02、kafka介绍
001、kafka简介
kafka消息队列有两种消费模式,分别是点对点模式和订阅/发布模式。具体比较可以参考Kafka基础–消息队列与消费模式。
下图是一个点对点的Kafka结构示意图
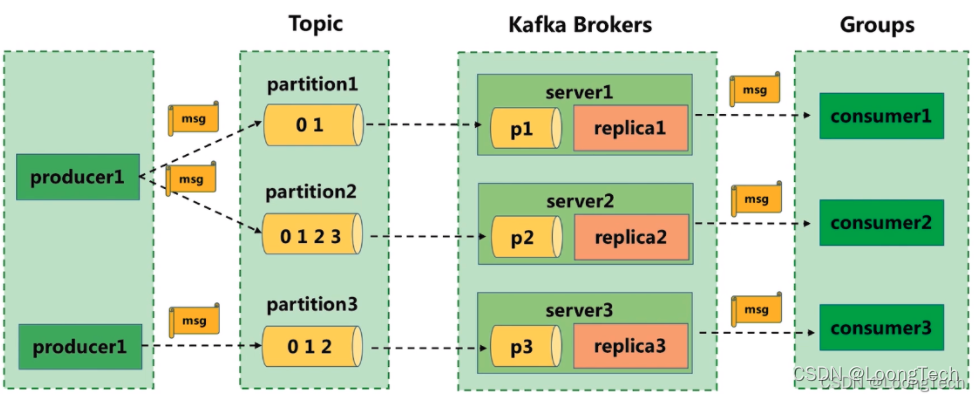
producer:消息生产者
consumer:消息消费者
Topic:消息主题
partition:主题内分区
Brokers:消息服务器
Groups:消费者组
002、关于Topic
Kafka需要对消息进行逻辑上的分类(而topic就是用来实现逻辑分类)
在一个小型电商项目中,如果订单模块和商品模块都需要使用消息队列。两个模块中的消息一个是订单信息,一个是商品的描述消息。两种消息肯定不是同一类的消息,它们消息内容不一样、结构不一样、并且分别有自己的生产者群体和消费者群体。
Kafka消息系统是一个庞大的系统,不可能针对两个模块都各自搭建一套kafka消息系统。那么如何在一套消息系统中为多个模块提供服务。那就要对不同类型的消息进行逻辑分类,具体分类的方式就是用Topic进行区分,不同类别的消息具有不同的Topic。
既然Kafka通过Topic唯一标示每类消息,那么,
- 每条消息属于且仅属于一个Topic
- Producer发布数据时,必须指定将该消息发布到哪个Topic
- Consumer消费消息时,也必须指定消费哪个Topic的信息
003、关于partition
