Java安全之反序列化(1)
序列化与反序列化
概述
Java序列化是指把Java对象转换为字节序列的过程;这串字符可能被储存/发送到任何需要的位置,在适当的时候,再将它转回原本的 Java 对象,而Java反序列化是指把字节序列恢复为Java对象的过程。
为什么需要序列化与反序列化
当两个进程进行远程通信时,可以相互发送各种类型的数据,包括文本、图片、音频、视频等, 而这些数据都会以二进制序列的形式在网络上传送。那么当两个Java进程进行通信时,能否实现进程间的对象传送呢?答案是可以的。如何做到呢?这就需要Java序列化与反序列化了。换句话说,一方面,发送方需要把这个Java对象转换为字节序列,然后在网络上传送;另一方面,接收方需要从字节序列中恢复出Java对象
Java 提供了两个类 java.io.ObjectOutputStream 和 java.io.ObjectInputStream 来实现序列化和反序列化的功能,其中 ObjectInputStream 用于恢复那些已经被序列化的对象,ObjectOutputStream 将 Java 对象的原始数据类型和图形写入 OutputStream。
在 Java 的类中,必须要实现 java.io.Serializable 或 java.io.Externalizable 接口才可以使用,而实际上 Externalizable 也是实现了 Serializable 接口
ObjectOutputStream
ObjectOutputStream 继承的父类或实现的接口如下:
- 父类
OutputStream:所有字节输出流的顶级父类,用来接收输出的字节并发送到某些接收器(sink)。 - 接口
ObjectOutput:ObjectOutput 扩展了 DataOutput 接口,DataOutput 接口提供了将数据从任何 Java 基本类型转换为字节序列并写入二进制流的功能,ObjectOutput 在 DataOutput 接口基础上提供了writeObject方法,也就是类(Object)的写入。 - 接口 ObjectStreamConstants:定义了一些在对象序列化时写入的常量。常见的一些的比如
STREAM_MAGIC、STREAM_VERSION等。
通过这个类的父类及父接口,我们大概可以理解这个类提供的功能:能将 Java 中的类、数组、基本数据类型等对象转换为可输出的字节,也就是反序列化。接下来看一下这个类中几个关键方法
