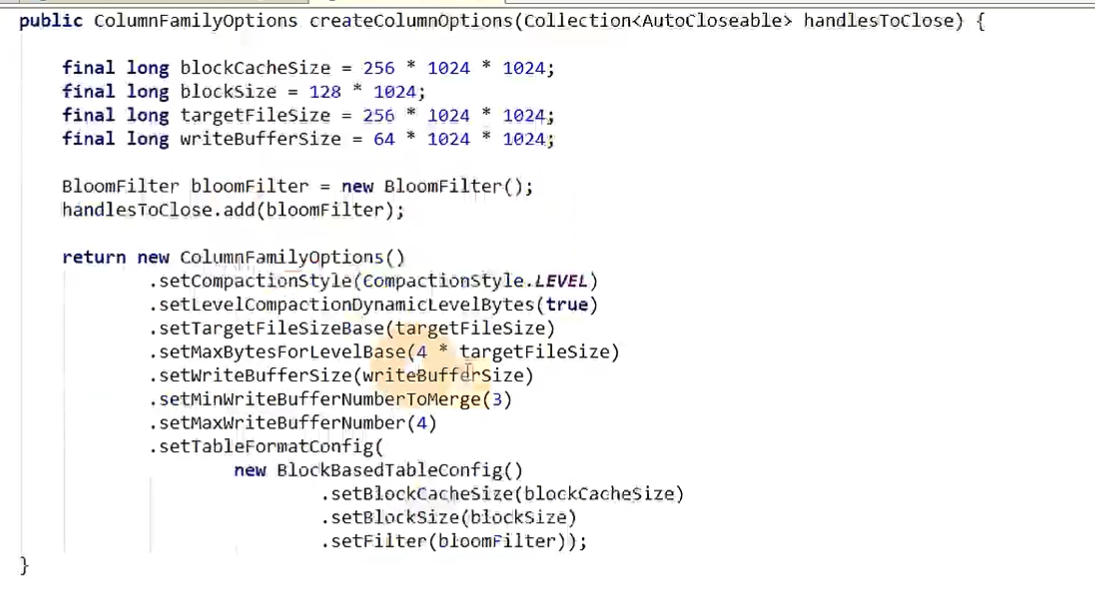
可以在提交任务时指定
state.backend.rocksdb.predefined-options:SPINNING_DISK_OPTIMIZED_HIGH+MEN
也可以在代码中指定:
EmbededRocksDBStateBackend embededRocksDBStateBackend = new EmbededRocksDBStateBackend();
EmbededRocksDBStateBackend,setPredefinedOptions(PredefinedOptions.SPINNING_DISK_OPTIMIZED_HIGH_MEM);
env.setStateBackend(embeddedRocksDBStateBackend);
flink调优之RocksDB设置的更多相关文章
- Spark性能调优之合理设置并行度
Spark性能调优之合理设置并行度 1.Spark的并行度指的是什么? spark作业中,各个stage的task的数量,也就代表了spark作业在各个阶段stage的并行度! 当分配 ...
- Flink调优
第1章 资源配置调优 Flink性能调优的第一步,就是为任务分配合适的资源,在一定范围内,增加资源的分配与性能的提升是成正比的,实现了最优的资源配置后,在此基础上再考虑进行后面论述的性能调优策略. ...
- 生产环境下JVM调优参数的设置实例
JVM基础:生产环境参数实例及分析 原始配置: -Xms128m -Xmx128m -XX:NewSize=64m -XX:PermSize=64m -XX:+UseConcMarkSweepGC - ...
- JVM调优及参数设置
(1)参数 -Xms:初始堆大小 -Xmx :最大堆大小 此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存 -Xmn :年轻代大小 整个堆大小=年轻代大小 + 年老代大小 + 持 ...
- Linux系统调优及安全设置
1.关闭SELinux #临时关闭 setenforce 0 #永久关闭 vim /etc/selinux/config SELINUX=disabled 2.设定运行级别为3 #设定运行级别 vim ...
- nginx调优buffer参数设置
内容来自 https://blog.tanteng.me/2016/03/nginx-buffer-params/.有空再详细了解 Nginx性能调优之buffer参数设置 打开Nginx的error ...
- Tomcat性能调优 通过ExpiresFilter设置资源缓存
转自 http://www.cnblogs.com/daxin/p/3995287.html [简介] ExpiresFilter是Java servlet API 当中的一部分,它负责控制设置res ...
- 22.centos7基础学习与积累-008-系统调优及安全设置
从头开始积累centos7系统运用 大牛博客:https://blog.51cto.com/yangrong/p5 1.关闭selinux功能: SELinux(Securety-EnhancedLi ...
- Linux之【安装系统后的调优和安全设置】
关闭SElinux功能 •修改配置文件使其永远生效 第一种修改方法vi vi /etc/sysconfig/selinuc 或者 vi /etc/selinux/config修改: SELINUX=d ...
随机推荐
- InnoDB 锁的类型
一.全局锁 mysql> flush table with read lock; FTWRL 会对整个实例加只读锁.会阻塞所有线程读以外的所有操作.查看线程状态 State: Waiting f ...
- ssm配置推荐
1.JDK 1.8 2.Mysql 5.7 3.Maven 3.6.1
- 【SVN】Please execute the 'Cleanup' command.
背景 项目有个新的bug,我需要提取一个新的分支,但是提取之后,更新分支出现了这个问题 Please execute the 'Cleanup' command. 原因 由于使用SVN更新文件出错,导 ...
- Superset安装部署操作
目录 1.安装Miniconda 1.下载Miniconda 2.安装 3.开启一个新的shell窗口 4.设置新窗口不自动开启conda 2.创建Python3.7环境 1.配置国内镜像 2.常用命 ...
- C++设计模式 - 访问器模式(Visitor)
行为变化模式 在组件的构建过程中,组件行为的变化经常导致组件本身剧烈的变化."行为变化" 模式将组件的行为和组件本身进行解耦,从而支持组件行为的变化,实现两者之间的松耦合. 典型模 ...
- Tomcat启动时shell窗口乱码解决方法
tomcat/conf/目录下,修改logging.properties java.util.logging.ConsoleHandler.encoding = utf-8 更改为 java.util ...
- 什么是ORM思想?常用的基于ORM的框架有哪些?各有什么特点?
ORM的全称是Object-Relational Mapping,即对象关系映射.ORM思想的提出来源于对象与关系之间相悖的特性.我们很难通过对象的继承与聚合关系来描述数据表中一对一.一对多以及多对多 ...
- 说说三元运算和if...else的相同之处
三元运算符和if-else语句:不同之处. a) 三元运算符是必须要有返回值,而if-else语句并不一定有返回值,其执行结果可能是赋值语句或者打印输出语句. b) java三元表达式有字符强转(双目 ...
- 解释 AOP 模块?
AOP 模块用于发给我们的 Spring 应用做面向切面的开发, 很多支持由 AOP 联 盟提供,这样就确保了 Spring 和其他 AOP 框架的共通性.这个模块将元数据编 程引入 Spring.
- MySQL 里有 2000w 数据,redis 中只存 20w 的数据,如 何保证 redis 中的数据都是热点数据?
Redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略. 相关知识:Redis 提供 6 种数据淘汰策略: volatile-lru:从已设置过期时间的数据集(server.db[i]. ...