大数据教程-01HDFS的基本组成和原理
一 Hadoop历史背景
起源于2003年谷歌的Google File System相关论文,随后Doug Cutting(我们下面就叫他切哥吧)基于GFS的论文实现了分布式文件系统,并把它命名为NDFS(Nutch Distributied File System)。
2004年谷歌又发表了一篇学术论文,介绍了自己的MapReduce编程模型,这个编程模型适用于大规模数据集(大于1TB)的并行分析运算。随后,切哥又基于MapReduce在Nutch搜索引擎实现了该功能,这回切哥没改名,估计是想不出比这更好的名字了吧。
2006年谷歌又发了论文,介绍了自己BigTable(一种非关系型数据库),后面的结果你们能猜到了哈,我们机智的切哥就把BigTable的思想引入到了Hadoop系统里面,并命名为HBase(学习借鉴,切哥在起名这块从来不手软)。
切哥这么牛逼,后来就加入了雅虎,然后又升级改造,一阵duangduangduang,然后就有了现在Hadoop的雏形。
按照国际惯例,你们猜猜看切哥有没有头发?

二 Hadoop简介
切哥果然没有头发,这下心里平衡了吧
Hadoop是Apache的一个开源的分布式计算平台,核心是以HDFS分布式文件系统和MapReduce分布式计算框架构成的,为用户提供了一套底层透明的分布式基础设施。
Hadoop的核心思想就是分布式计算和分布式存储,HDFS负责分布式存储,MapReduce负责分布式计算。
HDFS是Hadoop分布式文件系统,具有高容错性和高伸缩性,允许用户基于廉价硬件部署,构建分布式存储系统,为分布式计算存储提供了底层技术支持。
