scrapy操作mysql/批量下载图片
1.操作mysql
items.py

meiju.py
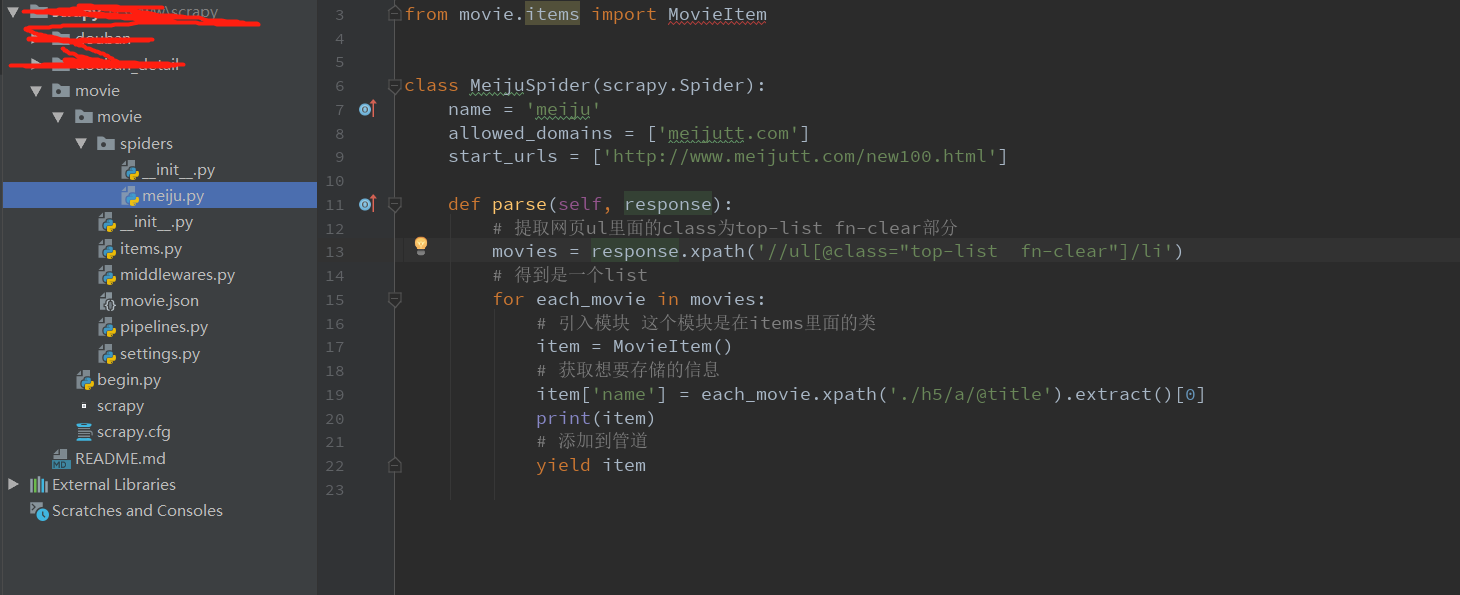
3.piplines.py

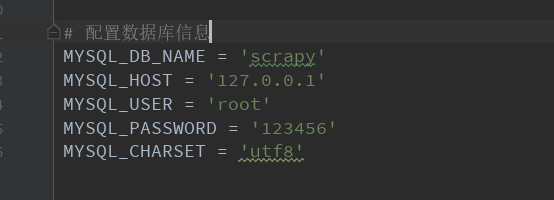
4.settings.py
--------------------------------------------------------------------------------------------------------------------------
批量下载图片。分类
网站:https://movie.douban.com/top250
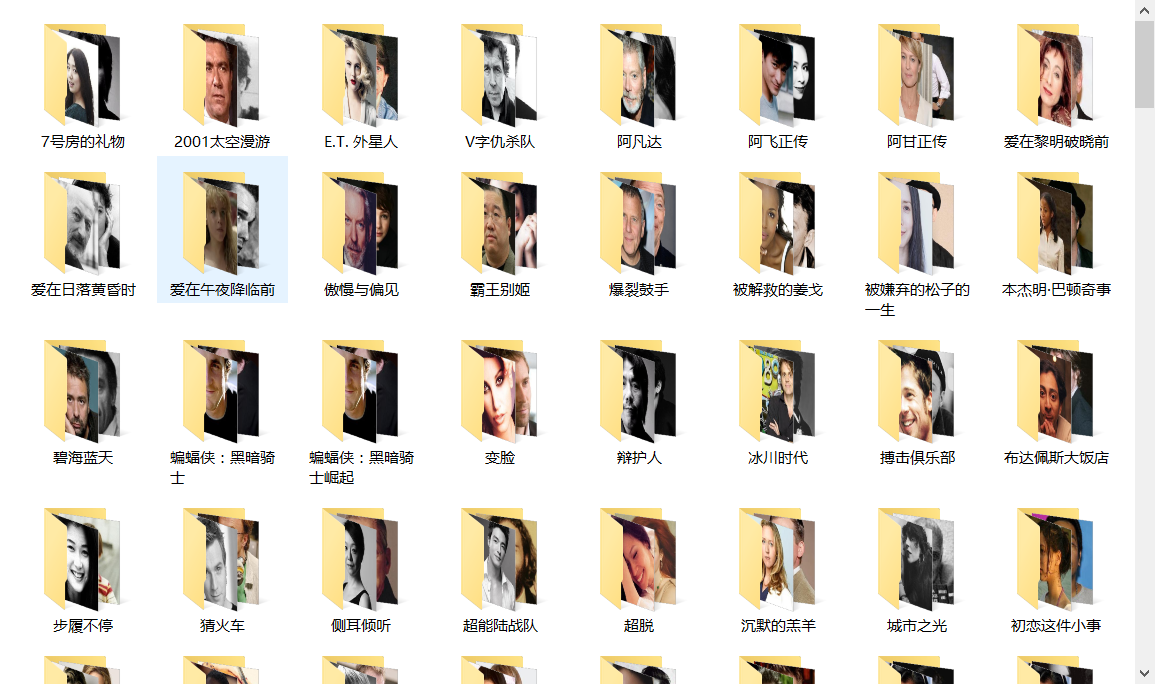
需求:按电影分类,获取里面的演职员图片。并存入各自的分类当中
效果:
代码
因为我们主要工作是下载。不存入数据库。存入数据库的话可以参考上面部分。
现在只需要修改spiders/xxx_spiders.py文件。就是开启项目适合生成的文件
我的是这个
以下是这个文件夹的代码。
# -*- coding: utf-8 -*-
import scrapy
import os
import urllib.request
import re class DoubanDetailSpidersSpider(scrapy.Spider):
name = 'douban_detail_spiders'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250'] file_path = "D:\\www\\scrapy\\douban_detail\\image\\" def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li") for i_item in movie_list:
# 封面图
master_pic_path = i_item.xpath(".//div[@class='pic']//a//img/@src").extract_first()
# 文件名
name = i_item.xpath(".//div[@class='info']//a/span[1]/text()").extract_first()
# 创建文件夹
self.fileIsBeing(name)
# 详情连接
detail_url = i_item.xpath(".//div[@class='hd']//a/@href").extract_first()
# 获取详情里面内容
# detail_link = response.xpath(".//div[@class='hd']//a/@href").extract()
# for link in detail_link:
# 这里是进入二级页面操作,在for循环里面。
yield scrapy.Request(detail_url, meta={'name': name}, callback=self.detail_parse, dont_filter=True) # 解析下一页
next_link = response.xpath("//div[@class='article']//div[@class='paginator']//span[@class='next']/link/@href").extract()
print(next_link)