writeObject
这是 ObjectOutputStream 对象的核心方法之一,用来将一个对象写入输出流中,任何对象,包括字符串和数组,都是用 writeObject 写入到流中的。
之前说过,序列化的过程,就是将一个对象当前的状态描述为字节序列的过程,也就是 Object -> OutputStream 的过程,这个过程由 writeObject 实现。writeObject 方法负责为指定的类编写其对象的状态,以便在后面可以使用与之对应 readObject 方法来恢复它
writeUnshared
用于将非共享对象写入 ObjectOutputStream,并将给定的对象作为刷新对象写入流中。
使用 writeUnshared 方法会使用 BlockDataOutputStream 的新实例进行序列化操作,不会使用原来 OutputStream 的引用对象。
writeObject0
writeObject 和 writeUnshared 实际上调用 writeObject0 方法,也就是说 writeObject0是上面两个方法的基础实现。具体的实现流程将会在后面再进行详细研究。
writeObjectOverride
如果 ObjectOutputStream 中的 enableOverride 属性为 true,writeObject 方法将会调用 writeObjectOverride,这个方法是由 ObjectOutputStream 的子类实现的。
在由完全重新实现 ObjectOutputStream 的子类完成序列化功能时,将会调用实现类的 writeObjectOverride 方法进行处理。
ObjectInputStream
ObjectInputStream 继承的父类或实现的接口如下:
- 父类
InputStream:所有字节输入流的顶级父类。 - 接口
ObjectInput:ObjectInput 扩展了 DataInput 接口,DataInput 接口提供了从二进制流读取字节并将其重新转换为 Java 基础类型的功能,ObjectInput 额外提供了readObject方法用来读取类。 - 接口
ObjectStreamConstants:同上。
ObjectInputStream 实现了反序列化功能,看一下其中的关键方法。
readObject
