scrapy操作mysql/批量下载图片
1.操作mysql
items.py

meiju.py
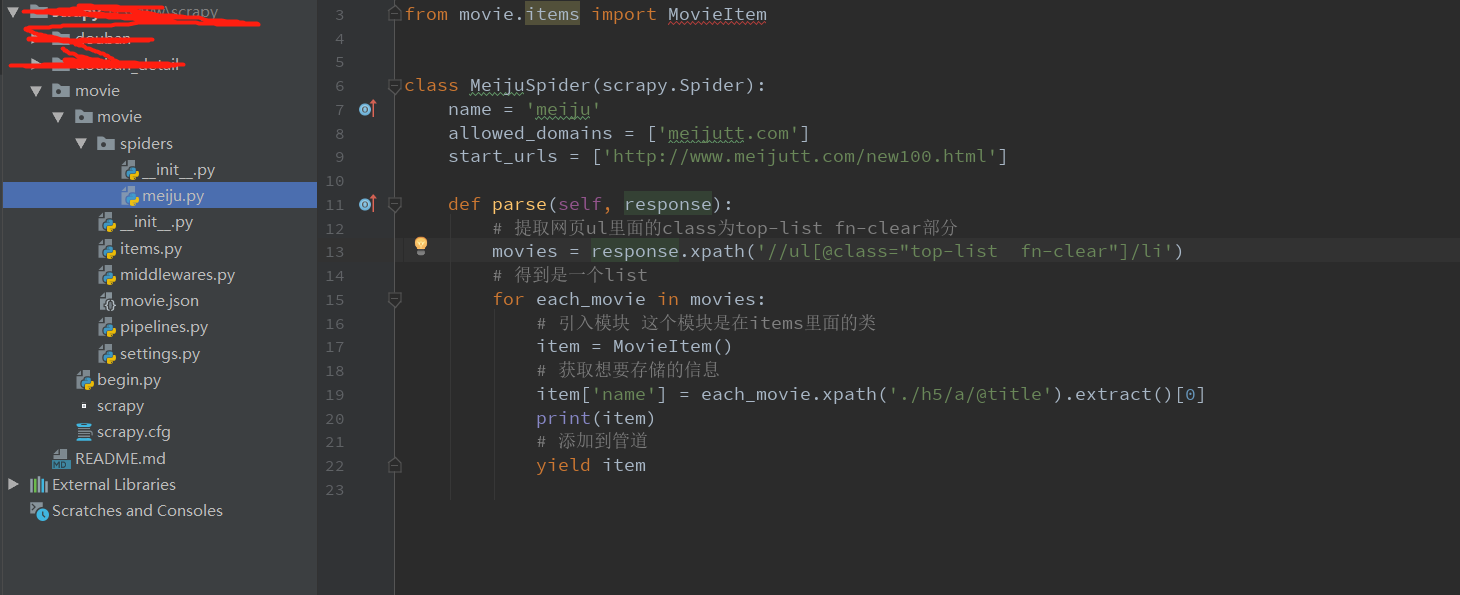
3.piplines.py

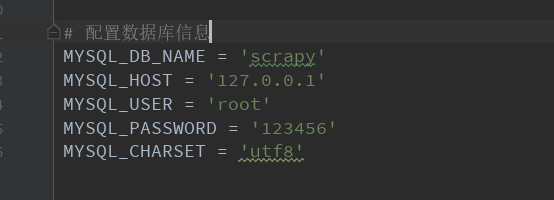
4.settings.py
--------------------------------------------------------------------------------------------------------------------------
批量下载图片。分类
网站:https://movie.douban.com/top250
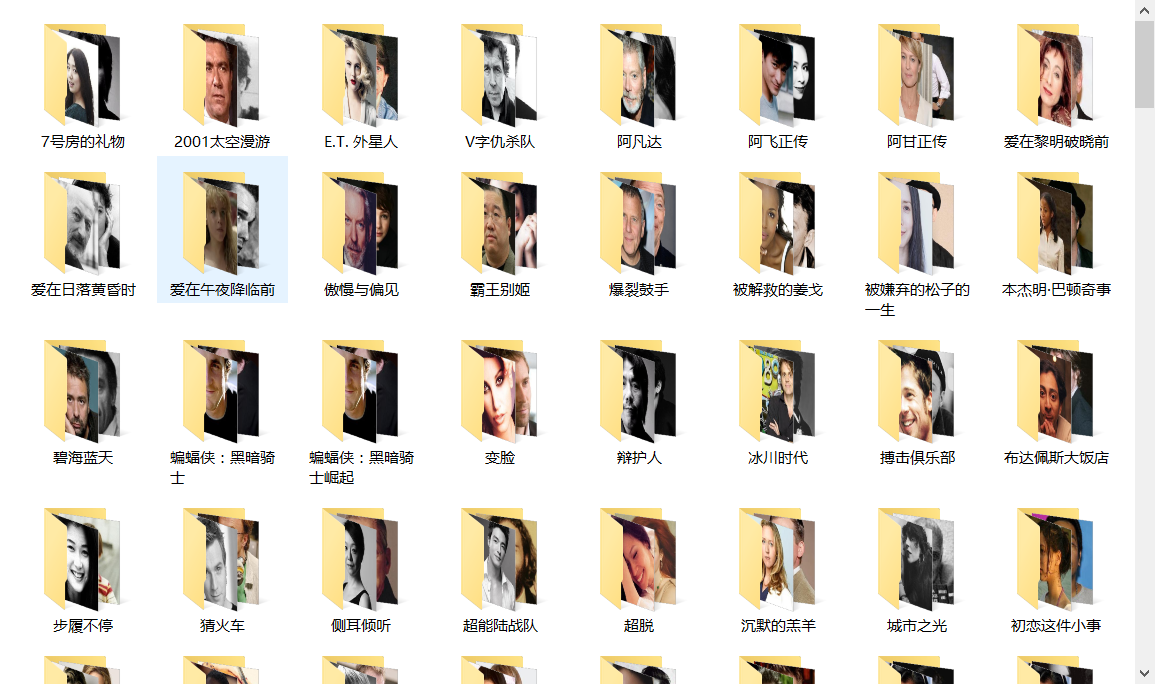
需求:按电影分类,获取里面的演职员图片。并存入各自的分类当中
效果:
代码
因为我们主要工作是下载。不存入数据库。存入数据库的话可以参考上面部分。
现在只需要修改spiders/xxx_spiders.py文件。就是开启项目适合生成的文件
我的是这个
以下是这个文件夹的代码。
# -*- coding: utf-8 -*-
import scrapy
import os
import urllib.request
import re class DoubanDetailSpidersSpider(scrapy.Spider):
name = 'douban_detail_spiders'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250'] file_path = "D:\\www\\scrapy\\douban_detail\\image\\" def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li") for i_item in movie_list:
# 封面图
master_pic_path = i_item.xpath(".//div[@class='pic']//a//img/@src").extract_first()
# 文件名
name = i_item.xpath(".//div[@class='info']//a/span[1]/text()").extract_first()
# 创建文件夹
self.fileIsBeing(name)
# 详情连接
detail_url = i_item.xpath(".//div[@class='hd']//a/@href").extract_first()
# 获取详情里面内容
# detail_link = response.xpath(".//div[@class='hd']//a/@href").extract()
# for link in detail_link:
# 这里是进入二级页面操作,在for循环里面。
yield scrapy.Request(detail_url, meta={'name': name}, callback=self.detail_parse, dont_filter=True) # 解析下一页
next_link = response.xpath("//div[@class='article']//div[@class='paginator']//span[@class='next']/link/@href").extract()
print(next_link)