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250" + next_link, callback=self.parse) # 判断文件是否存在
# 不存在则创建
def fileIsBeing(self, name):
path = self.file_path + name
bool = os.path.exists(path)
if not(bool):
os.mkdir(path)
return path # 解析详情里面的数据 获取二级页面内容操作。主要获取图片
def detail_parse(self, response):
name = response.meta['name']
print(name)
movie_prople_list = response.xpath("//div[@id='celebrities']//ul[@class='celebrities-list from-subject __oneline']//li")
for i_mov_item in movie_prople_list:
background_img = i_mov_item.xpath(".//div[@class='avatar']/@style").extract_first()
user_name = i_mov_item.xpath(".//div[@class='info']//a/@title").extract_first()
img_file_name = "%s.jpg" % user_name # 工作人员
img_url = self.txt_wrap_by('(', ')', background_img) # 图片地址
print(img_file_name)
file_path = os.path.join(self.file_path+name, img_file_name)
urllib.request.urlretrieve(img_url, file_path)
# print(img_file_name) # 截取字符串中间部分
def txt_wrap_by(self, start_str, end, html):
start = html.find(start_str)
if start >= 0:
start += len(start_str)
end = html.find(end, start)
if end >= 0:
return html[start:end].strip()
码云:https://gitee.com/chenrunxuan/scrapy
scrapy操作mysql/批量下载图片的更多相关文章
- scrapy批量下载图片
# -*- coding: utf-8 -*- import scrapy from rihan.items import RihanItem class RihanspiderSpider(scra ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 【Python】nvshens按目录批量下载图片爬虫1.00(单线程版)
# nvshens按目录批量下载图片爬虫1.00(单线程版) from bs4 import BeautifulSoup import requests import datetime import ...
- javaWeb 批量下载图片
批量下载网页图片 CreateTime--2017年9月26日15:40:43 Author:Marydon 所用技术:javascript.java 测试浏览器:chrome 开发工具:Ecli ...
