InnoDB两次写
partial page write问题:
默认情况下,innodb的一个页面时16k大小,其数据校验也是针对这16k来校验的,将数据写入磁盘是以页面为单位的。文件系统是以4k为单位写入的,机械磁盘是以扇区【512字节】为单位写入的,因此不能保证一个16k的页面原子性写入。如果在刷新脏页的时候系统宕机,16k中只有4k写入到磁盘中,那么这个数据文件就是错误的。
为了解决partial page write的问题,InnoDB实现了double write buffer;简单来说,就是在写数据页之前,先把这个数据页写入到一块独立的物理文件位置,然后再写入数据页。这样,在数据库宕机重写时,如果出现数据页损坏,那么在应用redo log之前,需要通过该页的副本来还原该页,然后再进行redo log重做,这就是double write。
double write由两部分组成,一部分是内存中的double write buffer, 其大小未2M;另一部分为磁盘上 ibdata中连续的128个页,其大小也是2M。
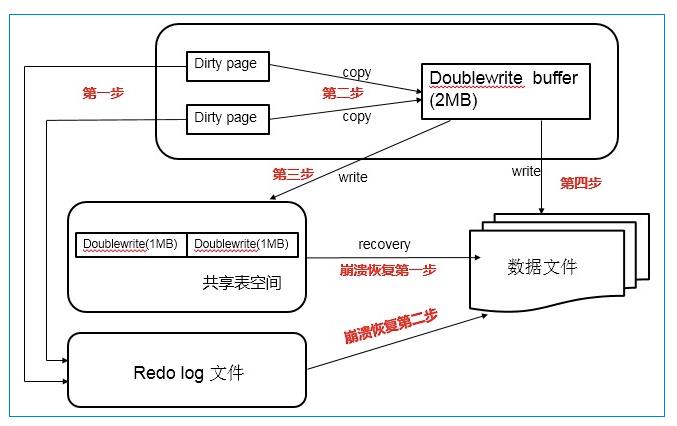
1. 当一系列机制触发缓冲池中脏页刷新时,并不直接写入磁盘数据文件中,而是先拷贝至内存中的double write buffer中。
2. 接着从两次写缓冲区中分两次写入磁盘共享表空间中(连续存储,顺序写,性能很高),每次写1M
3. 待第二部完成之后,再将double write buffer中的脏页数据写入实际的各个表空间文件中(离散写),脏页数据固化后,即进行标记对应的double write数据可覆盖。

再看redo log的写入关系:
两次写算法:单一页面刷盘 && 批量页面刷盘
单一页面刷盘:每次刷盘前,都要将刷盘的页面信息临时保存在内存的数组中,这个空间也是128个页面,这个缓存称为两次写缓冲数组。
1. 先在两次写缓存数组中,找到一个空闲位置,并将这个位置标记为已使用,然后再把要刷新的页面数据复制到标记的缓存空间中
2. 将页面中的数据刷新到两次写文件中,即ibdata文件中,偏移位置时这个页面在两次写缓存空间中的位置。此时页面是持久化的。
3. 页面刷盘,将数据刷新到真实的位置,即idb文件中
需要注意的是,因为buffer pool中的页面,刷新到真实文件中时是异步IO的,那么只有当刷到自己表空间中刷盘操作完成之后,两次写缓冲数组中的数据才可以被覆盖。或者说,这个页面对应的两次写文件中的页面才可以被覆盖,不然有可能造成这个两次写位置的页面被新的页面覆盖的问题。
批量页面刷盘:单一页面刷盘,会消耗大量的磁盘IO,因此出现了批量页面刷盘。
批量页面刷盘包括两种方式:分别为 LRU和 LIST。当 Buffer Pool空间不足时,再载入新的页面就要将一些不经常使用的页面淘汰出去。此时系统就会从LRU链表中找到最老的页面,进行批量刷盘,将释放的空间加入到空闲空间中去,这种情况就是LRU刷盘。当日志空间不足,或者后台MASTER线程定时刷盘时,这是就不需要区分页面的新旧状态,只需要选择LSN最小的页面,从前到后刷一批到磁盘中,这就是LIST刷盘。
在批量刷盘的两次写中,这两种刷盘方法对应的两次写空间互不干涉。
Innodb自身的Buffer Pool包含多少个Instance,每个Instance管理自身的一套两次写空间,而针对每一个 Instance的每一个刷盘方法的批量缓存空间大小,是通过参数 innodb_doublewrite_batch_size控制的,默认值是120,这样下来,两次写文件页面数的计算方式如下:
innodb_buffer_pool_instances * 2[LIST + LRU] * innodb_doublewrite_batch_size
批量刷盘的过程:
假设由于页面淘汰,系统要做一次批量刷盘,这就是LRU的方式,此时系统就要将当前页面加入两次写空间缓存,首先需要根据当前页面所在的Instance号及刷盘类型找到对应的shard缓存,找到缓存后,就会判断当前缓存是否满了,如果没有达到,则将当前页面内容追加复制到两次写缓存中,这样当前页面的刷盘操作就完成了。这里并不像单一页面那样,先写入缓存空间,然后写入ibdata文件的两次写空间,最后还需要立即将页面的真实内容刷入表空间,对于批量刷盘来说,只需要写入shard缓存就可以了。
如果当前shard中缓存的页面个数已经达到了 innodb_doublewrite_batch_size, 则说明当前缓存空间已经满了,此时不得不将当前shard缓存中的页面写入两次写文件中,写完之后再将两次写文件flush到磁盘,最后将对应的真实页面刷盘,此时可能是随机写入了,因为对应的两次写缓存中虽然是连续的,但对应的真实页面就不会这样了。这里需要注意的是,表空间页面的刷盘,是异步IO操作,此时需要等待异步IO完成,且整个shard中的页面都刷盘后哦,刷盘操作才可以继续向后执行,而这个shard也可以再次使用了,缓存中的数据也都会被清空。
需要注意的是,上面过程中写入是连续innodb_doublewrite_batch_size 个页面,所以性能会比写入多次而每次写入一个页面的情况好很多。批量刷盘的情况下,有可能每隔innodb_doublewrite_batch_size个页面的刷盘操作,就会出现一次等待操作,且等待时间长短不一定,但这也是在单一页面刷盘的基础上优化过的,做了改进。
两次写的作用:
在数据库启动时(异常关闭的情况下),都会做数据库恢复(redo)操作。在恢复的过程中,数据库会检查页面是否合法(校验),如果发现一个页面的校验结果不一致,则此时就会用到两次写机制,用两次写空间中的数据来恢复异常页面的数据,这也正是为处理这样的错误而设计的。此时的处理机制就是,将两次写的两个簇都读出来,再将innodb_parallel_doublewrite_path文件的内容读出来,然后将所有这些页面写回到对应的页面中去,这样就可以保证这些页面是正确的,并且是在写入前已经更新过的(最新数据)。在写回对应页面中去之后,就可以在此基础上继续做数据库恢复了,且不会遇到这样的问题了,因为最后有可能产生写断裂的数据页面都恢复了。
InnoDB两次写的更多相关文章
- mysql源码:关于innodb中两次写的探索
两次写可以说是在Innodb中很独特的一个功能点,而关于它的说明或者解释非常少,至于它存在的原因更没有多少文章来说,所以我打算专门对它做一次说明. 首先说明一下为什么会有两次写这个东西:因为innod ...
- Mysql 源码:关于innodb中两次写的探索
转载自:http://www.cnblogs.com/bamboos/p/3553703.html?utm_source=tuicool&utm_medium=referral 两次写可以说是 ...
- innodb 关键特性(两次写与自适应哈希索引)
两次写: 场景: 当发生数据库宕机时,可能innodb存储引擎正在写入某个页到表中,而这个页只写了一部分,这种情况被称为部分写失效,如果发生,可以通过重做日志进行恢复,重做日志中记录的是对页的物理操作 ...