031、partition的作用
既然Topic已经对消息进行了分类,为什么每个Topic内部还需要按照Partition进行再次区分。
topic是逻辑的概念,partition是物理的概念。 啥是物理概念,就是物理上进行分离,分布在不同的实体机器上。
知乎上有一段很形象的描述:Kafka的设计也是源自生活,好比是为公路运输,不同的起始点和目的地需要修不同高速公路(主题topic)。高速公路上可以提供多条车道(分区partition),流量大的公路多修几条车道保证畅通,流量小的公路少修几条车道避免浪费。收费站好比消费者,车多的时候多开几个一起收费避免堵在路上,车少的时候开几个让汽车并道就好了。
如果没有分区,一个topic对应的消息集在分布式集群服务组中,就会分布不均匀,即可能导致某台服务器A记录当前topic的消息集很多,若此topic的消息压力很大的情况下,服务器A就可能导致压力很大,吞吐也容易导致瓶颈。有了分区后,假设一个topic可能分为10个分区,kafka内部会根据一定的算法把10分区尽可能均匀分布到不同的服务器上,比如:A服务器负责topic的分区1,B服务器负责topic的分区2,在此情况下,Producer发消息时若没指定发送到哪个分区的时候,kafka就会根据一定算法上个消息可能分区1,下个消息可能在分区2。
所以,partition的目的是:通过多分区实现负载均衡的效果,提高kafka访问吞吐率。
032、partition的使用