MapReduce其实就是一套封装好的API,用户可以在不了解底层细节的情况下,开发分布式并行程序,利用大规模集成资源,解决传统单机无法解决的大数据处理问题。
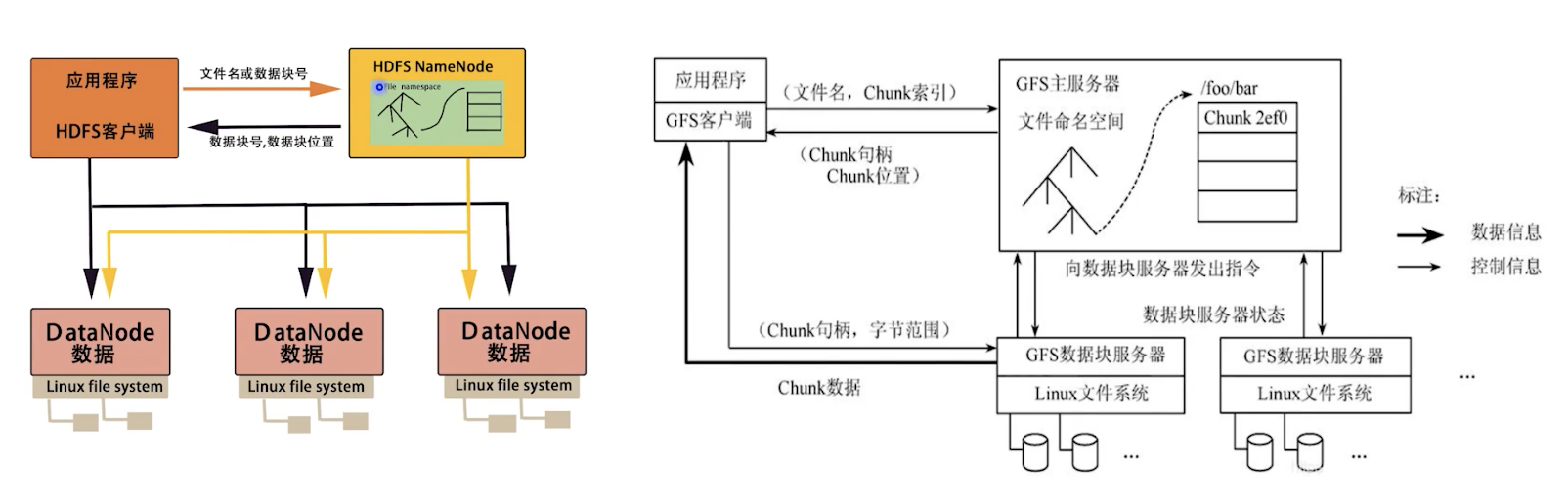
三 Hadoop1.0架构
我先来讲解Hadoop1.0的架构,因为当时的架构比较简单,理解起来比较容易。
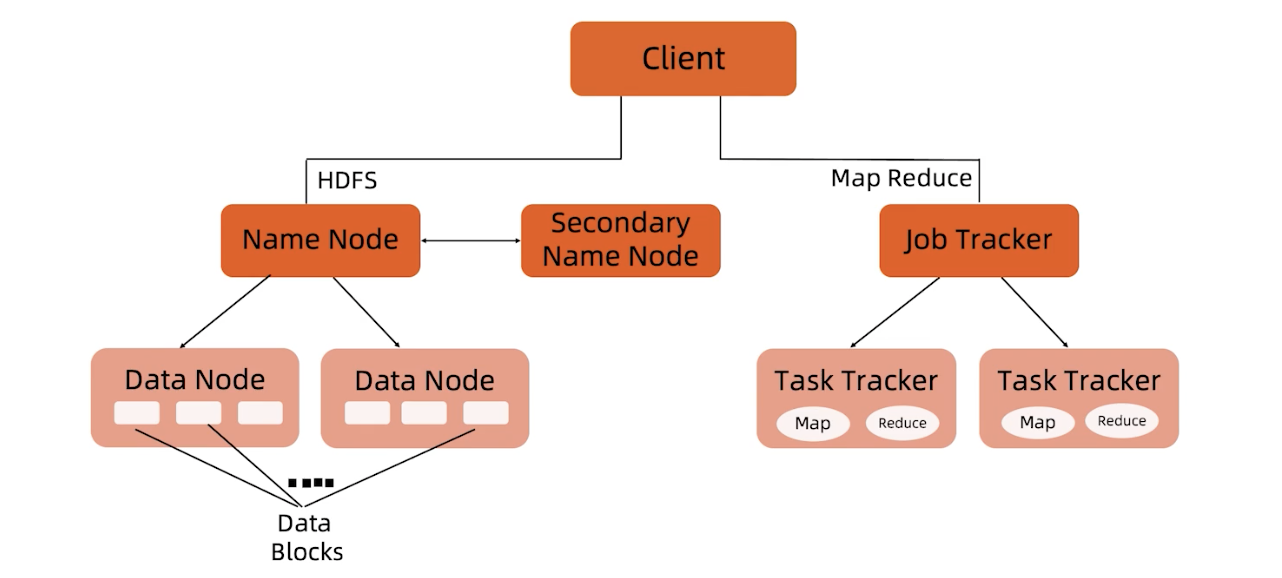
NameNode
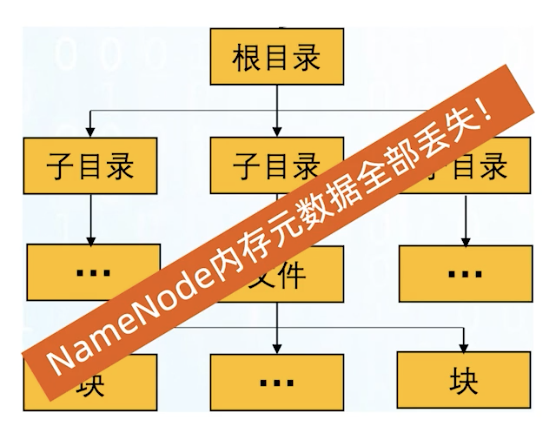
负责维护整个文件系统的文件目录树,包括文件目录的元信息和文件数据块索引(元信息是指文件路径,数据块索引是指某个大文件被分割成的文件块所处的位置),由于NameNode是一个JVM进程,一旦重启就丢失掉了,所以要永久保存,这些元信息是以FsImage和EditLog形式存储在本地。
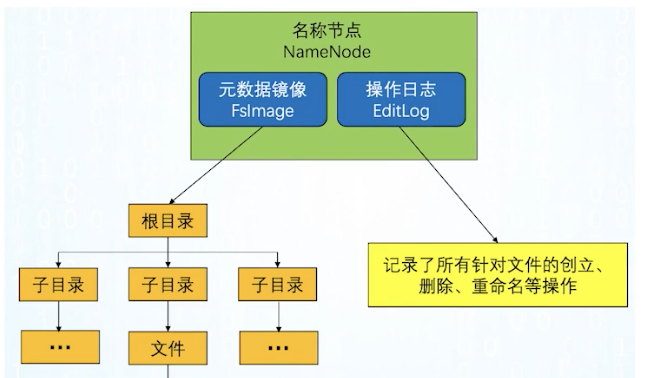
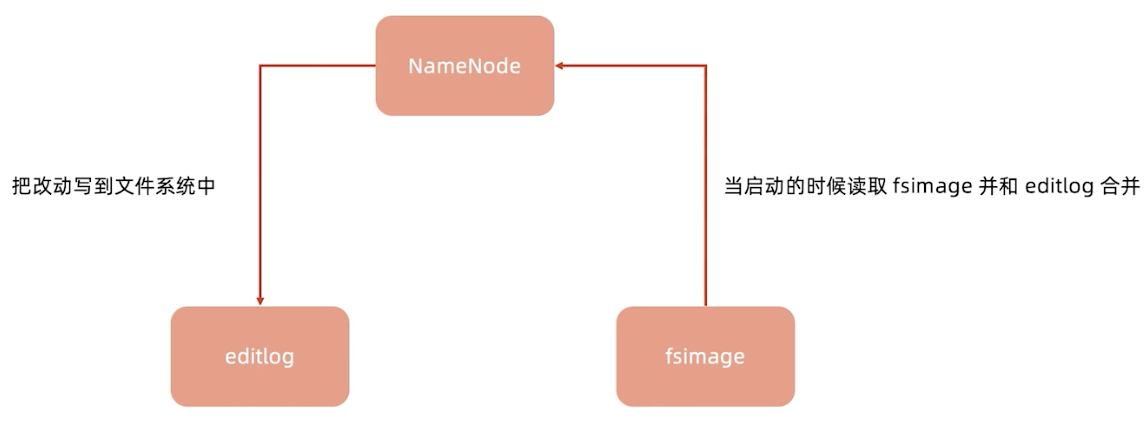
FsImage相当于是一个元信息的镜像,当我们对目录树修改后,会把修改信息记录在EditLog中,然后定期做合并,生成一个新的FsImage。这个NameNode出现故障时,是不能对外提供服务的,因为它只有一个节点。
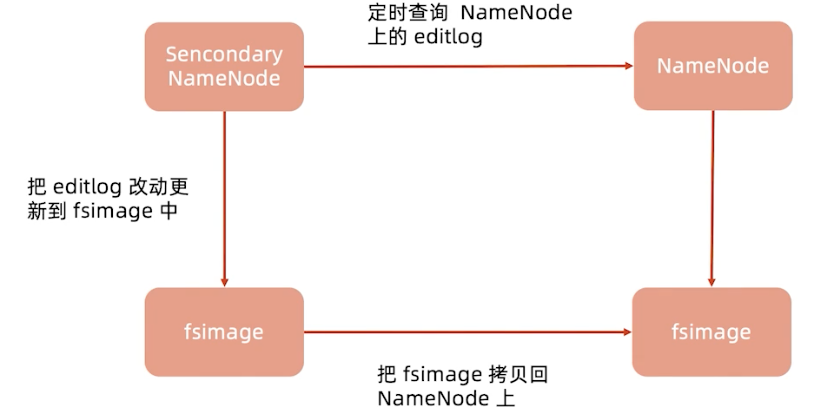
Secondary Name Node
这个并不是备份的,准确来说应该叫他CheckPoint Node,是负责做FsImage和EditLog定期合并。不接受客户端请求,作为NameNode的冷备份。当我们文件很多很大时,合并很消耗内存,NameNode要服务于线上的客户端读写,所以把它们拆开成了两个节点。