从 ObjectInputStream 读取一个对象,将会读取对象的类、类的签名、类的非 transient 和非 static 字段的值,以及其所有父类类型。
我们可以使用 writeObject 和 readObject 方法为一个类重写默认的反序列化执行方,所以其中 readObject 方法会 “传递性” 的执行,也就是说,在反序列化过程中,会调用反序列化类的 readObject 方法,以完整的重新生成这个类的对象。
readUnshared
从 ObjectInputStream 读取一个非共享对象。 此方法与 readObject 类似,不同点在于readUnshared 不允许后续的 readObject 和 readUnshared 调用引用这次调用反序列化得到的对象。
readObject0
readObject 和 readUnshared 实际上调用 readObject0 方法,readObject0是上面两个方法的基础实现。
readObjectOverride
由 ObjectInputStream 子类调用,与 writeObjectOverride 一致。
通过上面对 ObjectOutputStream 和 ObjectInputStream 的了解,两个类的实现几乎是一种对称的、双生的方式进行
反序列化漏洞
一个类想要实现序列化和反序列化,必须要实现 java.io.Serializable 或 java.io.Externalizable 接口。
Serializable 接口是一个标记接口,标记了这个类可以被序列化和反序列化,而 Externalizable 接口在 Serializable 接口基础上,又提供了 writeExternal 和 readExternal 方法,用来序列化和反序列化一些外部元素。
其中,如果被序列化的类重写了 writeObject 和 readObject 方法,Java 将会委托使用这两个方法来进行序列化和反序列化的操作。
正是因为这个特性,导致反序列化漏洞的出现:在反序列化一个类时,如果其重写了 readObject 方法,程序将会调用它,如果这个方法中存在一些恶意的调用,则会对应用程序造成危害。
在这里我们利用写一个简单的测试程序,如下代码创建了 Person 类,实现了 Serializable 接口,并重写了 readObject 方法,在方法中使用 Runtime 执行命令弹出计算器
