大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
小提示:这里,使用axure(原型制作工具),来画图十分方便,个人认为比viso或者是processon等流程图制作工具简单多了。
点击链接,看取axure画完以后生成的html网页。
spark的axure原型
效果图:
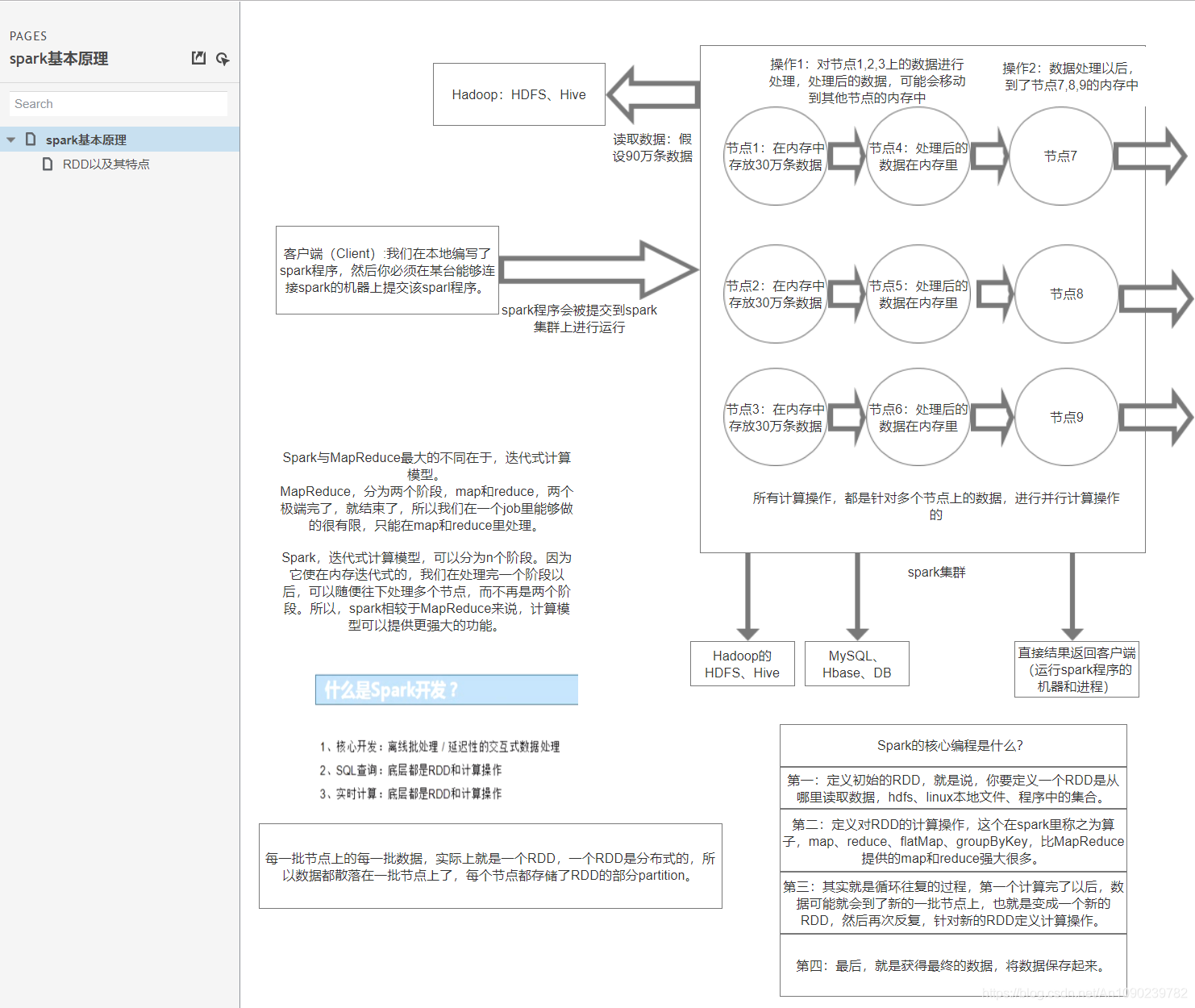
大数据体系概览(Spark的地位)
Hadoop生态圈重点组件:
HDFS:Hadoop的分布式文件存储系统。