DataNode
实际存储数据的单元,数据以Block为单位,一个大文件在Hadoop存储时会切分成很多个Block,在Hadoop层面来讲存的是Block,不是文件,但是站在Linux层面来看,数据还是以文件形式保存在本地文件系统。
Client
通过一个API与HDFS交互,可以进行读写,创建目录,创建文件,复制,删除等等。HDFS提供了多种客户端:Shell命令行,Java API,Thrift接口,C library,WebHDFS等。
Data Block
文件是由Block组成的,假设每一块大小为64MB,实际上使用会设置相对大一点,这样切分时个数就会变少。Block越多,存储数据的元信息就会越多,使用时消耗的内存就会越大。所以,适当增大Block Size可以减少元信息数量,使用时更节省内存。
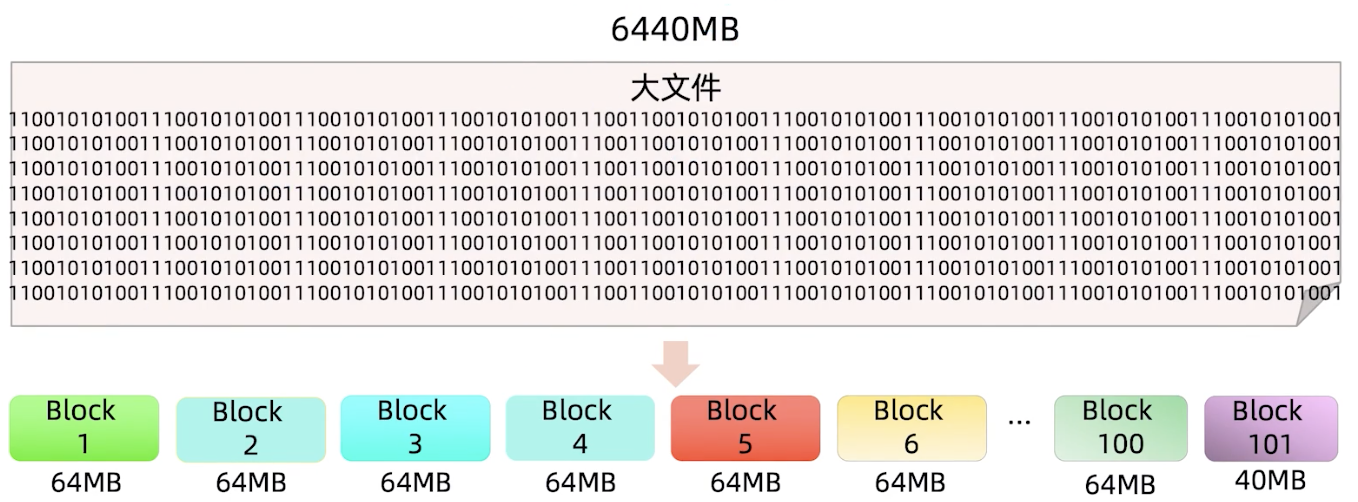
多出来40MB也是一个Block,即使是多出来1MB,也会是一个Block。
四 数据块分布
为了保持系统的高可用性,每一个Block会存3个副本(可以调,一般是3个),也就是说一个100G的文件需要用300G的空间来存储。
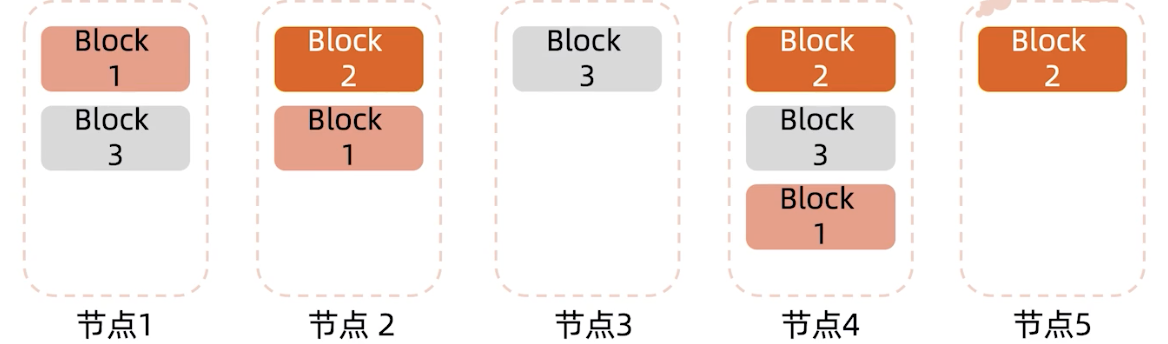
默认存放规则(驾驶复制因子是3):
- 第一份拷贝写入创建文件的节点,目的是能够快速写入
- 第二份拷贝写入位于不用rack的节点,是为了应对交换机故障(假设节点2和节点1不再同一机柜)
- 第三份拷贝写入和第二份副本同一个rack内的节点,为了减少跨rack的网络流量(交换机故障率极低,跨顶层交换机流量消耗大)
什么是rack?不同的机柜怎么定义?