在没有partition的时候,生产者产生特定Topic的消息,消费者消费特定topic的消息。现在每个Topic内又划分了Partition,原来的模式会如何变化呢,具体partition怎么用呢?参考图解进一步理解。
可以看到 Topic 被分成多个 Partition 分区。
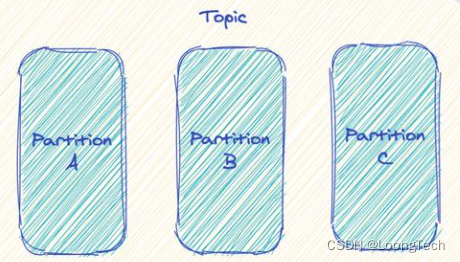
Topic 是一个逻辑概念,Partition 是最小的存储单元,掌握着一个 Topic 的部分数据。每个 Partition 都是一个单独的 log 文件,每条记录都以追加的形式写入。
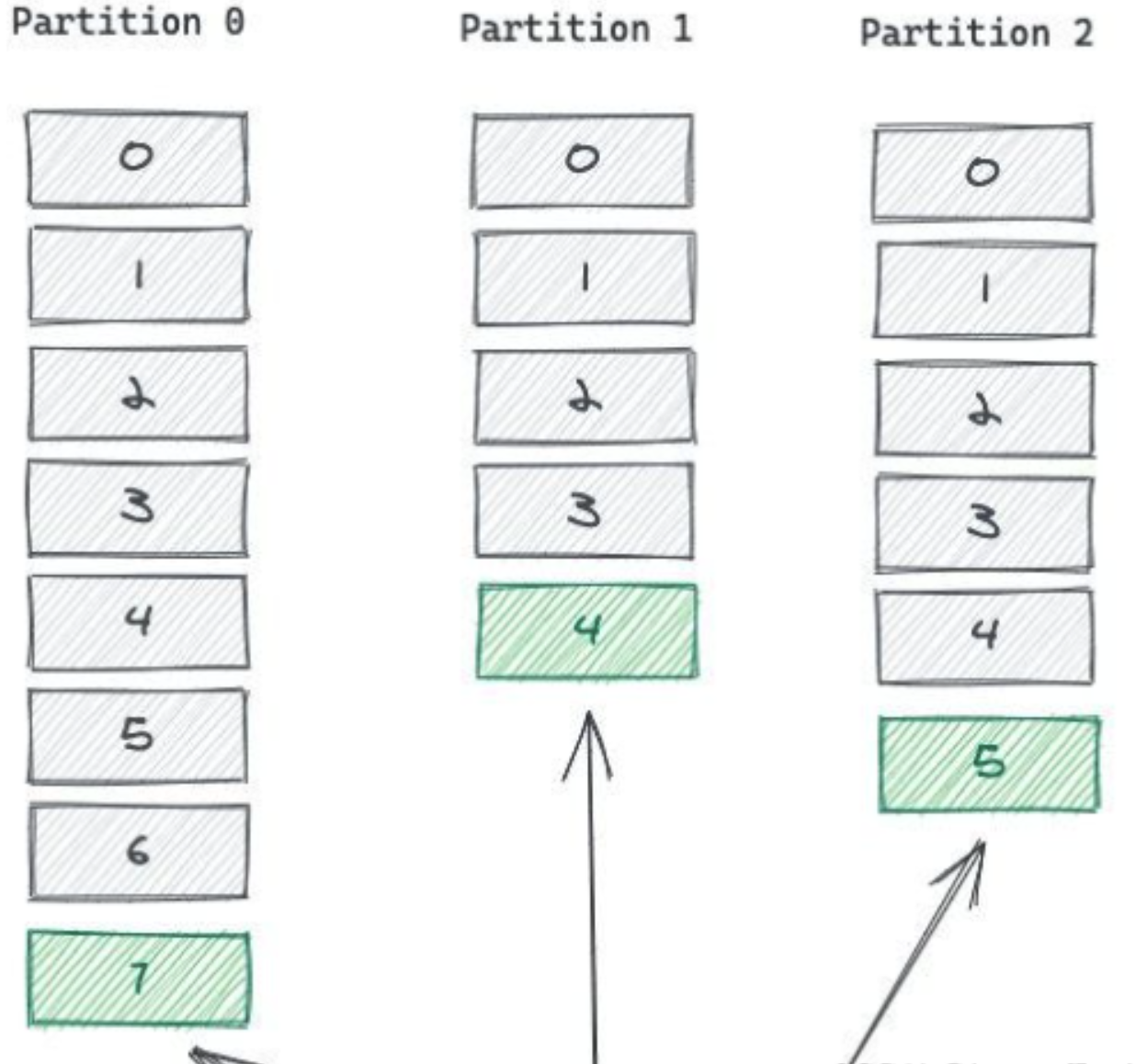
033、topic和Partition的结合
A 数据写入
一个 Topic 有多个 Partition,那么,向一个 Topic 中发送消息的时候,具体是写入哪个 Partition 呢?有3种写入方式:
kafka默认轮询规则
producer指定partition key写入特定的partition
producer自定义规则
B 数据消费
点对点的消费模式中,Consumer 必须自己从 Topic 的 Partition 拉取消息。一个 Consumer 连接到一个 Broker 的 Partition,从中依次读取消息。
C 一个消费者:partition数目 > 消费者数目
只有一个消费者时,消费者1将收到4个分区的全部消息。当有两个消费者时,每个消费者将分别从两个分区接受消息。