public class Person implements Serializable {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException {
Runtime.getRuntime().exec("calc.exe");
}
}
然后我们将这个类序列化并写在文件中,随后对其进行反序列化,就触发了命令执行
public class SerializableTest {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Person person = new Person("gk0d", 24);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("test.txt"));
oos.writeObject(person);
oos.close();
FileInputStream fis = new FileInputStream("test.txt");
ObjectInputStream ois = new ObjectInputStream(fis);
ois.readObject();
ois.close();
}
}
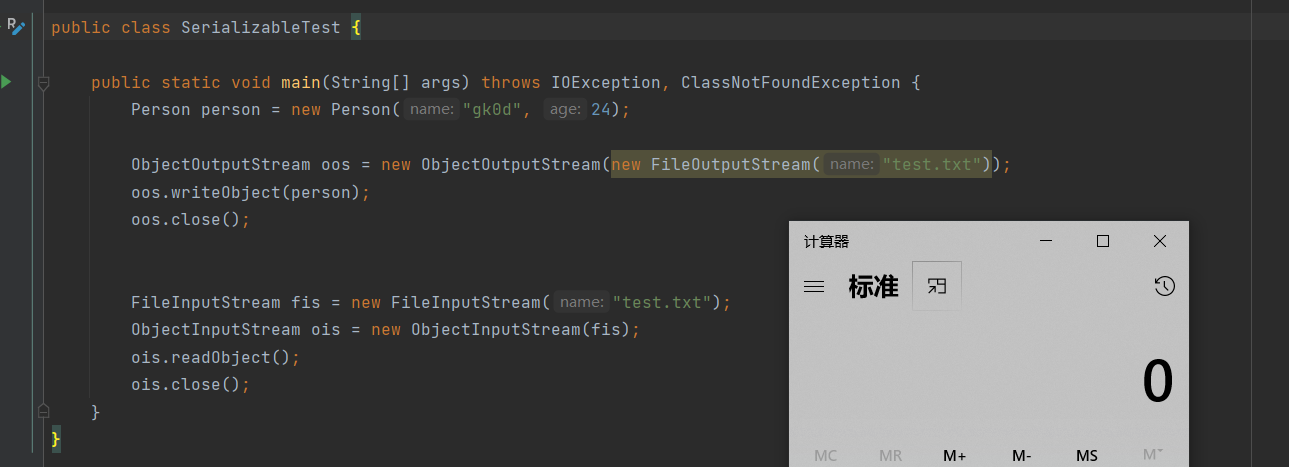
那为什么我们重写了readObject就会执行呢?来看一下 java.io.ObjectInputStream#readObject() 方法的具体实现代码。
readObject 方法实际调用 readObject0 方法反序列化字符串
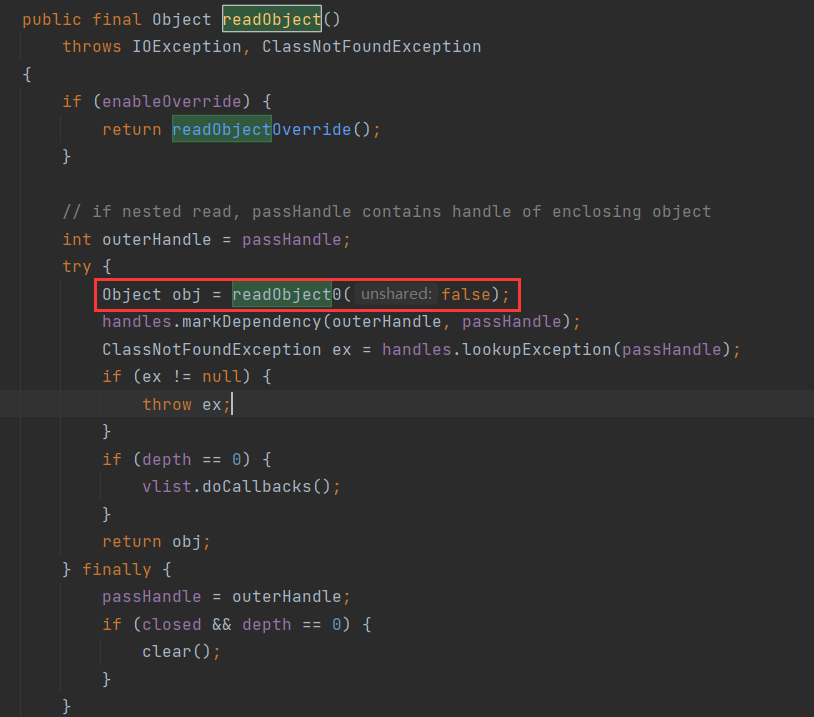
readObject0 方法以字节的方式去读,如果读到 0x73,则代表这是一个对象的序列化数据,将会调用 readOrdinaryObject 方法进行处理
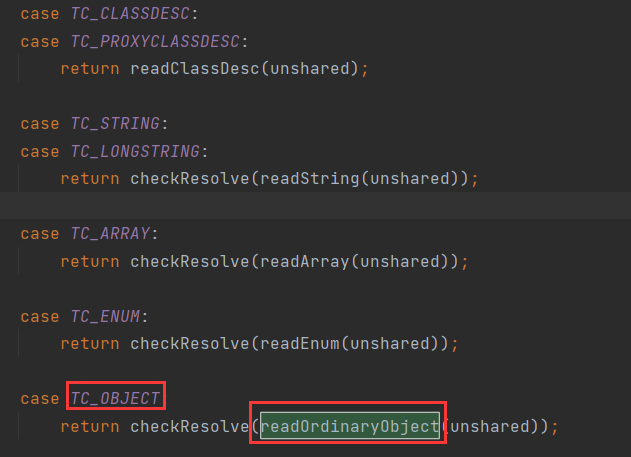
readOrdinaryObject 方法会调用 readClassDesc 方法读取类描述符,并根据其中的内容判断类是否实现了 Externalizable 接口,如果是,则调用 readExternalData 方法去执行反序列化类中的 readExternal,如果不是,则调用 readSerialData 方法去执行类中的 readObject 方法