MapReduce:Hadoop的分布式程序运算框架,也可以叫做一种编程模型。
Hive:基于Hadoop的类SQL数据仓库工具
Hbase:基于Hadoop的列式分布式NoSQL数据库
ZooKeeper:分布式协调服务组件
Mahout:基于MapReduce/Flink/Spark等分布式运算框架的机器学习算法库
Oozie/Azkaban:工作流调度引擎
Sqoop:数据迁入迁出工具
Flume:日志采集工具
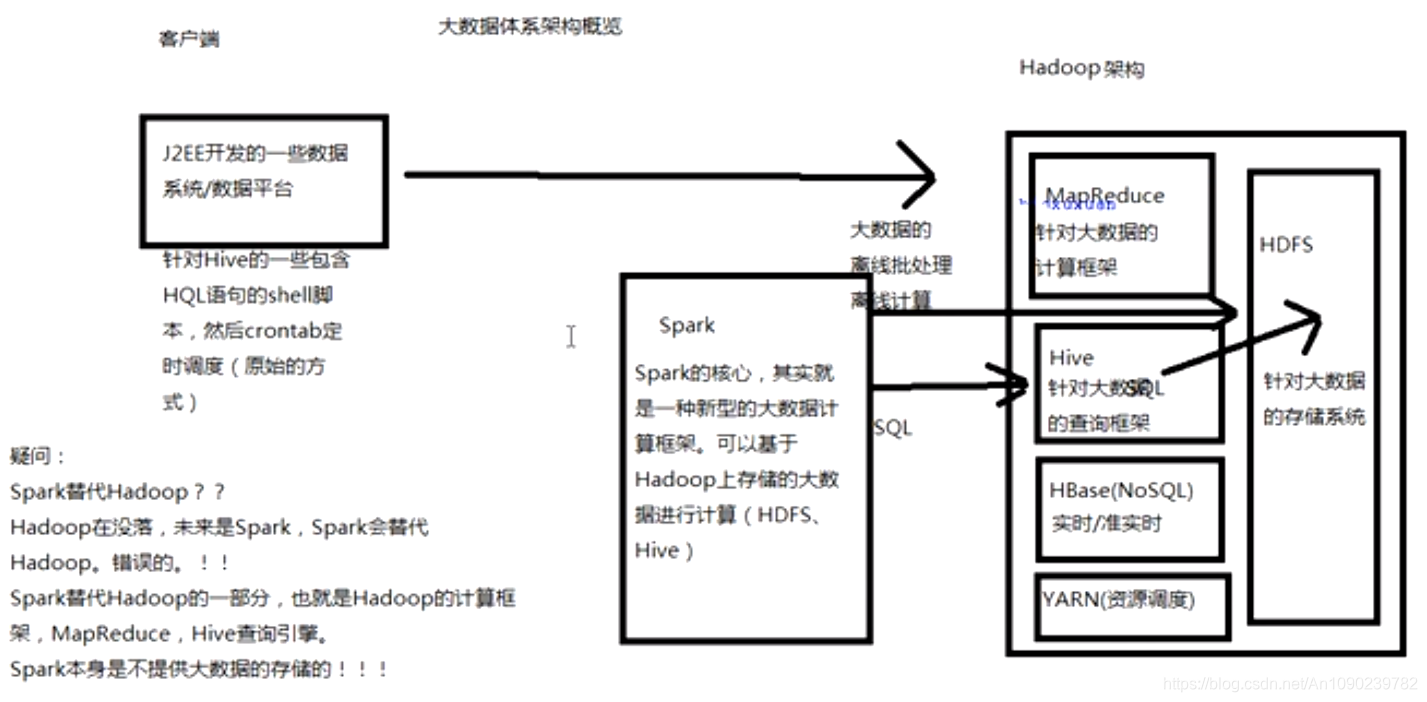
什么是Spark?