如你所见,上方有三个机柜,每个机柜ip地址是不同的,通过ip地址找到不同的rack。
五 HDFS各角色交互
定时心跳
DataNode会定时给NameNode发送心跳,告诉NameNode我还活着,NameNode收到之后也会回复一些指令,比如请你下线。
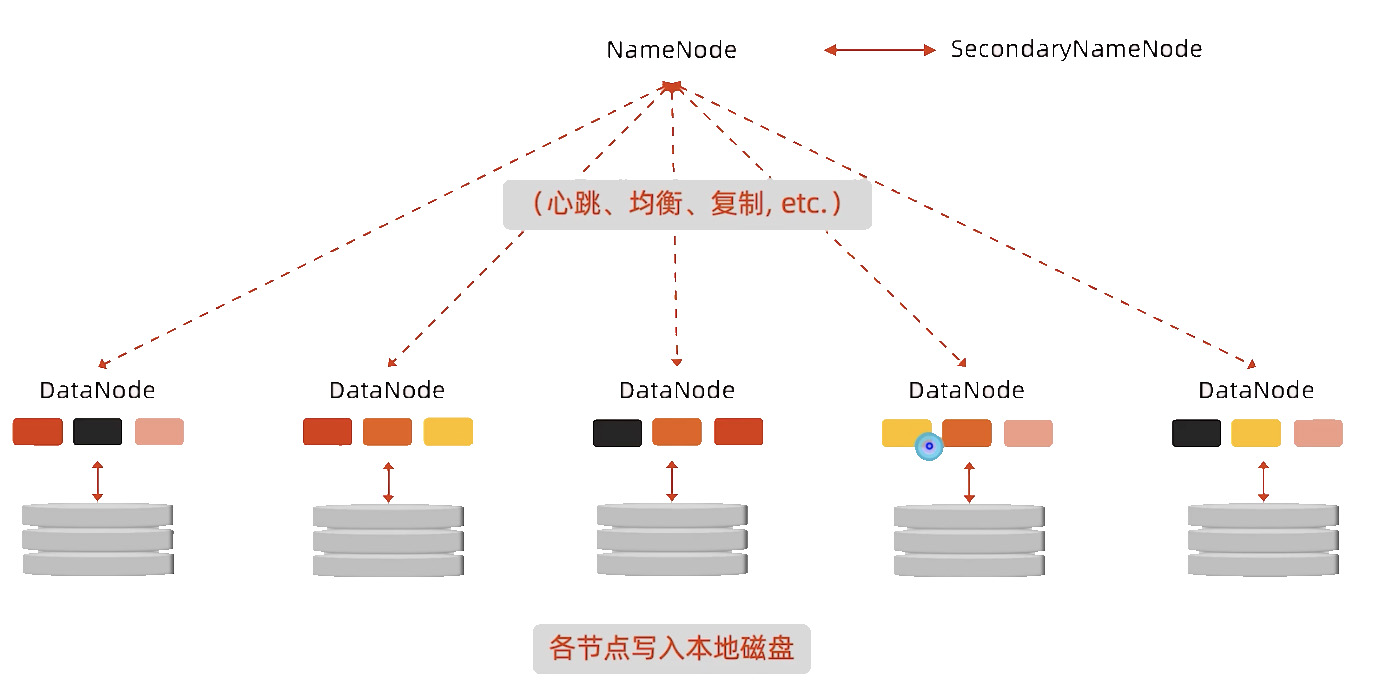
HDFS读流程
客户端发送指令给NameNode,NameNode返回Block列表,然后客户端连接对应的Block,最后读出大文件,整个过程是流式的。
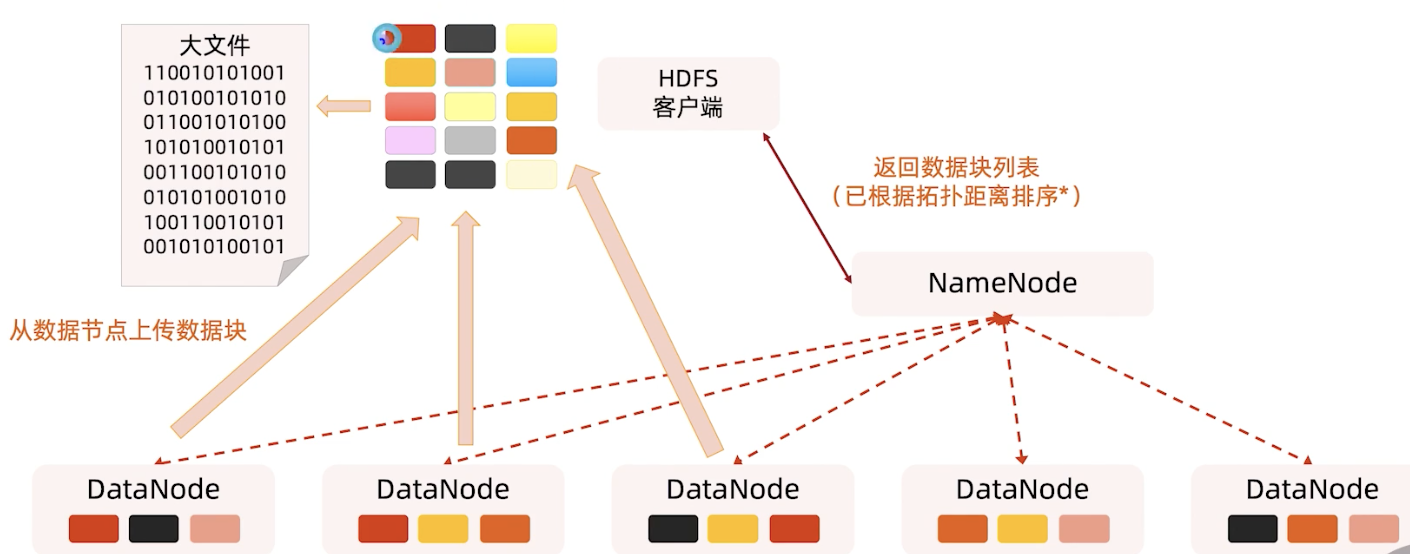
机架感知:拓扑距离
上面图中提到的拓扑距离排序,拓扑距离是怎么计算的?