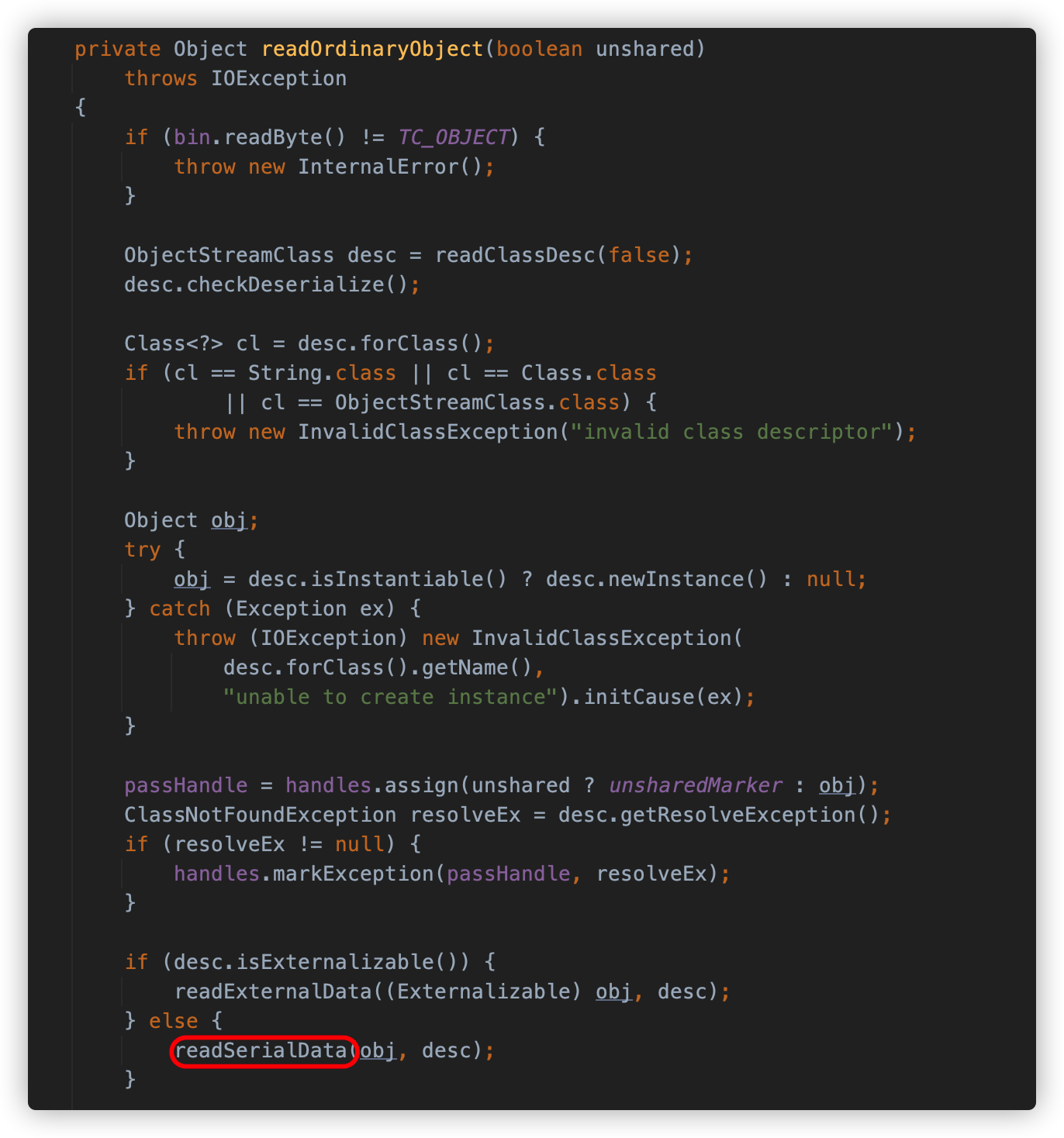
在 readSerialData 方法中,首先通过类描述符获得了序列化对象的数据布局。通过布局的 hasReadObjectMethod 方法判断对象是否有重写 readObject 方法,如果有,则使用 invokeReadObject 方法调用对象中的 readObject
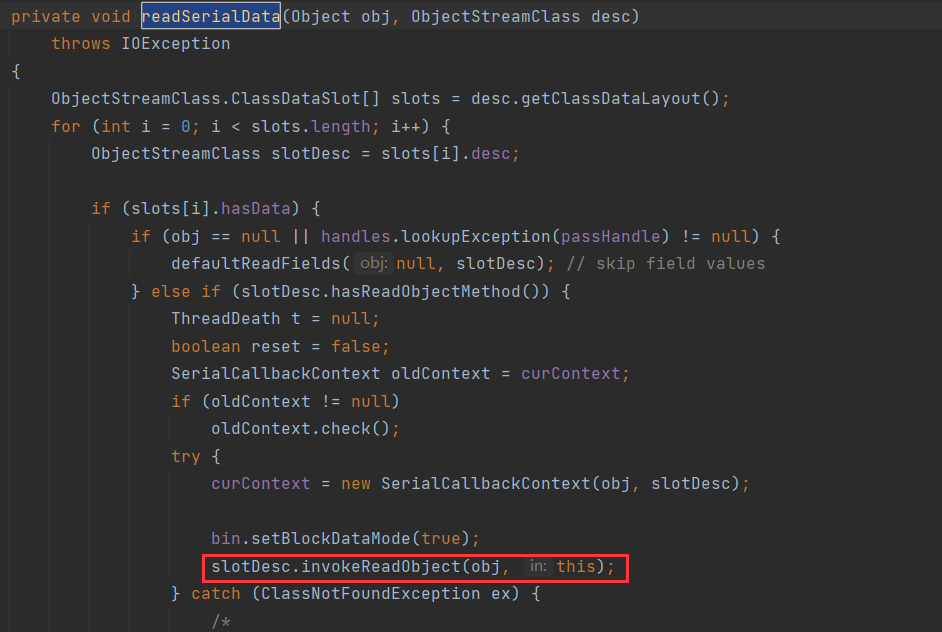
我们就了解了反序列化漏洞的触发原因。与反序列漏洞的触发方式相同,在序列化时,如果一个类重写了 writeObject 方法,并且其中产生恶意调用,则将会导致漏洞,当然在实际环境中,序列化的数据来自不可信源的情况比较少见。
那接下来该如何利用呢?我们需要找到那些类重写了 readObject 方法,并且找到相关的调用链,能够触发漏洞。
Java安全之反序列化(1)的更多相关文章
- Java序列化与反序列化
Java序列化与反序列化是什么?为什么需要序列化与反序列化?如何实现Java序列化与反序列化?本文围绕这些问题进行了探讨. 1.Java序列化与反序列化 Java序列化是指把Java对象转换为字节序列 ...
- [转] Java序列化与反序列化
原文地址:http://blog.csdn.net/wangloveall/article/details/7992448 Java序列化与反序列化是什么?为什么需要序列化与反序列化?如何实现Java ...
- Java序列化与反序列化(Serializable)
Java序列化与反序列化(Serializable) 特别注意: 1.要序列化的类必须实现Serializable借口 2.在反序列化(读取对象)的时候必须额外捕获EOFException 3.序列化 ...
- Java基础(五)-Java序列化与反序列化
.output_wrapper pre code { font-family: Consolas, Inconsolata, Courier, monospace; display: block !i ...
- JAVA序列化和反序列化XML
package com.lss.utils; import java.beans.XMLDecoder; import java.beans.XMLEncoder; import java.io.Bu ...