Spark,是一种通用的大数据计算框架,如Hadoop的MapReduce、Hive引擎,以及Storm流式实时计算引擎等。
Spark包含了大数据领域常见的各种计算框架:比如Spark Core用于离线计算,Spark SQL用于交互式查询,Spark Streaming用于实时流式计算,Spark MLlib用于机器学习,Spark Graphx用于图计算。
Spark主要用于大数据的计算,而Hadoop主要用于大数据的存储(比如HDFS、Hive、HBase),以及资源调度(Yarn)。
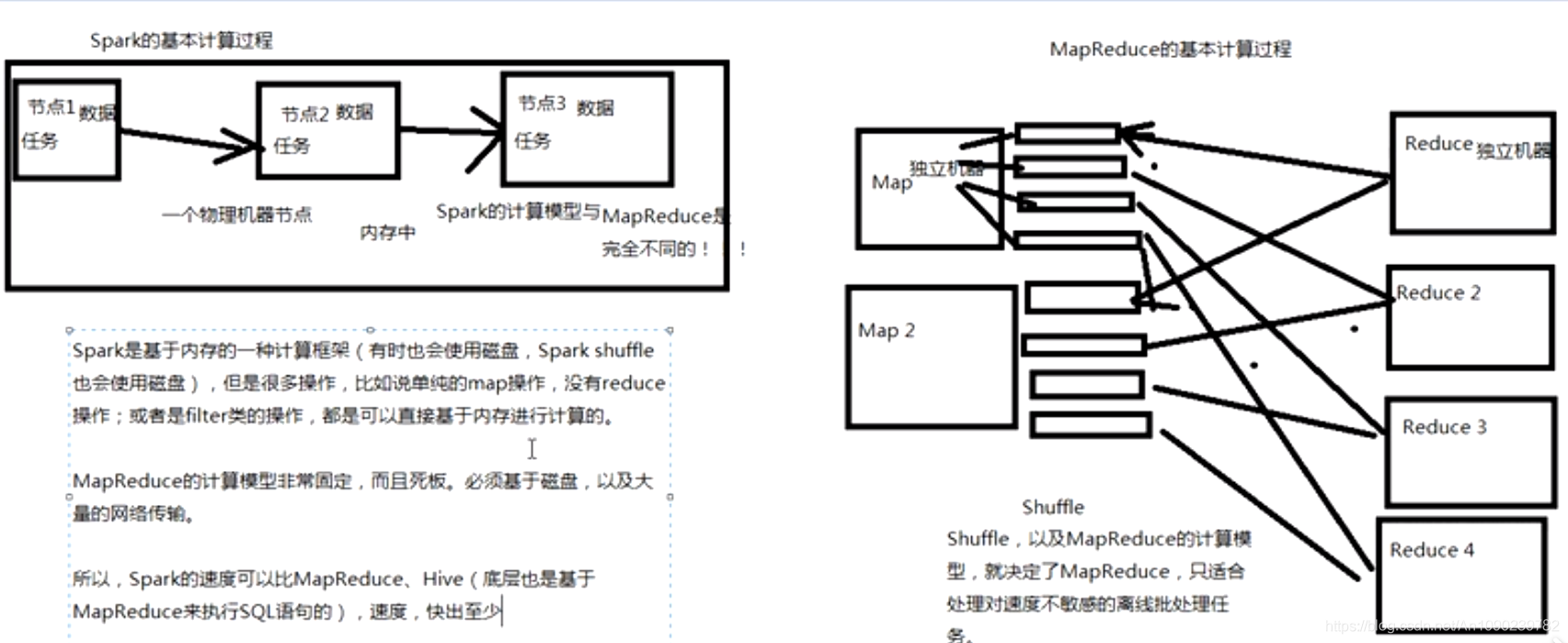
