Neural Networks
神经网络能够使用torch.nn包构建神经网络。
现在你已经对autogard有了初步的了解,nn基于autograd来定义模型并进行微分。一个nn.Module包含层,和一个forward(input)方法并返回output。
以如下分类数字图片的网络所示:
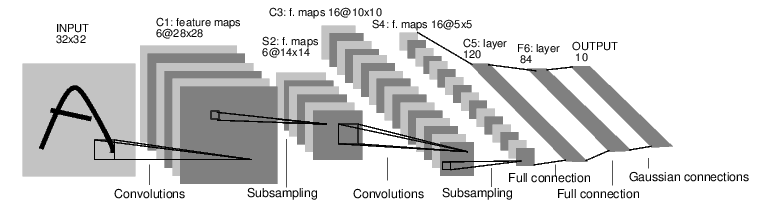
这是一个简单的前馈网络。它接受输入,经过一层接着一层的神经网络层,最终得到输出。
一个神经网络典型的训练流程如下:
- 定义拥有可学习的参数的神经网络
- 迭代数据集作为输入
- 经过网络处理输入
- 计算损失(离正确输出的距离)
- 反向传播梯度到网络参数
- 更新网络的权重,比如简单的更新规则:weight=weight-learning_rate*gradient
定义网络
让我们定义这个网络:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
# 一个输入图片通道,六个输出通道,5*5的卷积核
self.conv1=nn.Conv2d(1,6,5)
self.conv2=nn.Conv2d(6,16,5)
# 一个仿射操作:y=wx+b
self.fc1=nn.Linear(16*5*5,120)
self.fc2=nn.Linear(120,84)
self.fc3=nn.Linear(84,10) def forward(self,x):
# 2*2窗口的最大赤化
x=F.max_pool2d(F.relu(self.conv1(x)),(2,2))
# 如果是一个方块就只需要指定一个长度
x=F.max_pool2d(F.relu(self.conv2(x)),2)
x=x.view(-1,self.num_flat_features(x))
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=self.fc3(x)
return x def num_flat_features(self,x):
#第一个尺寸是batch size
size=x.size()[1:]
print(size)
num_features=1
for s in size:
num_features*=s
return num_features net=Net()
print(net)
out:
Net(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
你只需要定义forward函数,backward函数(计算梯度的地方)是自动定义的。你能够在forward中使用任意的tensor运算。
模型可学习的参数将通过net.parameters()返回
params=list(net.parameters())
print(len(params))
print(params[0].size())
out:
10
torch.Size([6, 1, 5, 5])
让我们试一下随机的32*32输入,注意:这个网络(LeNet)期望的输入尺寸是32*32。为了在MNIST数据集上使用这个网络,请将数据集的图片调整到32*32。
input=torch.randn(1,1,32,32)
out=net(input)
print(out)
out:
tensor([[ 0.0355, -0.0294, -0.0025, -0.0743, -0.0168, -0.0202, -0.0558,
0.0803, -0.0162, -0.1153]])
将所有参数的梯度缓冲变为0并使用随机梯度进行后向传播:
net.zero_grad()
out.backward(torch.randn(1,10))
!注意:
torch.nn只支持最小批。整个torch.nn包只支持输入的样本是一个最小批,而不是一个单一样本.
举例来说,nn.Conv2d将会接收4维的Tensor,nSamples*nChannels*Heights*Width.
如果你有一个单一样本,可以使用input.unsqueeze(0)来增加一个虚假的批维度。
在进行进一步处理前,让我们简要重复目前为止出现的类。
扼要重述:
- torch.Tensor- 一个支持自动求导操作比如backward()的多维数组。同时保留关于tensor的梯度.
- nn.Module- 神经网络模型。简易的封装参数的方法,帮助将它们转移到GPU上,导出加载等等.
- nn.Parameters - 一类Tensor,在作为Module属性指定时会自动注册为一个parameter.