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250" + next_link, callback=self.parse) # 判断文件是否存在
# 不存在则创建
def fileIsBeing(self, name):
path = self.file_path + name
bool = os.path.exists(path)
if not(bool):
os.mkdir(path)
return path # 解析详情里面的数据 获取二级页面内容操作。主要获取图片
def detail_parse(self, response):
name = response.meta['name']
print(name)
movie_prople_list = response.xpath("//div[@id='celebrities']//ul[@class='celebrities-list from-subject __oneline']//li")
for i_mov_item in movie_prople_list:
background_img = i_mov_item.xpath(".//div[@class='avatar']/@style").extract_first()
user_name = i_mov_item.xpath(".//div[@class='info']//a/@title").extract_first()
img_file_name = "%s.jpg" % user_name # 工作人员
img_url = self.txt_wrap_by('(', ')', background_img) # 图片地址
print(img_file_name)
file_path = os.path.join(self.file_path+name, img_file_name)
urllib.request.urlretrieve(img_url, file_path)
# print(img_file_name) # 截取字符串中间部分
def txt_wrap_by(self, start_str, end, html):
start = html.find(start_str)
if start >= 0:
start += len(start_str)
end = html.find(end, start)
if end >= 0:
return html[start:end].strip()
码云:https://gitee.com/chenrunxuan/scrapy
scrapy操作mysql/批量下载图片的更多相关文章
- scrapy批量下载图片
# -*- coding: utf-8 -*- import scrapy from rihan.items import RihanItem class RihanspiderSpider(scra ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 【Python】nvshens按目录批量下载图片爬虫1.00(单线程版)
# nvshens按目录批量下载图片爬虫1.00(单线程版) from bs4 import BeautifulSoup import requests import datetime import ...
- javaWeb 批量下载图片
批量下载网页图片 CreateTime--2017年9月26日15:40:43 Author:Marydon 所用技术:javascript.java 测试浏览器:chrome 开发工具:Ecli ...