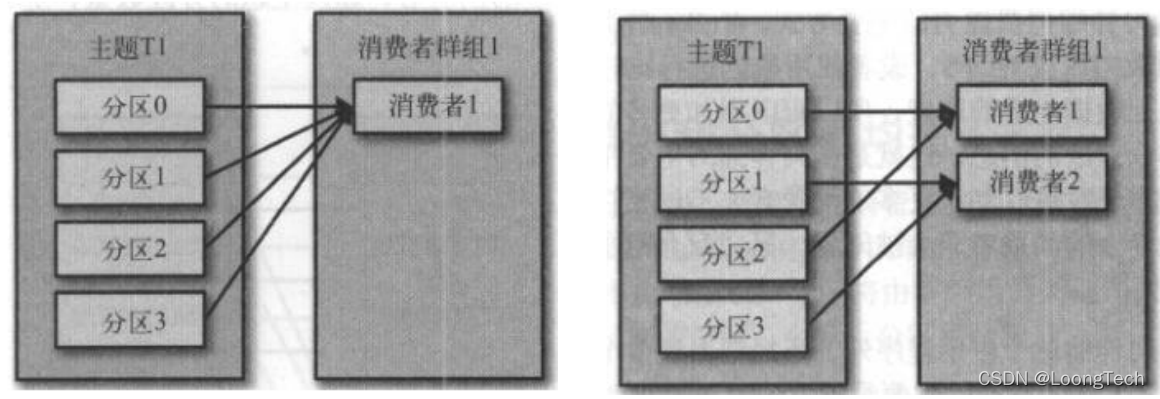
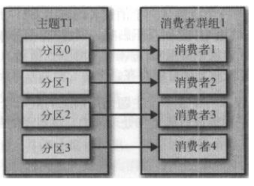
D 四个消费者:partition数目 = 消费者数目
当有四个消费者时,每个消费者都可以接受一个分区的消息。
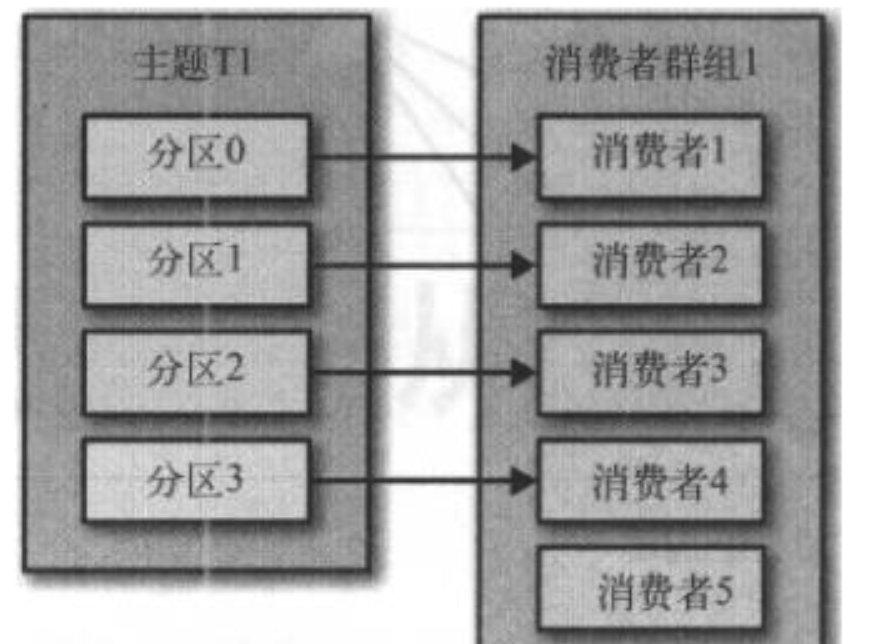
E 五个消费者:partition数目 < 消费者数目
当有五个消费者时,会有闲置的消费者。
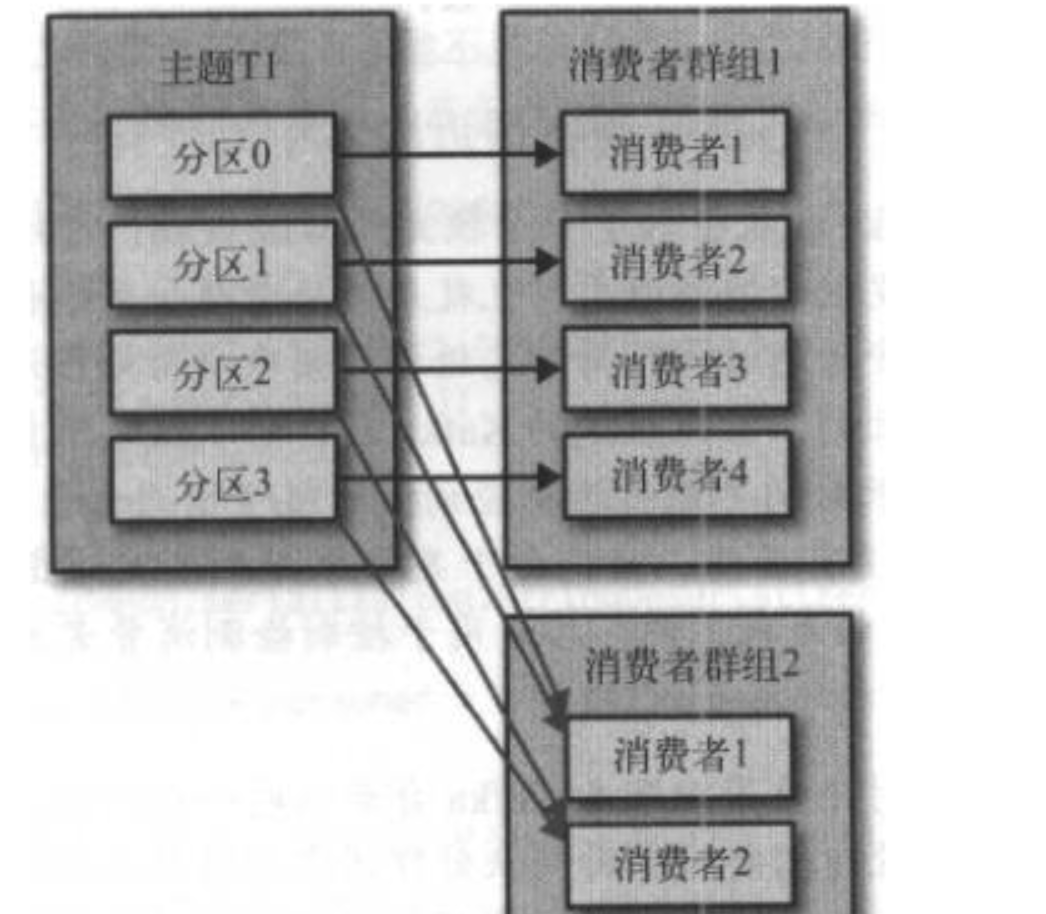
F 两个或多个消费者组
消费者群组之间是互不影响的,每个消费者群组内部仍然按照2.1中的策略进行消息消费。
在实际的业务中,特别是涉及到指定任务是否结束,任务对应消息是否消费完毕时,单纯指定topic消费,由kafka自动分配partition已经无法满足我们的实际需求了,这时我们还需要指定partition进行生产与消费。
004、关于Groups
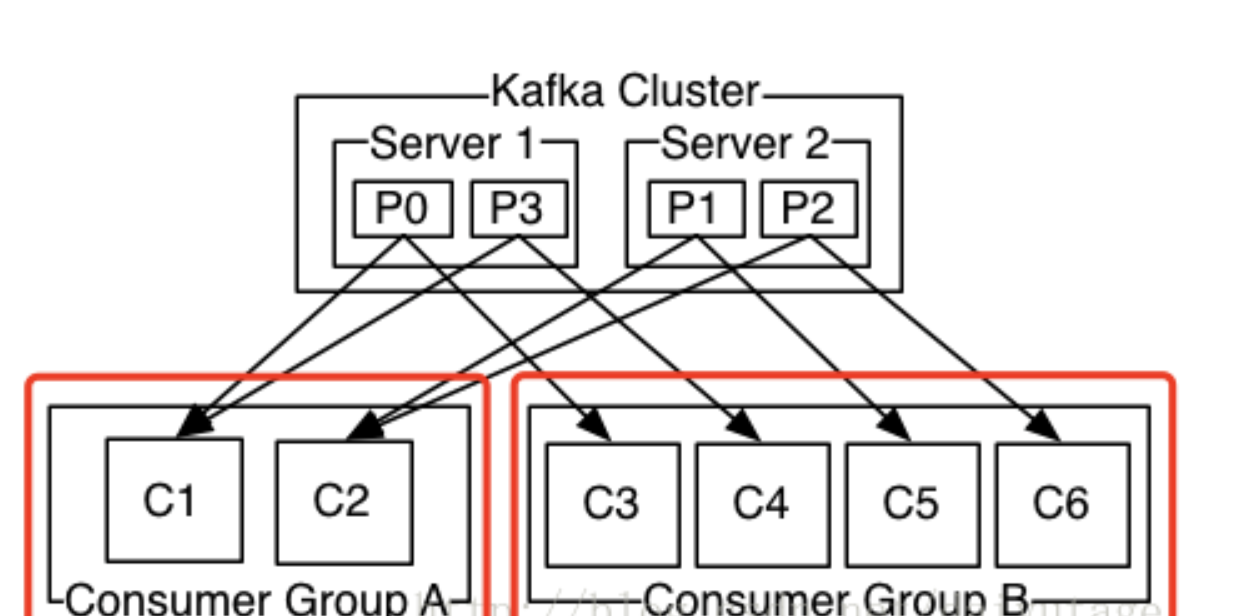
consumer group是kafka提供的可扩展且具有容错性的消费者机制。
既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的ID,即group ID。组内的所有消费者协调在一起来消费对应主题(subscribed topics)的所有分区(partition)。