- autograd.Function- 自动求导操作前向与后向的实现。每个tensor操作,至少创建一个Functional节点,它连接到创建Tensor的函数并编码它的历史
在这一节,我们包含了:
- 定义一个神经网络
- 处理输入并调用后向传播
还剩下:
- 计算损失
- 更新网络的权重
损失函数:
损失函数接收对(输出,目标)作为输入,计算一个值估计输出与目标之间的距离。
nn包下有一些不同的损失函数。一个简单的损失是nn.MSELoss,它计算的是输入与输出之间的均方误差。
比如:
output=net(input)
target=torch.randn(10)
target=target.view(1,-1)
criterion=nn.MSELoss() loss=criterion(output,target)
print(loss)
out:
tensor(1.1941)
现在,如果你如果按照loss的反向传播方向,使用.grad_fn属性,你将会看到一个计算图如下所示:
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> view -> linear -> relu -> linear -> relu -> linear
-> MSELoss
-> loss
所以,当你调用loss.backward(),整个图关于损失求导,并且图中所有requires_grad=True的tensor将会有它们的.grad属性。Tensor的梯度是累加的。
为了说明这一点,我们跟踪backward的部分步骤:
print(loss.grad_fn) #MSELoss
print(loss.grad_fn.next_functions[0][0]) #Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU
out:
<MseLossBackward object at 0x0000020E2E1289B0>
<AddmmBackward object at 0x0000020E2BF48048>
<ExpandBackward object at 0x0000020E2BF48048>
Backprop
为了反向传播error,我们需要做的就是loss.backward()。你需要清除现有的梯度,否则梯度将会累计到现有梯度上。
现在我们会调用loss.backward(),观察调用backward前后conv1层偏差的梯度。
net.zero_grad()
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
out:
conv1.bias.grad before backward
None # 上一个版本将会是一个为0的向量
conv1.bias.grad after backward
tensor(1.00000e-03 *
[ 4.0788, 1.9541, 5.8585, -2.3754, 2.3815, 1.3351])
现在我们知道了如何使用loss函数
稍后阅读:
神经网络包包含各种模型和loss函数,它们组成了深度神经网络的构建区块。完整的文档在这里。http://pytorch.org/docs/nn
剩下来需要学习的是:
- 更新网络的权重
更新权重
实际中使用的最简单更新规则是随机梯度下降(SGD):
weight=weight-learning_rate*gradient
我们能够使用简单的python代码实现:
learning_rate=0.01
for f in net.parameters():
f.data.sub_(f.grad.data*learning_rate)
然而,当我们使用神经网络,你想要使用各种不同的更新规则比如SGD,Nesterov-SGD,Adam,RMSProp等。为了做到这一点,我们建立了一个小的包torch.optim实现了这些方法。使用它非常简单。
import torch.optim as optim #create your optimizer
optimizer =optim.SGD(net.parameters(),lr=0.01) # in your training loop
optimizer.zero_grad()
output=net(input)
loss=criterion(output,target)
loss.backward()
optimizer.step()
!注意:
手动使用optimizer.zero_grad()来将梯度缓冲变为0。这在Backprop章节进行了解释,因为梯度是累加的。
Neural Networks的更多相关文章
- 【转】Artificial Neurons and Single-Layer Neural Networks
原文:written by Sebastian Raschka on March 14, 2015 中文版译文:伯乐在线 - atmanic 翻译,toolate 校稿 This article of ...
- tensorfolw配置过程中遇到的一些问题及其解决过程的记录(配置SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving)
今天看到一篇关于检测的论文<SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real- ...
- Deep Learning 23:dropout理解_之读论文“Improving neural networks by preventing co-adaptation of feature detectors”
理论知识:Deep learning:四十一(Dropout简单理解).深度学习(二十二)Dropout浅层理解与实现.“Improving neural networks by preventing ...
- 一天一经典Reducing the Dimensionality of Data with Neural Networks [Science2006]
别看本文没有几页纸,本着把经典的文多读几遍的想法,把它彩印出来看,没想到效果很好,比在屏幕上看着舒服.若用蓝色的笔圈出重点,这篇文章中几乎要全蓝.字字珠玑. Reducing the Dimensio ...