- Java序列化与反序列化(实践)
Java序列化与反序列化(实践) 基本概念:序列化是将对象状态转换为可保持或传输的格式的过程.与序列化相对的是反序列化,它将流转换为对象.这两个过程结合起来,可以轻松地存储和传输数据. 昨天在一本书上 ...
- java序列化与反序列化(转)
Java序列化与反序列化是什么?为什么需要序列化与反序列化?如何实现Java序列化与反序列化?本文围绕这些问题进行了探讨. 1.Java序列化与反序列化 Java序列化是指把Java对象转换为字节序列 ...
- ref:Java安全之反序列化漏洞分析(简单-朴实)
ref:https://mp.weixin.qq.com/s?__biz=MzIzMzgxOTQ5NA==&mid=2247484200&idx=1&sn=8f3201f44e ...
- Java序列化与反序列化是什么?为什么需要序列化与反序列化?如何实现Java序列化与反序列化?
Java序列化与反序列化是什么?为什么需要序列化与反序列化?如何实现Java序列化与反序列化?本文围绕这些问题进行了探讨. 1.Java序列化与反序列化 Java序列化是指把Java对象转换为字节 ...
- (记录)Jedis存放对象和读取对象--Java序列化与反序列化
一.理论分析 在学习Redis中的Jedis这一部分的时候,要使用到Protostuff(Protobuf的Java客户端)这一序列化工具.一开始看到序列化这些字眼的时候,感觉到一头雾水.于是,参考了 ...
随机推荐
- P5384[Cnoi2019]雪松果树 (长链剖分)
题面 一棵以 1 1 1 为根的 N N N 个节点的有根树, Q Q Q 次询问,每次问一个点 u u u 的 k k k 级兄弟有多少个(第 k k k 代祖先的第 k k k 代孩子),如果没有 ...
- shellcode 注入执行技术学习
shellcode 注入执行技术学习 注入执行方式 CreateThread CreateRemoteThread QueueUserAPC CreateThread是一种用于执行Shellcode的 ...
- C++ | unordered_map 自定义键类型
C++ unordered_map 使用自定义类作为键类型 C++ unordered_map using a custom class type as the key
- jenkins流水线部署springboot应用到k8s集群(k3s+jenkins+gitee+maven+docker)(2)
前言:上篇已介绍了jenkins在k3s环境部署,本篇继续上篇讲述流水线构建部署流程 1.从gitlab上拉取代码步骤 在jenkins中,新建一个凭证:Manage Jenkins -> Ma ...
- winfrom程序只启动一个exe进程
private static void KillProcess() { Process process1 = Process.GetCurrentProcess(); //获得当前计算机系统内某个进程 ...
- 网络基础七层模型与TCP/IP协议
1.网络基础 1.1 什么是网络 网络就是计算机网络是一组计算机或网络设备通过有形 的线缆或无形的媒介如无线,连接起来,按照一定的 规则,进行通信的集合. 网络通信就是指终端设备之间通过计算机网络进行 ...
- 使用 Elastic 技术栈构建 K8S 全栈监控 -2: 用 Metricbeat 对 Kubernetes 集群进行监控
文章转载自:https://www.qikqiak.com/post/k8s-monitor-use-elastic-stack-2/ 操作步骤 git clone https://github.co ...
- Elasticsearch:Index生命周期管理入门
如果您要处理时间序列数据,则不想将所有内容连续转储到单个索引中. 取而代之的是,您可以定期将数据滚动到新索引,以防止数据过大而又缓慢又昂贵. 随着索引的老化和查询频率的降低,您可能会将其转移到价格较低 ...
- kibana知识点
1.Kibana 有 Linux.Darwin 和 Windows 版本的安装包.由于 Kibana 基于 Node.js 运行,我们在这些平台上包含了一些必要的 Node.js 二进制文件.Kiba ...
- 使用logstash同步Mysql数据表到ES的一点感悟
针对单独一个数据表而言,大致可以分如下两种情况: 1.该数据表中有一个根据当前时间戳更新的字段,此时监控的是这个时间戳字段 具体可以看这个文章:https://www.cnblogs.com/sand ...