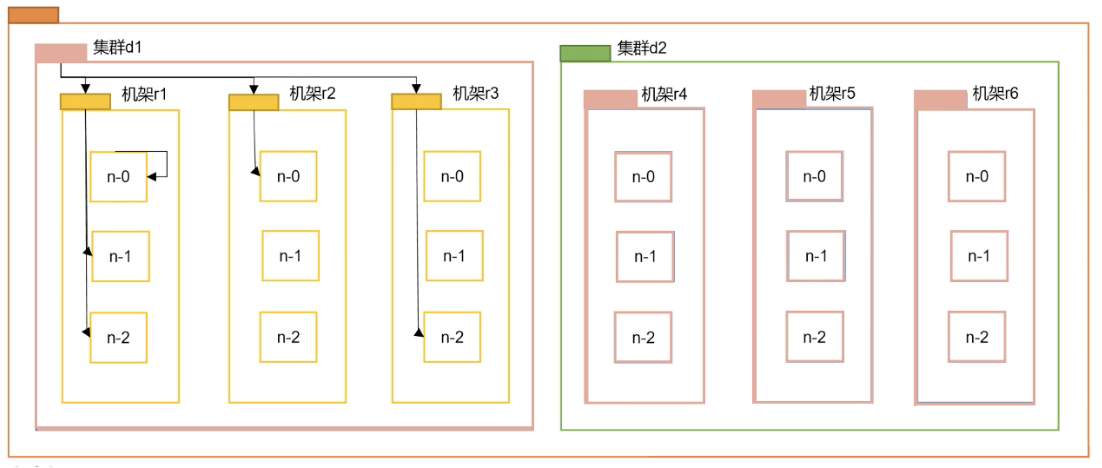
计算方式是两个节点到达最近的共同祖先的距离总和。
- Distance(d1/r1/n0,d1/r1/n0)=0 同一节点上的进程
- Distance(d1/r1/n1,d1/r1/n2)=2 同一机架上的不同节点,两个节点各上1步到同一位置
- Distance(d1/r2/n0,d1/r3/n2)=4 同一数据中心不同机架上的节点,两个节点各上2步到同一位置
- Distance(d1/r2/n1,d2/r1/n1)=6 不同数据中心的节点
机架感知-再看副本放置策略
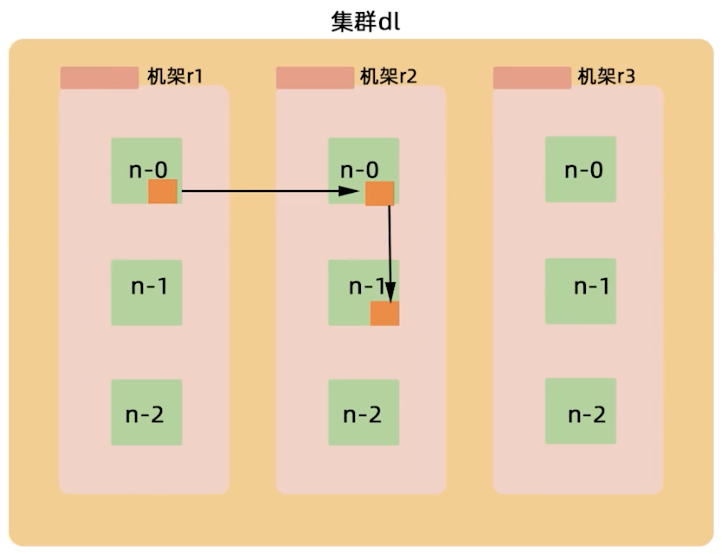
- 第一个副本在Client所处的节点上,如果客户端在集群外,随机选一个
- 第二个副本在另一个机架的随机一个节点
- 第三个副本在第二个副本所在的机架
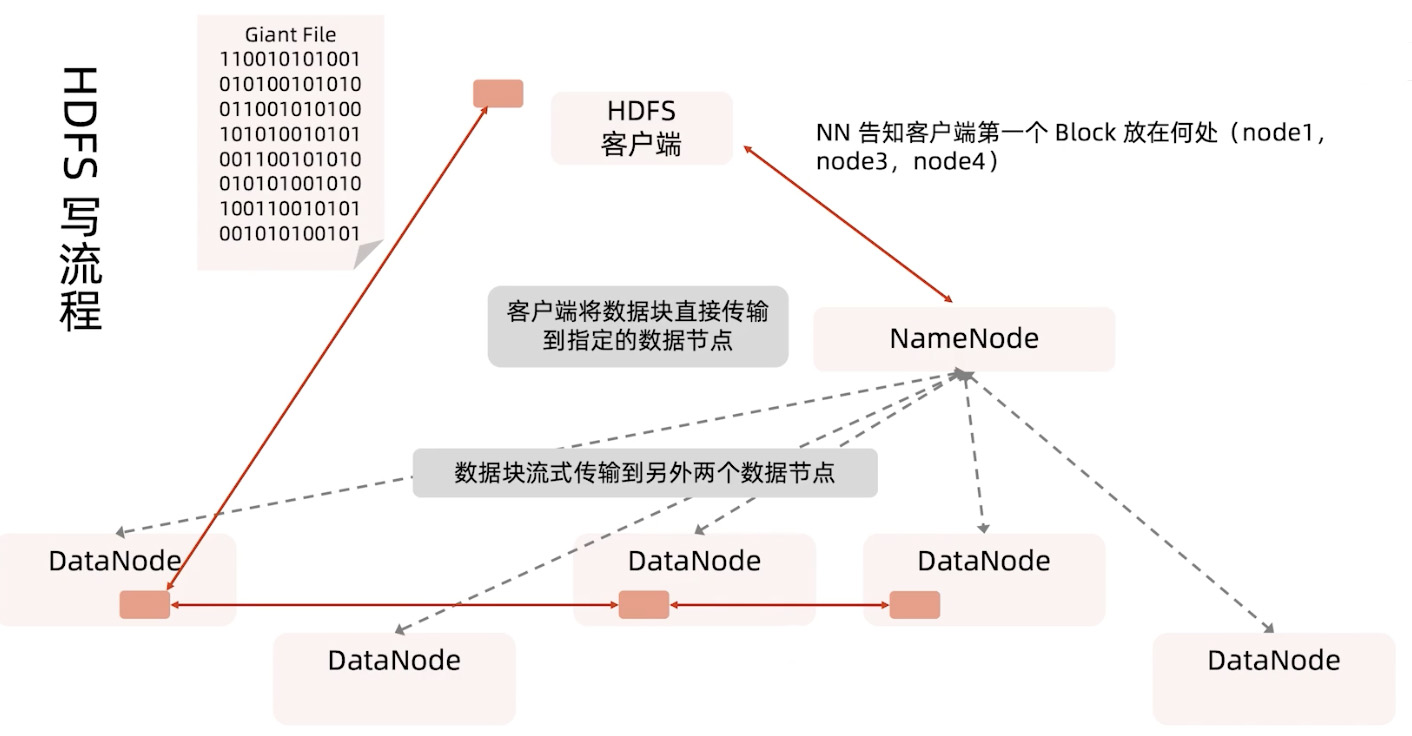
HDFS写流程
首先是客户端发送写的指令给NameNode,然后NameNode告知客户端第一个Block的放置位置,接着客户端连接对应的DataNode每次小批量循环写入,比如Block为64MB,每次每个DataNode先写入64KB,写完了就换下一个DataNode,直到第一个Block写入完成换下一个Blcok,如此循环往复。