- MySQL InnoDB特性:两次写(Double Write)
http://www.ywnds.com/?p=8334 一.经典Partial page write问题? 介绍double write之前我们有必要了解partial page write(部分页 ...
- InnoDB的关键特性-插入缓存,两次写,自适应hash索引
InnoDB存储引擎的关键特性包括插入缓冲.两次写(double write).自适应哈希索引(adaptive hash index).这些特性为InnoDB存储引擎带来了更好的性能和更高的可靠性. ...
- 【InnoDB】插入缓存,两次写,自适应hash索引
InnoDB存储引擎的关键特性包括插入缓冲.两次写(double write).自适应哈希索引(adaptive hash index).这些特性为InnoDB存储引擎带来了更好的性能和更高的可靠性. ...
- MySQL 基础知识梳理学习(五)----详解MySQL两次写的设计及实现
一 . 两次写提出的背景或要解决的问题 两次写(InnoDB Double Write)是Innodb中很独特的一个功能点.因为Innodb中的日志是逻辑的,所谓逻辑就是比如插入一条记录时,它可能会在 ...
- MySQL中MyISAM和InnoDB两种主流存储引擎的特点
一.数据库引擎(Engines)的概念 MySQ5.6L的架构图: MySQL的存储引擎全称为(Pluggable Storage Engines)插件式存储引擎.MySQL的所有逻辑概念,包括SQL ...
- csdn肿么了,这两天写的博文都是待审核
昨天早上8点写了一篇博文,然后点击发表,结果系统显示"待审核".于是仅仅好qq联系csdn的客服,等到9点时候,csdn的客服上线了,然后回复说是链接达到5个以上须要审核,于是回到 ...
随机推荐
- 5月8日 python学习总结 mysql 建表操作
一 .创建表的完整语法 create table 表名( 字段名1 类型[(宽度) 约束条件],字段名2 类型[(宽度) 约束条件],字段名3 类型[(宽度) 约束条件]); 解释: 类型:使用限制字 ...
- async-validator 源码学习笔记(五):Schema
系列文章: 1.async-validator 源码学习(一):文档翻译 2.async-validator 源码学习笔记(二):目录结构 3.async-validator 源码学习笔记(三):ru ...
- java高级用法之:调用本地方法的利器JNA
目录 简介 JNA初探 JNA加载native lib的流程 本地方法中的结构体参数 总结 简介 JAVA是可以调用本地方法的,官方提供的调用方式叫做JNI,全称叫做java native inter ...
- 手把手带你使用Paint in 3D和Photon撸一个在线涂鸦画板
Paint in 3D Paint in 3D用于在游戏内和编辑器里绘制所有物体.所有功能已经过深度优化,在WebGL.移动端.VR 以及更多平台用起来都非常好用! 它支持标准管线,以及 LWRP.H ...
- Fegin 的使用
- Xshell 连接虚拟机OS Linux 设置静态ip ,网络配置中无VmWare8 的解决办法
前序:最近开始研究Hadoop平台的搭建,故在本机上安装了VMware workstation pro,并创建了Linux虚拟机(centos系统),为了方便本机和虚拟机间的切换,准备使用Xshell ...
- 使用Pycharm IDE工具,使用input()函数出现>?符号
Python Console === 如果你是要Pycharm开发Python项目时,出现使用input函数,提示 >? 符号的时候,那应该是开启了Python Console控制台输出,取 ...
- Java并发机制(3)--volatile关键字与内存模型
Java并发编程:volatile关键字解析及内存模型 个人整理自:博客园-海子-http://www.cnblogs.com/dolphin0520/p/3920373.html 1.线程内存模型: ...
- 转载:STL四种智能指针
转载至:https://blog.csdn.net/K346K346/article/details/81478223 STL一共给我们提供了四种智能指针: auto_ptr.unique_ptr.s ...
- Zookeeper 的 java 客户端都有哪些?
java 客户端:zk 自带的 zkclient 及 Apache 开源的 Curator.