Stanford机器学习笔记-5.神经网络Neural Networks (part two)
5 Neural Networks (part two)
content:
5 Neural Networks (part two)
5.1 cost function
5.2 Back Propagation
5.3 神经网络总结
接上一篇4. Neural Networks (part one).本文将先定义神经网络的代价函数,然后介绍逆向传播(Back Propagation: BP)算法,它能有效求解代价函数对连接权重的偏导,最后对训练神经网络的过程进行总结。
5.1 cost function

(注:正则化相关内容参见3.Bayesian statistics and Regularization)
5.2 Back Propagation

(详细推导过程参见反向传播算法,以及李宏毅的机器学习课程:youtube,B站)。

图5-1 BP算法步骤
在实现反向传播算法时,有如下几个需要注意的地方。
- 需要对所有的连接权重(包括偏移单元)初始化为接近0但不全等于0的随机数。如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数(也就是说,所有神经元的激活值都会取相同的值,对于任何输入x 都会有:
 )。随机初始化的目的是使对称失效。具体地,我们可以如图5-2一样随机初始化。(matlab实现见后文代码1)
)。随机初始化的目的是使对称失效。具体地,我们可以如图5-2一样随机初始化。(matlab实现见后文代码1) - 如果实现的BP算法计算出的梯度(偏导数)是错误的,那么用该模型来预测新的值肯定是不科学的。所以,我们应该在应用之前就判断BP算法是否正确。具体的,可以通过数值的方法(如图5-3所示的)计算出较精确的偏导,然后再和BP算法计算出来的进行比较,若两者相差在正常的误差范围内,则BP算法计算出的应该是比较正确的,否则说明算法实现有误。注意在检查完后,在真正训练模型时不应该再运行数值计算偏导的方法,否则将会运行很慢。(matlab实现见后文代码2)
- 用matlab实现时要注意matlab的函数参数不能为矩阵,而连接权重为矩阵,所以在传递初始化连接权重前先将其向量化,再用reshape函数恢复。(见后文代码3)

图5-2 随机初始化连接权重
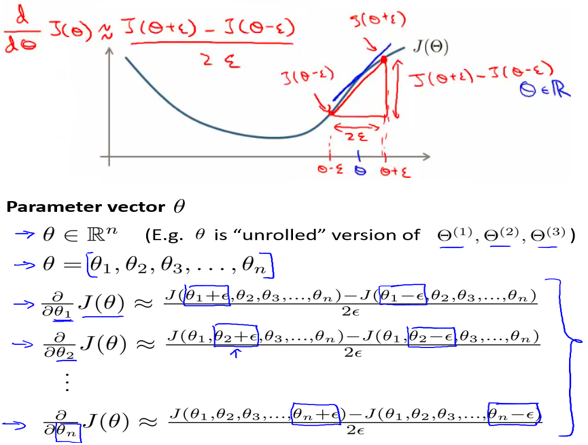
图5-3 数值方法求代价函数偏导的近似值
5.3 神经网络总结
第一步,设计神经网络结构。
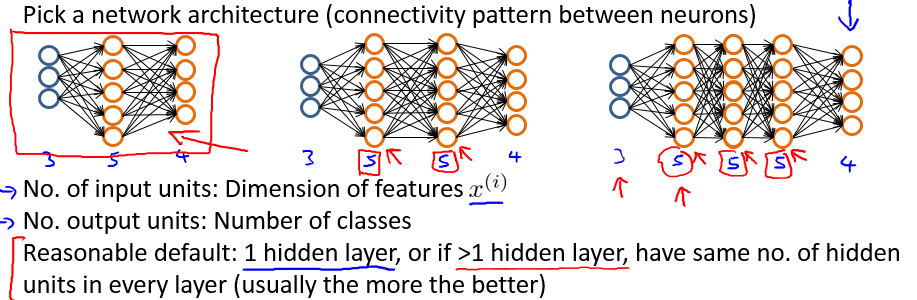
隐藏层单元个数通常都是不确定的。
一般选取神经网络隐藏层单元个数的几个经验公式如下:

参考https://www.zhihu.com/question/46530834
此外,MNIST手写数字识别中给出了以不同的神经网络结构训练的结果,供参考
第二步,实现正向传播(FP)和反向传播算法,这一步包括如下的子步骤。

第三步,用数值方法检查求偏导的正确性

第四步,用梯度下降法或更先进的优化算法求使得代价函数最小的连接权重

在第四步中,由于代价函数是非凸(non-convex)函数,所以在优化过程中可能陷入局部最优值,但不一定比全局最优差很多(如图5-4),在实际应用中通常不是大问题。也会有一些启发式的算法(如模拟退火算法,遗传算法等)来帮助跳出局部最优。
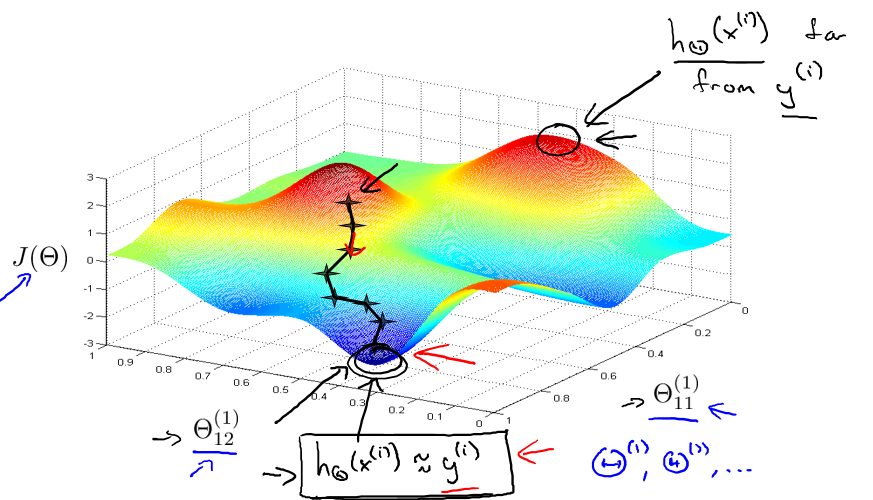
图5-4 陷入局部最优(不一定比全局最优差很多)
代码1:随机初始化连接权重
function W = randInitializeWeights(L_in, L_out)
%RANDINITIALIZEWEIGHTS Randomly initialize the weights of a layer with L_in
%incoming connections and L_out outgoing connections
% W = RANDINITIALIZEWEIGHTS(L_in, L_out) randomly initializes the weights
% of a layer with L_in incoming connections and L_out outgoing
% connections.
%
% Note that W should be set to a matrix of size(L_out, + L_in) as
% the column row of W handles the "bias" terms
% W = zeros(L_out, + L_in); % Instructions: Initialize W randomly so that we break the symmetry while
% training the neural network.
%
% Note: The first row of W corresponds to the parameters for the bias units
% epsilon_init = sqrt() / (sqrt(L_out+L_in));
W = rand(L_out, + L_in) * * epsilon_init - epsilon_init; end
代码2:用数值方法求代价函数对连接权重偏导的近似值
function numgrad = computeNumericalGradient(J, theta)
%COMPUTENUMERICALGRADIENT Computes the gradient using "finite differences"
%and gives us a numerical estimate of the gradient.
% numgrad = COMPUTENUMERICALGRADIENT(J, theta) computes the numerical
% gradient of the function J around theta. Calling y = J(theta) should
% return the function value at theta. % Notes: The following code implements numerical gradient checking, and
% returns the numerical gradient.It sets numgrad(i) to (a numerical
% approximation of) the partial derivative of J with respect to the
% i-th input argument, evaluated at theta. (i.e., numgrad(i) should
% be the (approximately) the partial derivative of J with respect
% to theta(i).)
% numgrad = zeros(size(theta));
perturb = zeros(size(theta));
e = 1e-4;
for p = 1:numel(theta)
% Set perturbation vector
perturb(p) = e;
% Compute Numerical Gradient
numgrad(p) = ( J(theta + perturb) - J(theta - perturb)) / (2*e);
perturb(p) = 0;
end
end
代码3:应用FP和BP算法实现计算隐藏层为1层的神经网络的代价函数以及其对连接权重的偏导数
function [J grad] = nnCostFunction(nn_params, ...
input_layer_size, ...
hidden_layer_size, ...
num_labels, ...
X, y, lambda)
%NNCOSTFUNCTION Implements the neural network cost function for a two layer
%neural network which performs classification