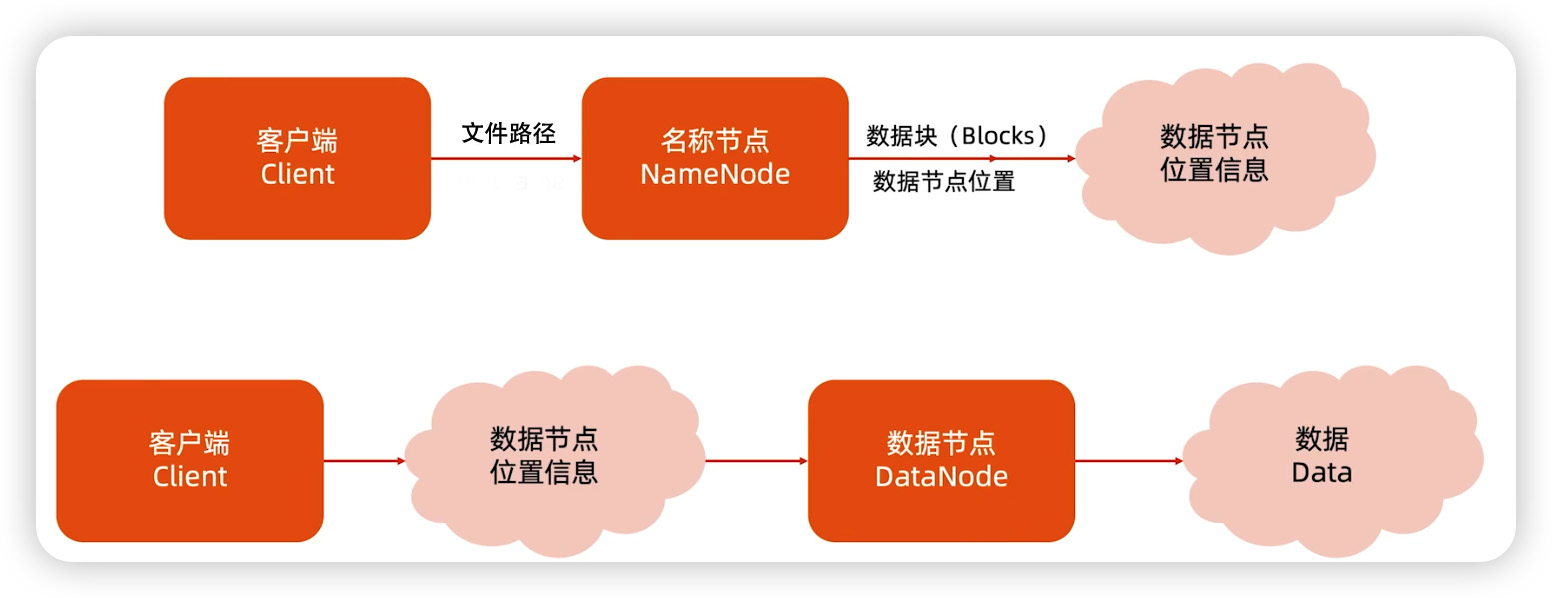
读写流程总结
读写的流程基本是类似的,都是流式进行的。
六 HDFS故障恢复流程
要保证系统的高可用性,容灾是必不可少的,主要的故障有以下几种。

DataNode容灾
如果DataNode坏掉,那么它对应的心跳就没有了,虽然还有其他的副本提供服务,但我们系统也要做一些恢复的操作。
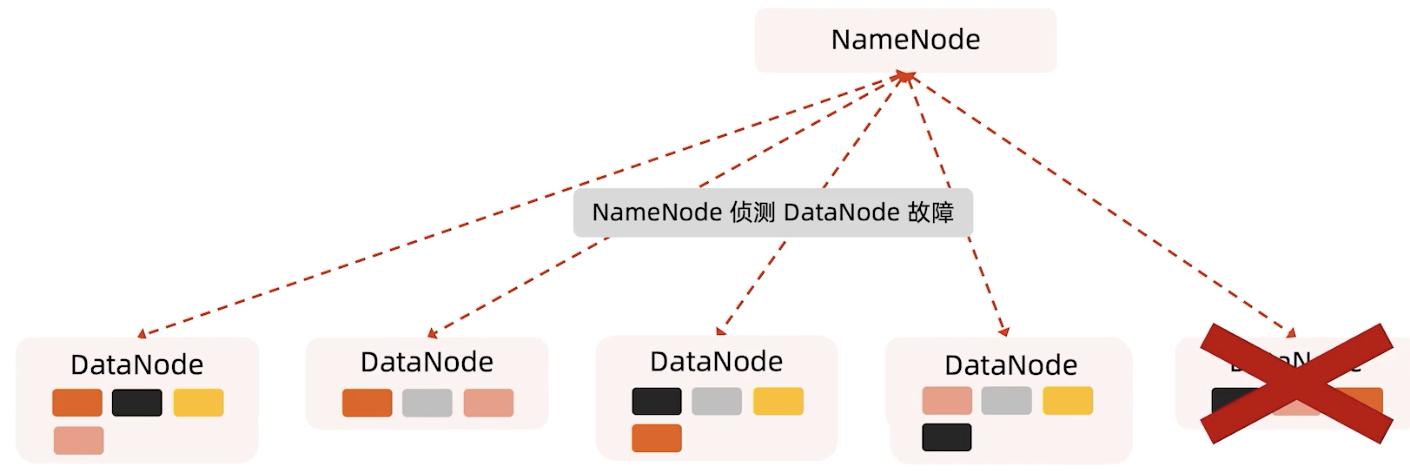
因为复制因子是3,但在集群里面只有两个副本,系统会把下图DataNode1黑色的Block复制一份,其他的也是类似的,这样就能保证系统的高可用性。
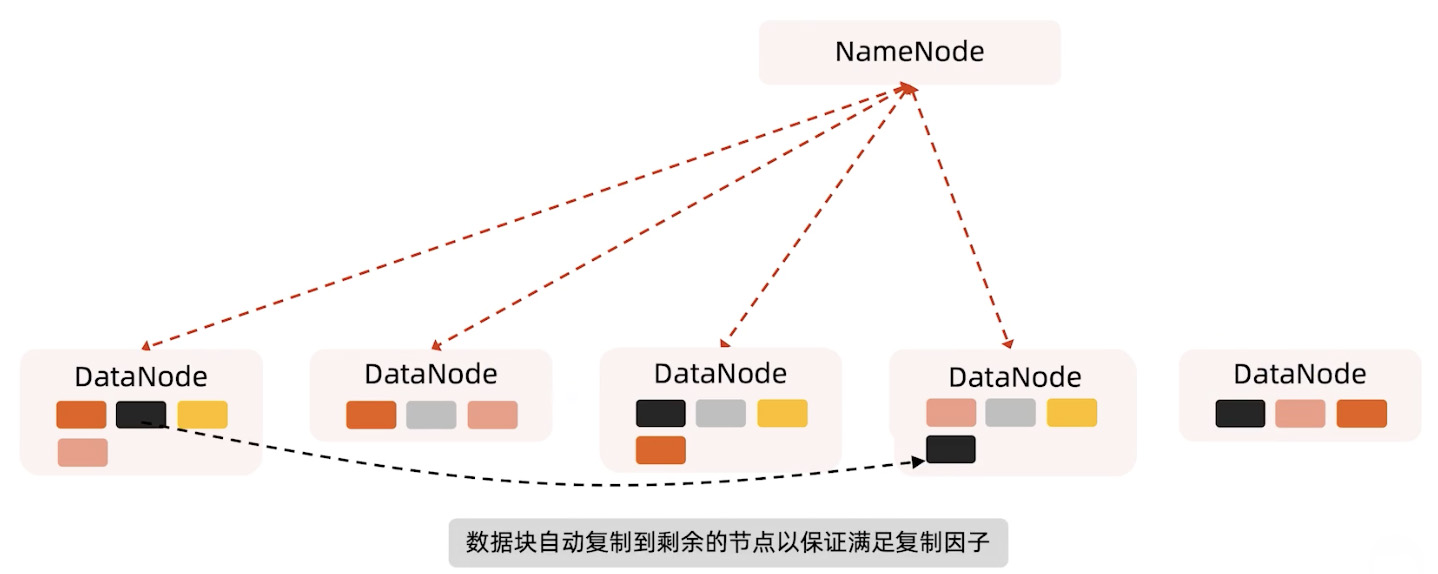
也还有一种可能,刚才系统以为坏掉的DataNode只是网络断了,后面又恢复了,这样就会有的Block多出一个副本,这时系统会根据它的负载均衡删除一个多的就可以了。
机柜/交换机故障
其实机柜或者交换机故障与DataNode和磁盘故障是类似的,因为我们Block副本是在不同机柜的。
NameNode 容灾(Hadoop V2)
其实Hadoop1.0时候NameNode是一个单点,挂掉了必须重新启动起来,在Hadoop2.0时候有了一个备用的NameNode,注意这不是Secondary NameNode,这时候就有了主从模式,一个是active,另一个是standby