Spark除了一站式的特点之外,就是基于内存进行计算,从而让它的速度可以达到MapReduce、Hive的数倍甚至十倍!
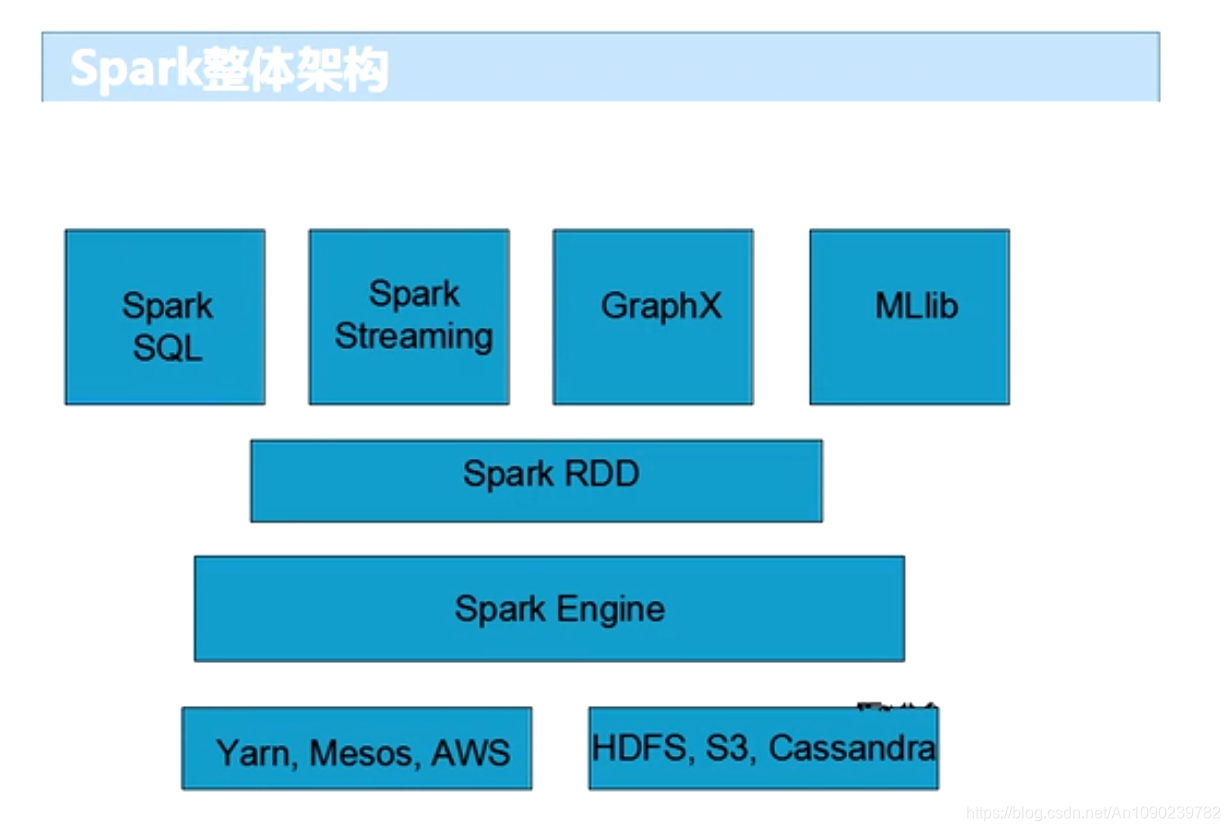
Spark整体架构
Spark的特点
- 速度快:Spark基于内存计算(部分基于磁盘,如shuffle)
- 超强的通用性:Spark提供了Spark RDD、Spark SQL、Spark Streaming、Spark MLlib、Spark Graphx等组件,可以一站式完成大数据领域的离线批处理、交互式查询、流式计算、机器学习、图形计算等常见的任务。
- 集成Hadoop:与Hadoop进行了高度的集成,Hadoop的HDFS、Hive、HBase负责存储,Yarn负责资源调度,Spark负责大数据计算。