% [J grad] = NNCOSTFUNCTON(nn_params, hidden_layer_size, num_labels, ...
% X, y, lambda) computes the cost and gradient of the neural network. The
% parameters for the neural network are "unrolled" into the vector
% nn_params and need to be converted back into the weight matrices.
%
% The returned parameter grad should be a "unrolled" vector of the
% partial derivatives of the neural network.
% % Reshape nn_params back into the parameters Theta1 and Theta2, the weight matrices
% for our 2 layer neural network:Theta1: 1->2; Theta2: 2->3
Theta1 = reshape(nn_params(1:hidden_layer_size * (input_layer_size + 1)), ...
hidden_layer_size, (input_layer_size + 1)); Theta2 = reshape(nn_params((1 + (hidden_layer_size * (input_layer_size + 1))):end), ...
num_labels, (hidden_layer_size + 1)); % Setup some useful variables
m = size(X, 1);
J = 0;
Theta1_grad = zeros(size(Theta1));
Theta2_grad = zeros(size(Theta2)); % Note: The vector y passed into the function is a vector of labels
% containing values from 1..K. You need to map this vector into a
% binary vector of 1's and 0's to be used with the neural network
% cost function. for i = 1:m
% compute activation by Forward Propagation
a1 = [1; X(i,:)'];
z2 = Theta1 * a1;
a2 = [1; sigmoid(z2)];
z3 = Theta2 * a2;
h = sigmoid(z3); yy = zeros(num_labels,1);
yy(y(i)) = 1; % 训练集的真实值yy J = J + sum(-yy .* log(h) - (1-yy) .* log(1-h)); % Back Propagation
delta3 = h - yy;
delta2 = (Theta2(:,2:end)' * delta3) .* sigmoidGradient(z2); %注意要除去偏移单元的连接权重 Theta2_grad = Theta2_grad + delta3 * a2';
Theta1_grad = Theta1_grad + delta2 * a1';
end J = J / m + lambda * (sum(sum(Theta1(:,2:end) .^ 2)) + sum(sum(Theta2(:,2:end) .^ 2))) / (2*m); Theta2_grad = Theta2_grad / m;
Theta2_grad(:,2:end) = Theta2_grad(:,2:end) + lambda * Theta2(:,2:end) / m; % regularized nn Theta1_grad = Theta1_grad / m;
Theta1_grad(:,2:end) = Theta1_grad(:,2:end) + lambda * Theta1(:,2:end) / m; % regularized nn % Unroll gradients
grad = [Theta1_grad(:) ; Theta2_grad(:)]; end
Stanford机器学习笔记-5.神经网络Neural Networks (part two)的更多相关文章
- Stanford机器学习笔记-4. 神经网络Neural Networks (part one)
4. Neural Networks (part one) Content: 4. Neural Networks (part one) 4.1 Non-linear Classification. ...
- Stanford机器学习---第五讲. 神经网络的学习 Neural Networks learning
原文 http://blog.csdn.net/abcjennifer/article/details/7758797 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- 论文笔记:Diffusion-Convolutional Neural Networks (传播-卷积神经网络)