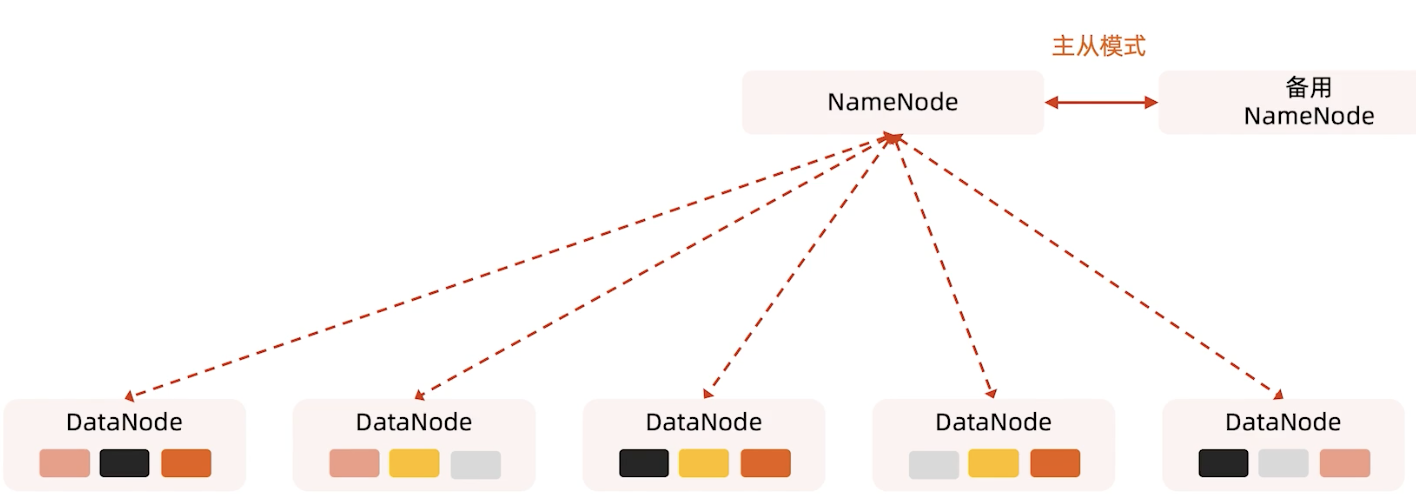
备用的NameNode也是可以接收心跳的,当主NameNode挂掉后,备用的NameNode可以立即接管。
FsImage和EditLog的作用
我们知道NameNode是没有HA结构的(High a Availability),所以是一个单点故障,NameNode在内存中的元数据全部丢失,FsImage和EditLog的存在可以保证让重启的NameNode获得最新的宕机前的元数据。
FsImage是整个NameNode内存中元数据在某一时候的Snapshot(快照)。
- FsImage不能频繁地构建,生成FsImage要消耗大量的内存
- 目前FsImage只在NameNode重启时才重新构建
EditLog记录的是从这个快照开始到当前所有元数据的改动
- 如果EditLog太多,EditLog加载会消耗大量的时间
- 这会导致NameNode重启消耗数小时之久
Secondary NameNode
Secondary NameNode就是来帮助减小EditLog文件的大小和更新FsIamge,以此来减小NameNode的压力。
NameNode Failure
来看4个小问题:
- NameNode进程挂了怎么办?