Spark核心原理
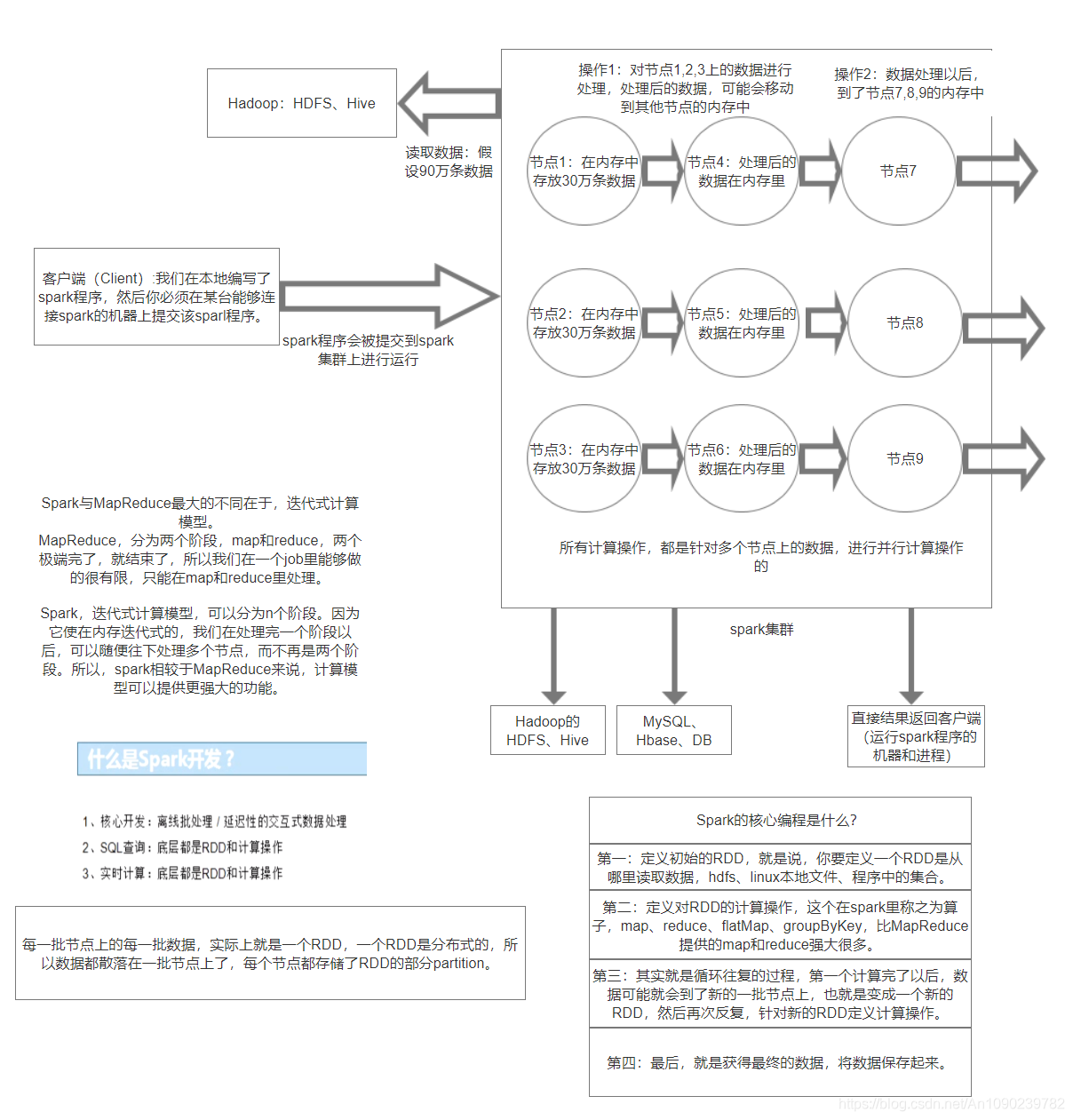
Spark架构原理
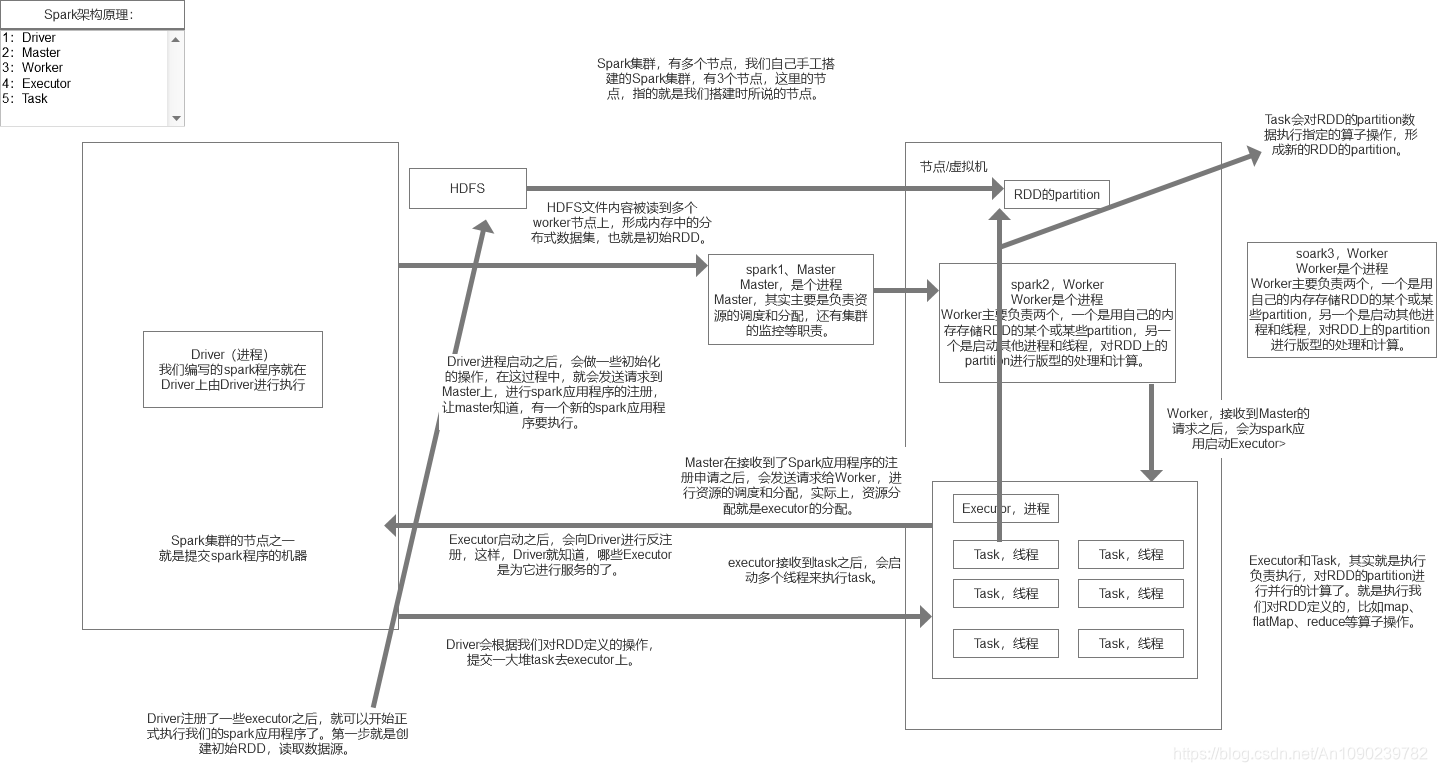
spark内核架构
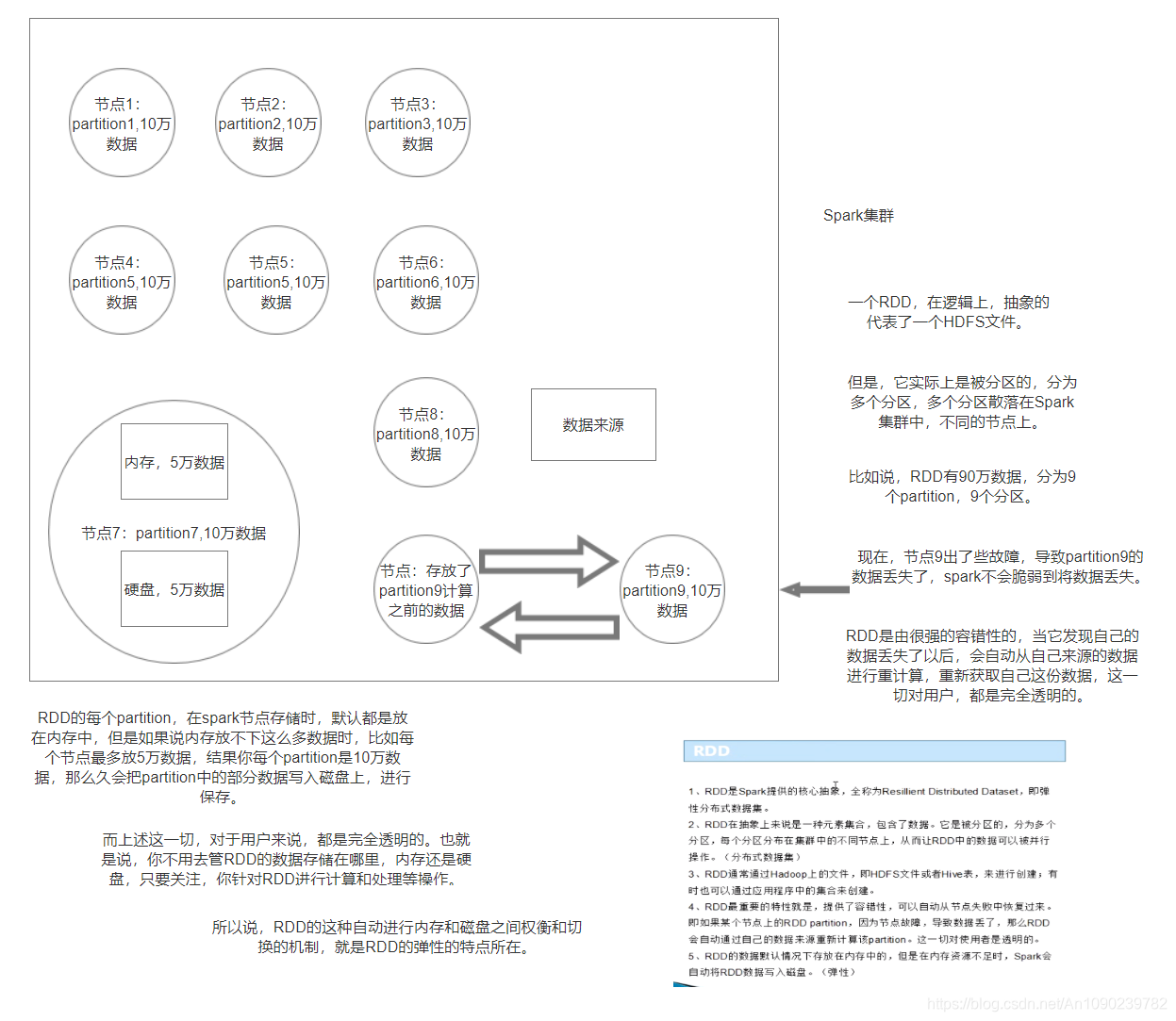
RDD及其特点
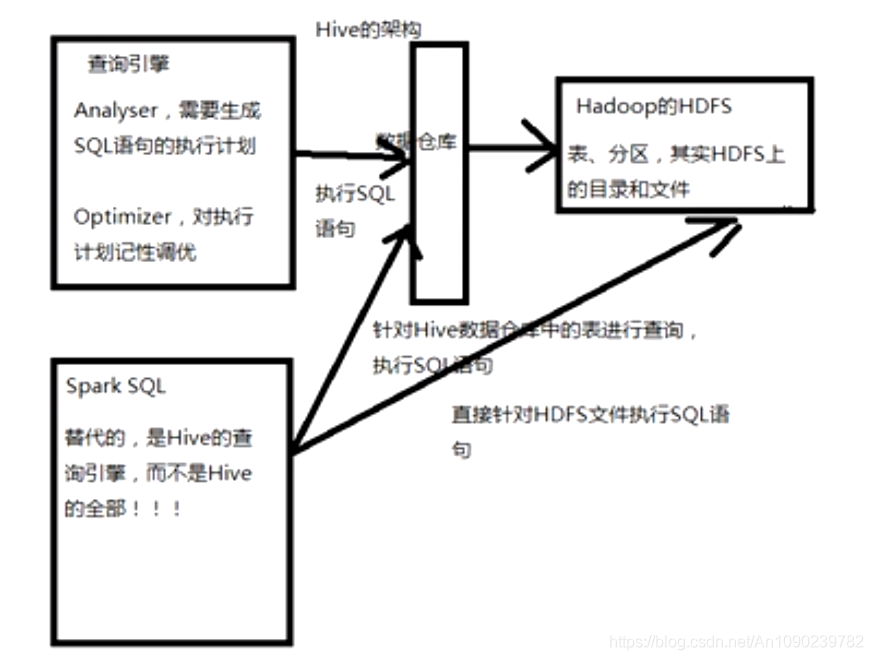
Spark SQL VS Hive
Hive基于HDFS的数据仓库,并提供了SQL模型的,针对存储了大数据的数据仓库,进行分布式交互查询的查询引擎。
Spark SQL是针对Hive数据仓库中的数据进行查询,Spark本身自己不提供存储。