Diffusion-Convolutional Neural Networks (传播-卷积神经网络)2018-04-09 21:59:02 1. Abstract: 我们提出传播-卷积神经网络(DC ...
- 【论文笔记】Progressive Neural Networks 渐进式神经网络
Progressive NN Progressive NN是第一篇我看到的deepmind做这个问题的.思路就是说我不能忘记第一个任务的网络,同时又能使用第一个任务的网络来做第二个任务. 为了不忘记之 ...
- 论文笔记(1)-Dropout-Improving neural networks by preventing co-adaptation of feature detectors
Improving neural networks by preventing co-adaptation of feature detectors 是Hinton在2012年6月份发表的,从这篇文章 ...
- 斯坦福机器学习视频笔记 Week4 & Week5 神经网络 Neural Networks
神经网络是一种受大脑工作原理启发的模式. 它在许多应用中广泛使用:当您的手机解释并理解您的语音命令时,很可能是神经网络正在帮助理解您的语音; 当您兑现支票时,自动读取数字的机器也使用神经网络. Non ...
- Coursera 机器学习 第5章 Neural Networks: Learning 学习笔记
5.1节 Cost Function神经网络的代价函数. 上图回顾神经网络中的一些概念: L 神经网络的总层数. sl 第l层的单元数量(不包括偏差单元). 2类分类问题:二元分类和多元分类. 上 ...
- 机器学习(六)--------神经网络(Neural Networks)
无论是线性回归还是逻辑回归都有这样一个缺点,即:当特征太多时, 计算的负荷会非常大. 比如识别图像,是否是一辆汽车,可能就需要判断太多像素. 这时候就需要神经网络. 神经网络是模拟人类大脑的神经网络, ...
- 【原】Coursera—Andrew Ng机器学习—Week 4 习题—Neural Networks 神经网络
[1] Answer:C [2] Answer:D 第二层要输出四个元素a1 a2 a3 a4.输入x有两个,加一个x0是三个.所以是4 * 3 [3] Answer:C [4] Answer:C [ ...
随机推荐
- angularjs封装bootstrap官网的时间插件datetimepicker
背景:angular与jquery类库的协作 第三方类库中,不得不提的是大名鼎鼎的jquery,现在基本上已经是国内web开发的必修工具了.它灵活的dom操作,让很多web开发人员欲罢不能.再加上已经 ...
- 【zepto学习笔记01】核心方法$()
前言 我们移动端基本使用zepto了,而我也从一个小白变成稍微靠谱一点的前端了,最近居然经常要改到zepto源码但是,我对zepto不太熟悉,其实前端水准还是不够,所以便私下偷偷学习下吧,别被发现了 ...
- [deviceone开发]-模仿Zaker的示例
一.简介 这个示例模仿zaker这个App,主要的界面基本都完成,用到了各种deviceone提供的ui组件,比如GridView,ListView,ScrollView,ViewShower等等.初 ...
- Javascript 中的window.parent ,window.top,window.self 详解
在应用有frameset或者iframe的页面时,parent是父窗口,top是最顶级父窗口(有的窗口中套了好几层frameset或者iframe),self是当前窗口, opener是用open方法 ...
- Eclipse CDT Linux下内存分析 实战历险
C++产品开发,上线集成时,都需要内存泄露.覆盖率等检测,这些在Windows下都有很好的工具,如 Visual Studio: 这个内置了很多的工具 Devpartner: VC6时BoundChe ...
- iOS端项目注释规范附统一代码块
代码的注释经常被人忽略,以至于在后期维护的时候较为困难.我们准备在XX项目开始之前制定一套规范的注释体系,致力于达到就算维护人员改变也能快速上手的效果. 1.属性注释 属性注释 使用 /** 注释*/ ...
- iOS开发之UIAlertView与UIAlertController的详尽用法说明
本文将从四个方面对IOS开发中UIAlertView与UIAlertController的用法进行讲解: 一.UIAlertView与UIAlertController是什么东东? 二.我们为什么要用 ...
- iOS 学习资源
这份学习资料是为 iOS 初学者所准备的, 旨在帮助 iOS 初学者们快速找到适合自己的学习资料, 节省他们搜索资料的时间, 使他们更好的规划好自己的 iOS 学习路线, 更快的入门, 更准确的定位的 ...
- [转]从JVM角度看线程安全与垃圾收集
线程安全 Java内存模型中,程序(进程)拥有一块内存空间,可以被所有的线程共享,即MainMemory(主内存):而每个线程又有一块独立的内存空间,即WorkingMemory(工作内存).普通情况 ...
- 集合迭代器快速失败行为及CopyOnWriteArrayList
以下内容基于jdk1.7.0_79源码: 什么是集合迭代器快速失败行为 以ArrayList为例,在多线程并发情况下,如果有一个线程在修改ArrayList集合的结构(插入.移除...),而另一个线程 ...