- C++ 根据图片url 批量 下载图片
最近需要用到根据图片URL批量下载到本地的操作.查找了相关资料,记录在这儿. 1.首先在CSV文件中提取出url ifstream fin("C:\\Users\\lenovo\\Deskt ...
- 用python批量下载图片
一 写爬虫注意事项 网络上有不少有用的资源, 如果需要合理的用爬虫去爬取资源是合法的,但是注意不要越界,前一阶段有个公司因为一个程序员写了个爬虫,导致公司200多个人被抓,所以先进入正题之前了解下什么 ...
- python——批量下载图片
前言 批量下载网页上的图片需要三个步骤: 获取网页的URL 获取网页上图片的URL 下载图片 例子 from html.parser import HTMLParser import urllib.r ...
- 利用Node 搭配uglify-js压缩js文件,批量下载图片到本地
Node的便民技巧-- 压缩代码 下载图片 压缩代码 相信很多前端的同学都会在上线前压缩JS代码,现在的Gulp Webpack Grunt......都能轻松实现.但问题来了,这些都不会,难道就要面 ...
- scrapy中的ImagePipeline下载图片到本地、并提取本地的保存地址
通过scrapy内置到ImagePipeline下载图片到本地 在settings中打开 ITEM_PIPELINES的注释,并在这里面加入 'scrapy.pipelines.images.Imag ...
随机推荐
- EPLAN中的edz文件的用法
1 EDZ 文件的定义 EDZ 是 EPLAN Data Archive Zipped(EPLAN 数据压缩文件包)的缩写,最早是专门为西门子定制的,现在已经 成为 EPLAN 中一种标准的部件 ...
- BMP位图之8位位图(三)
起始结构 typedef struct tagBITMAPFILEHEADER { WORD bfType; //类型名,字符串"BM", DWORD bfSize; //文件大小 ...
- 什么是 DevOps?看这一篇就够了!
本文作者:Daniel Hu 个人主页:https://www.danielhu.cn/ 目录 一.前因 二.记忆 三.他们说-- 3.1.Atlassian 回答"什么是 DevOps?& ...
- 手把手教你定位线上MySQL锁超时问题,包教包会
昨晚我正在床上睡得着着的,突然来了一条短信. 什么?线上的订单无法取消! 我赶紧登录线上系统,查看业务日志. 发现有MySQL锁超时的错误日志. 不用想,肯定有另一个事务正在修改这条订单,持有这条订单 ...
- 【lwip】06-网络接口层分析
目录 前言 6.1 概念引入 6.2 网络接口层数据概念流图 6.3 网卡收包程序流图 6.4 网卡数据结构 6.4.1 struct netif源码 6.4.2 字段分析 6.4.2.1 网卡链表 ...
- Linux之Samba服务器搭建
一,samba的基本概念 SMB(Server Messages Block,信息服务块)是一种在局域网上共享文件和打印机的一种通信协议,它为局域网内的不同计算机之间提供文件及打印机等资源的共享服务. ...
- 通过Quartz 进行定时任务
小记一下通过Quartz 进行轮询数据库从而进行自动打印的需求. 一:首先通过NuGet引用Quartz,Quartz依赖Common.Logging和Common.Logging.Log4Net12 ...
- Python入门系列(十)一篇学会python文件处理
文件处理 在Python中处理文件的关键函数是open()函数.有四种不同的方法(模式)来打开一个文件 "r" - 读取 - 默认值.打开一个文件进行读取,如果文件不存在则出错. ...
- docker-compose入门--翻译
在这一页,你将学习到如何构建一个简单的python的web应用,并通过Docker compose来运行.这个应用程序使用的是Flask框架,并维护着一个存储在reids里的点击计数器.由于这个案例使 ...
- 国内外各大物联网IoT平台鸟瞰和资源导航
一.国内外物联网平台 国内 百度物接入IoT Hub 阿里云物联网套件 智能硬件开放平台 京东微联 机智云IoT物联网云服务平台及智能硬件自助开发平台 庆科云FogCloud Ablecloud物联网 ...