- C++ 根据图片url 批量 下载图片
最近需要用到根据图片URL批量下载到本地的操作.查找了相关资料,记录在这儿. 1.首先在CSV文件中提取出url ifstream fin("C:\\Users\\lenovo\\Deskt ...
- 用python批量下载图片
一 写爬虫注意事项 网络上有不少有用的资源, 如果需要合理的用爬虫去爬取资源是合法的,但是注意不要越界,前一阶段有个公司因为一个程序员写了个爬虫,导致公司200多个人被抓,所以先进入正题之前了解下什么 ...
- python——批量下载图片
前言 批量下载网页上的图片需要三个步骤: 获取网页的URL 获取网页上图片的URL 下载图片 例子 from html.parser import HTMLParser import urllib.r ...
- 利用Node 搭配uglify-js压缩js文件,批量下载图片到本地
Node的便民技巧-- 压缩代码 下载图片 压缩代码 相信很多前端的同学都会在上线前压缩JS代码,现在的Gulp Webpack Grunt......都能轻松实现.但问题来了,这些都不会,难道就要面 ...
- scrapy中的ImagePipeline下载图片到本地、并提取本地的保存地址
通过scrapy内置到ImagePipeline下载图片到本地 在settings中打开 ITEM_PIPELINES的注释,并在这里面加入 'scrapy.pipelines.images.Imag ...
随机推荐
- 后端统一处理返回前端日期LocalDateTime格式化去T,Long返回前端损失精度问题
一.前言 我们在实际开发中肯定会遇到后端的时间传到前端是这个样子的:2022-08-02T15:43:50 这个时候前后端就开始踢皮球了,!! 后端说:前端来做就可! 前端说:后端来做就可! 作为一名 ...
- 5.31 NOI 模拟
\(T1\ Beauty\) \(T2\ Jump\) 考场上一开始想的是树套树,然后我看到了\(128MB,\)好 于是乎附上\(56pts\ MLE\)代码在空间\(512MB\)可以获得\(84 ...
- 【PHP库】phpseclib - sftp远程文件操作
需求场景说明 对接的三方商家需要进行文件传输,并且对方提供的方式是 sftp 的服务器账号,我们需根据他们提供的目录进行下载和上传指定文件. 安装 composer require phpseclib ...
- OpenSSF的开源软件风险评估工具:Scorecards
对于IT从业者来说,Marc Andreessen 十年前提出"软件吞噬世界"的观点早已耳熟能详.无论是私人生活还是公共领域,软件为现代社会的方方面面提供动力,对现代经济和国家安全 ...
- Redis 05 集合
参考源 https://www.bilibili.com/video/BV1S54y1R7SB?spm_id_from=333.999.0.0 版本 本文章基于 Redis 6.2.6 Set 中的值 ...
- error setting certificate verify locations
描述 在使用 git clone 克隆 GitHub 或者 Gitee 上的项目时,报如下错误: error setting certificate verify locations: CAfile: ...
- Excel 插入嵌入式图表和独立图表的方法
描述 嵌入式图表:是一种与当前工作表相同位置的图表,且悬浮在表格之上,不受表格限制,因此称之为嵌入式图表. 独立图表:是独立于当前工作表的图表,打印时,需要单独将其打印出来. 插入独立图表的图文教程: ...
- JavaScript基础回顾知识点记录2
js 使用嵌套for循环输出三角形 for(var i=0; i<5; i++){ //正三角 // for(var j=0; j<i+1; j++){ // document.write ...
- DataRow修改某一Cell的值
发现ItemArray并不能改变DataRow的值,之前用ItemArray来复制整行数据的操作. 实际上可以直接用DataRow[]就可以直接改变对应Cell的值.
- windows系统-不能打印问题:PDF打印软件正常打开PDF文件,点击打印后软件卡死并提示未响应(No response)
电脑突然出现PDF软件卡死问题,导致无法打印:初步思路记录: 导致问题出现的原因可能为文件问题(文件过大,打印机容量小).打印机问题(打印机未连接.故障等).电脑驱动问题(打印机驱动损坏).电脑补丁问 ...