- NameNode进程挂了,启动不起来怎么办?
- NameNode所在机器操作系统进不去怎么办?
- NameNode机器无法开机怎么办?
进程挂了就重启,重启起不来就把机器上对应的FsImage和EditLog文件迁移到一台新的机器上,如果操作系统进不去,或许可以通过BIOS方式把文件取出来,但是如果开机都开不了,那就只能把Secondary NameNode勉强可以作为NameNode使用,就是把他的IP改成NameNode的IP,从Secondary NameNode机器上来重启。再如果Secondary NameNode也开不了机,你就跟老板说,你买的什么破机器,要坏都一块坏,u can u up,ur father is down.
大数据教程-01HDFS的基本组成和原理的更多相关文章
- Atitit. BigConfirmTips 控件 大数据量提示确认控件的原理and总结O9
Atitit. BigConfirmTips 控件 大数据量提示确认控件的原理and总结O9 1. 主要的涉及的技术 1 2. 主要的流程 1 3. 调用法new confirmO9t(); 1 4. ...
- 大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark.Spark核心原理.架构原理.Spark特点 大数据体系概览(Spark的地位) 什么是Spark? Spark整体架构 Spark的特点 Spark核心原理 Spark架构 ...
- 【大数据技术】Hadoop三大组件架构原理(HDFS-YARN-MapReduce)
目前,Hadoop还只是数据仓库产品的一个补充,和数据仓库一起构建混搭架构为上层应用联合提供服务. Hadoop集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起. ...
- 大数据基础总结---MapReduce和YARN技术原理
Map Reduce和YARN技术原理 学习目标 熟悉MapReduce和YARN是什么 掌握MapReduce使用的场景及其原理 掌握MapReduce和YARN功能与架构 熟悉YARN的新特性 M ...
- 大数据数据库HBase(一)——架构原理
一.HBase简介 1.1.Hadoop生态系统 1.2.非关系型数据库知识面扩展 Cassandra hbase mongodb Couchdb,文件存储数据库 Neo4j非关系型图数据库 1.3 ...
- 大数据之Kafka史上最详细原理总结
Kafka Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实 ...
- 弄清Spark、Storm、MapReduce的这几点区别才能学好大数据
很多初学者在刚刚接触大数据的时候会有很多疑惑,比如对MapReduce.Storm.Spark三个计算框架的理解经常会产生混乱. 哪一个适合对大量数据进行处理?哪一个又适合对实时的流数据进行处理?又该 ...
- 大数据学习之路又之从小白到用sqoop导出数据
写这篇文章的目的是总结自己学习大数据的经验,以为自己走了很多弯路,从迷茫到清晰,真的花费了很多时间,希望这篇文章能帮助到后面学习的人. 一.配置思路 安装linux虚拟机--->创建三台虚拟机- ...
- CRL快速开发框架系列教程十一(大数据分库分表解决方案)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
随机推荐
- activiti5.13 框架 数据库表结构说明
1.结构设计 1.1. 逻辑结构设计 Activiti使用到的表都是ACT_开头的. ACT_RE_*: 'RE'表示repository(存储),RepositoryService接口所操作的 ...
- 2.k8s的架构
之前了解了k8s到底是什么,接下来看看k8s的组成. 一.Kubernetes架构 学习k8s,最终目的是为了部署应用,部署一个完整的k8s, 就要知道k8s的组成.k8s主要包含两大部分: 中间包含 ...
- Oracle 11G 安装详解
oracle官网下载地址:http://www.oracle.com/technetwork/database/enterprise-edition/downloads/index.html 官网下载 ...
- 关于sys.path.append()
当我们导入一个模块时:import xxx,默认情况下python解析器会搜索当前目录.已安装的内置模块和第三方模块,搜索路径存放在sys模块的path中: >>> import ...
- Solution -「CF 1361E」James and the Chase
\(\mathcal{Description}\) Link. 给定 \(n\) 个点 \(m\) 条边的有向弱连通图.称一个点是"好点"当且仅当从该点出发,不存在到同一点 ...
- JAVA 1.对象和封装
1. 2. 3.Java类里面属性可以付初使值 4.属性的名字一小写开头 5 6.构造方法 1.语法: 7.staitc的应用 1.statia可以用来修饰:方法,属性,代码块 , st ...
- 《从零开始, 开发一个 Web Office 套件》系列博客目录
这是一个系列博客, 最终目的是要做一个基于HTML Canvas 的, 类似于微软 Office 的 Web Office 套件, 包括: 文档, 表格, 幻灯片... 等等. 对应的Github r ...
- JUC之认识ConcurrentHashMap
ConcurrentHashMap为什么广泛使用?回答这个问题之前先要回忆下几个基本的概念涉及hash的几个数据结构及锁优化(关于锁优化参考JMM之Java中锁概念的分类总结 - 池塘里洗澡的鸭子 - ...
- Spring Boot自动配置SpringMVC(二)
Spring Boot自动配置SpringMVC(一) - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com)讲述了关于DispatcherServlet注册到诸如tomcat容器中的自动配置过 ...
- SpringBoot2.6.x默认禁用循环依赖后的应对策略
一.序言 SpringBoot 2.6.x不推荐使用循环依赖,这是一个好消息,SpringBoot从底层逐渐引导开发者书写规范的代码,同时也是个忧伤的消息,循环依赖的应用场景实在是太广泛了. 如果从低 ...