同一个topic的partition只能由同一个消费组内的一个consumer来消费,group内部是“共享订阅、提高性能”。
当然,该分区partition还可以被分配给其他group,各group间是“各自消费,互不影响”。
005、关于Brokers
缓存代理,Kafka集群中的一台或多台服务器统称broker。
一个broker是由ZooKeeper管理的单个Kafka节点。一组brokers组成了Kafka集群。
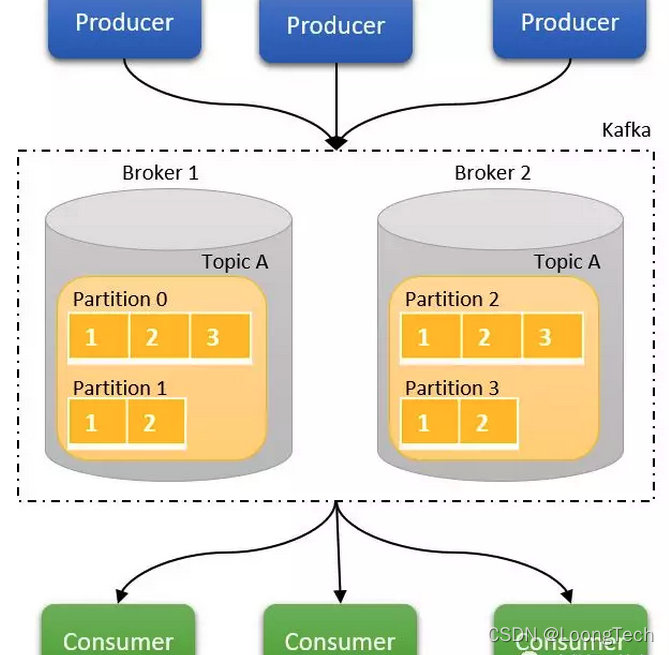
在Kaka中创建的主题基于分区,复制和其他因素分布在broker中。当broker节点基于ZooKeeper中存储的状态失败时,它会自动重新平衡群集,如果领导分区丢失,则其中一个跟随者请求被选为领导者。
02、kafka介绍的更多相关文章
- Apache Kafka - 介绍
原文地址地址: http://blogxinxiucan.sh1.newtouch.com/2017/07/12/Apache-Kafka-介绍/ Apache Kafka教程 之 Apache Ka ...
- 1、Kafka介绍
1.Kafka介绍 1)在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算. 2)Kafka是一个分布式消息队列. 3)Kafka对消息保存时根据Topic进行归类, ...