- Stanford机器学习笔记-5.神经网络Neural Networks (part two)
5 Neural Networks (part two) content: 5 Neural Networks (part two) 5.1 cost function 5.2 Back Propag ...
- Stanford机器学习笔记-4. 神经网络Neural Networks (part one)
4. Neural Networks (part one) Content: 4. Neural Networks (part one) 4.1 Non-linear Classification. ...
- Notes on Convolutional Neural Networks
这是Jake Bouvrie在2006年写的关于CNN的训练原理,虽然文献老了点,不过对理解经典CNN的训练过程还是很有帮助的.该作者是剑桥的研究认知科学的.翻译如有不对之处,还望告知,我好及时改正, ...
- 《ImageNet Classification with Deep Convolutional Neural Networks》 剖析
<ImageNet Classification with Deep Convolutional Neural Networks> 剖析 CNN 领域的经典之作, 作者训练了一个面向数量为 ...
- 卷积神经网络CNN(Convolutional Neural Networks)没有原理只有实现
零.说明: 本文的所有代码均可在 DML 找到,欢迎点星星. 注.CNN的这份代码非常慢,基本上没有实际使用的可能,所以我只是发出来,代表我还是实践过而已 一.引入: CNN这个模型实在是有些年份了, ...
- Deep Learning 16:用自编码器对数据进行降维_读论文“Reducing the Dimensionality of Data with Neural Networks”的笔记
前言 论文“Reducing the Dimensionality of Data with Neural Networks”是深度学习鼻祖hinton于2006年发表于<SCIENCE > ...
随机推荐
- MySQL数据库常识之储存引擎
我的博客 储存引擎分类 show engines; 这个命令可以查看数据库的数据引擎,可以看到InnoDB是默认的引擎. 命令除了在终端运行,也可以在查询数据库可视化工具中运行. 而,(我是5.7版本 ...
- Python学习之路——类-面向对象编程
类 面向对象编程 通过类获取一个对象的过程 - 实例化 类名()会自动调用类中的__init__方法 类和对象之间的关系? 类 是一个大范围 是一个模子 它约束了事务有哪些属性 但是不能约束具体的值 ...
- FreeRTOS --(1)链表
转载自 https://blog.csdn.net/zhoutaopower/article/details/106550648 Based On FreeRTOS Kernel V10.3.1 1. ...
- sql索引优化思路
[开发]SQL优化思路(以oracle为例) powered by wanglifeng https://www.cnblogs.com/wanglifeng717 单表查询的优化思路 单表查询是最简 ...
- 用浏览器快速开启Docker的体验之旅
互联网科技发展创造了很多奇迹,比如我今天要提到的 docker 技术就是其一.我很早就关注它(在2015年写过这方面的博客),那会儿还只是一个开源项目,现在已经是一个行业事实标准了,它推动了云原生的变 ...
- 一文搞懂 Linux 的 inode!
一个执着于技术的公众号 1.inode 是什么 理解inode,要从文件储存说起. 文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector).每个扇区储存512字节(相当于 ...
- 评价管理后台PC端
1.css动画效果 --2020.12.26 2.remove() --2020.12.28 3.执行顺序 --2020.12.30 4.联动 --2021.01.06 5.奥利给~ --202 ...
- 程序包 applets.user.service.UserService 不存在-2022新项目
一.问题由来 接上一篇文章使用maven进行打包时报中文乱码错误,经过多次尝试后最终解决问题,显示出真正的错误信息如下: 程序包 applets.user.service.UserService 不存 ...
- C#/VB.NET 创建图片超链接
超链接(Hyperlink)可以看做是一个"热点",它可以从当前Web页定义的位置跳转到其他位置,包括当前页的某个位置.Internet.本地硬盘或局域网上的其他文件,甚至跳转到声 ...
- ELK 1.4 logstash各种插件
kibana各种插件: 1.过虑插件 kv (1)KV插件:接收一个键值数据,按照指定分隔符解析为Logstash 事件中的数据结构,放到事件顶层. 常用字段: • field_split ...