- [转]kafka介绍
转自 https://www.cnblogs.com/hei12138/p/7805475.html kafka介绍 1.1. 主要功能 根据官网的介绍,ApacheKafka®是一个分布式流媒体平台 ...
- Android Service总结02 service介绍
Android Service总结02 service介绍 版本 版本说明 发布时间 发布人 V1.0 介绍了Service的种类,常用API,生命周期等内容. 2013-03-16 Skywang ...
- Kafka介绍及安装部署
本节内容: 消息中间件 消息中间件特点 消息中间件的传递模型 Kafka介绍 安装部署Kafka集群 安装Yahoo kafka manager kafka-manager添加kafka cluste ...
- kafka介绍与搭建(单机版)
一.kafka介绍 1.1 主要功能 根据官网的介绍,ApacheKafka®是一个分布式流媒体平台,它主要有3种功能: 1:It lets you publish and subscribe to ...
- kafka介绍及安装配置(windows)
Kafka介绍 Kafka是分布式的发布—订阅消息系统.它最初由LinkedIn(领英)公司发布,使用Scala和Java语言编写,与2010年12月份开源,成为Apache的顶级项目.Kafka是一 ...
- 一、kafka 介绍 && kafka-client
一.kafka 介绍 1.1.kafka 介绍 Kafka 是一个分布式消息引擎与流处理平台,经常用做企业的消息总线.实时数据管道,有的还把它当做存储系统来使用. 早期 Kafka 的定位是一个高吞吐 ...
- 085 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 02 构造方法介绍 04 构造方法调用
085 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 02 构造方法介绍 04 构造方法调用 本文知识点:构造方法调用 说明:因为时间紧张,本人写博客过程中只是 ...
- 084 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 02 构造方法介绍 03 构造方法-this关键字
084 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 02 构造方法介绍 03 构造方法-this关键字 本文知识点:构造方法-this关键字 说明:因为时间紧 ...
随机推荐
- java运算符相关学习
java运算符 面试题1: 计算2*8如何操作效率更高? 剖析: 2 * 8 => 实际上是2 * 2 * 2 * 2 2<<3 System.out.println(2<&l ...
- pgsql中行数据转json数组
SELECT array_to_json(array_agg(row_to_json(sys_xzqh))) from sys_xzqh where xzqh like '%341126%'
- centos7安装php8
原文: http://www.manongjc.com/detail/25-qpyxndyogppmfdf.html 前言 centos7默认源的php版本只有5.4,版本太老,而mediawiki需 ...
- 【SSO单点系列】(3):CAS4.0 之自定义返回登出页面
一.登出实现返回自定义页面 服务端修改 cas-servlet.xml <bean id="logoutAction" class="org.jasig.cas.w ...
- JavaScript 数字与字符串的加减乘除运算
点击跳转 Tips: 除开字符串 + 数字的运算,会产生级联,其他情况下会将 String 转为 number 再进行数字运算. js 运算是从左到右的,所以一步一步来,不要跳步进行运算.
- Redis哨兵模式+缓存穿透、击穿和雪崩
一.哨兵模式概述(自动选主机的方式)主从切换技术:当主机宕机后,需要手动把一台从(slave)服务器切换为主服务器,这就需要人工干预,费时费力,还回造成一段时间内服务不可用,所以推荐哨兵架构(Sent ...
- 前端之Vue day07 混入、插件、elementui、Router、Vuex
一.Props补充 1.父传子在子组件标签上起自定义属性 使用数组 就不演示了,太简单了 2.限制传入的数据类类型 使用对象 同样,展示过的 3.props补充 就是套对象,加以限制 props:{ ...
- CentOS 7 安装步骤以及初始化
2. 虚拟机分配的资源 因为用的软件不一样,这里设置方法无法截图,但大至如下: 2CPU/1G内存/200G硬盘 去掉打印机等没用的硬件(macOS要去掉打印机和摄像头) 光盘开始选择空白光盘,不要在 ...
- 如何为 Debian 11 安装图形用户界面 (GUI)
如何为 Debian 11 安装图形用户界面 (GUI) allway2 于 2021-12-26 17:30:14 发布 11767 收藏 23文章标签: debian 服务器 linux版权 华为 ...
- Nuget管理器下载插件出现依赖性相关无法正确下载
话不多说,直接上图: 上面我采用的是PM控制台下载EntityFrameWork最新版本,之所以要这样做,是因为利用Nuget管理器好像不咋管用呀,一直说这个依赖那个依赖啥的,还不如最底层 用命令控制 ...