Spark SQL支持大量不同的数据源,包括hive、json、parquet、jdbc等。
Spark Streaming VS Storm
Spark Streaming与Storm都可以进行实时流计算,但是二者区别很大。
Spark Streaming和Storm计算模型完全不一样,Spark Streaming是基于RDD的,因此需要将一小段时间内的,比如1s的数据,收集起来,作为一个RDD,然后再针对这个batch得数据进行处理。
而Storm却可以做到每来一条数据,都可以立即进行处理和计算。
Storm支持在分布式流式计算程序运行过程中,可以动态地调整并行度,从而动态提供并发处理能力,而Spark Streaming是无法动态调整并行度的。
Spark Streaming由于是基于batch进行处理的,因此相较于Storm基于单条数据进行处理,具有数倍甚至数十倍的吞吐量。

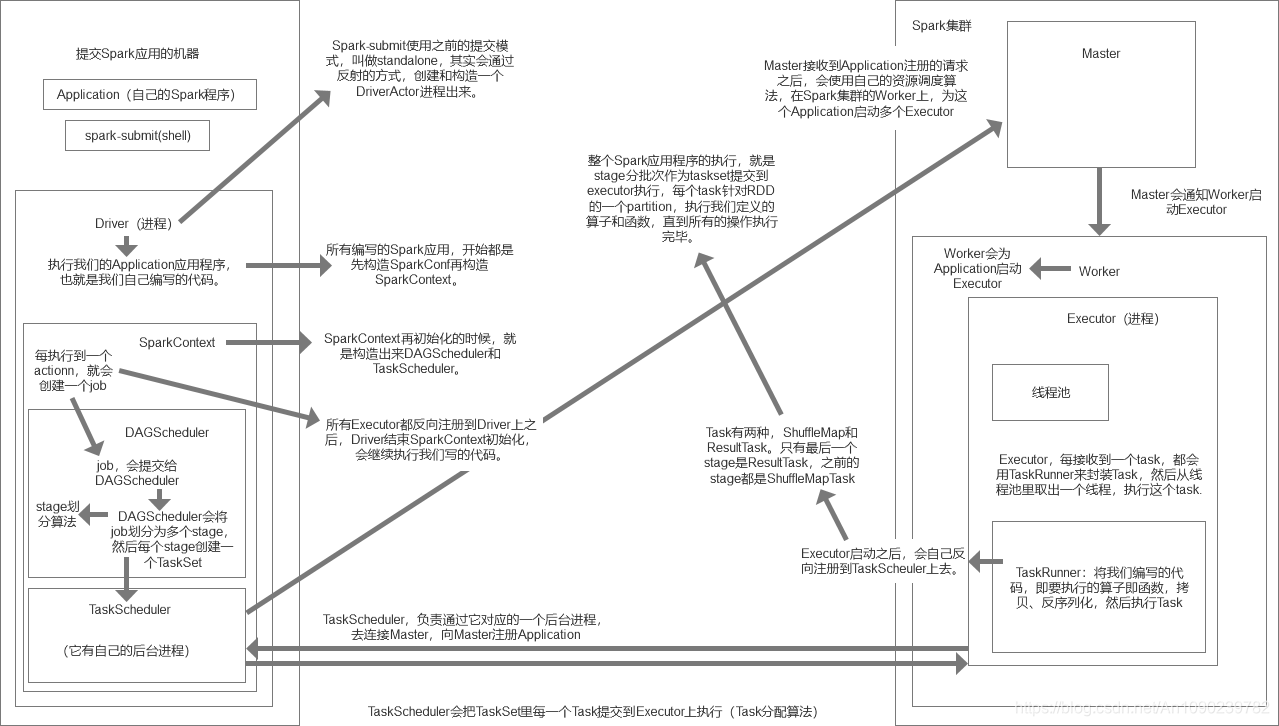
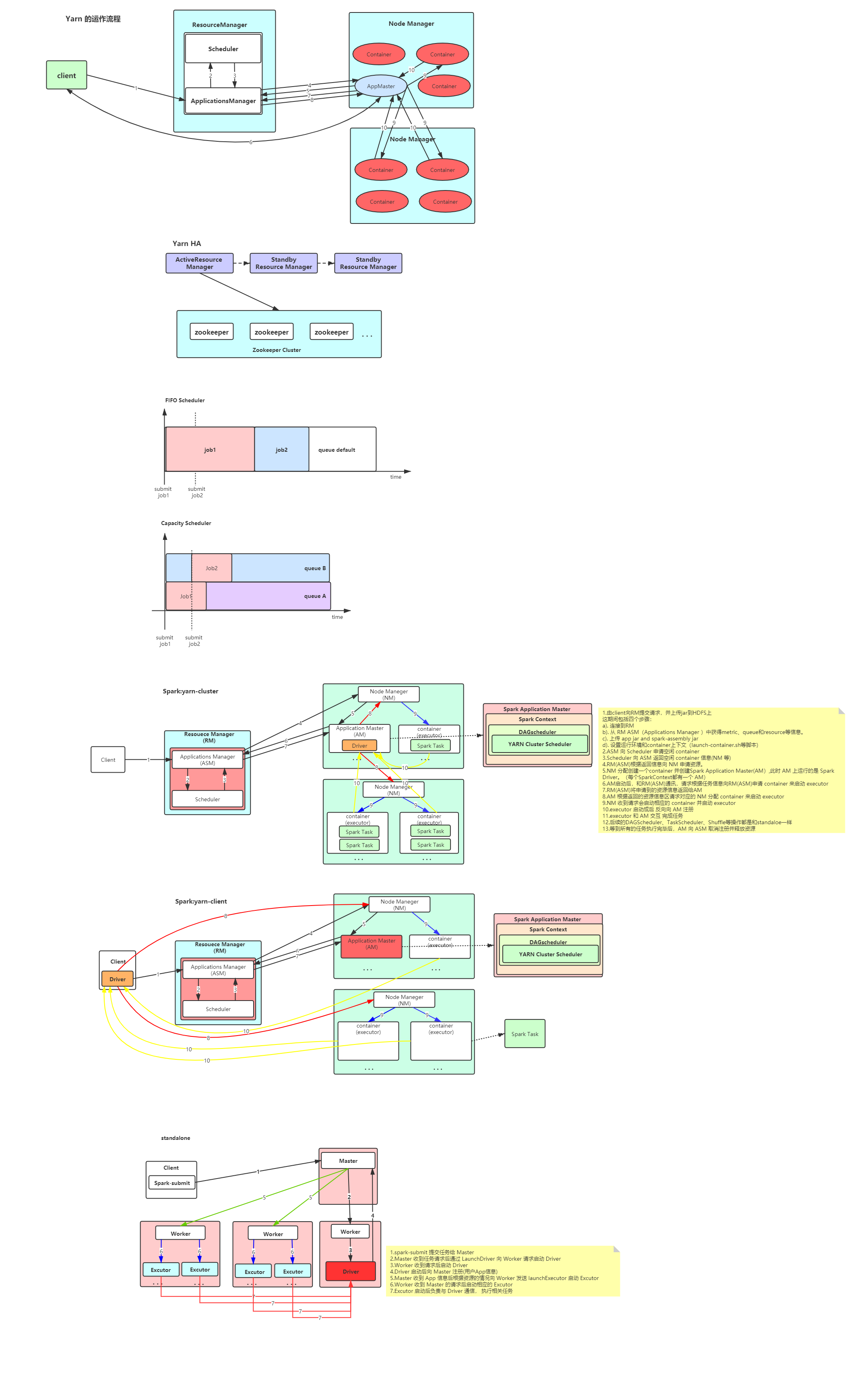
spark 任务提交流程
大数据体系概览Spark、Spark核心原理、架构原理、Spark特点的更多相关文章
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了 转载: 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它 ...
- [大数据从入门到放弃系列教程]第一个spark分析程序
[大数据从入门到放弃系列教程]第一个spark分析程序 原文链接:http://www.cnblogs.com/blog5277/p/8580007.html 原文作者:博客园--曲高终和寡 **** ...
- 大数据技术之_19_Spark学习_04_Spark Streaming 应用解析 + Spark Streaming 概述、运行、解析 + DStream 的输入、转换、输出 + 优化
第1章 Spark Streaming 概述1.1 什么是 Spark Streaming1.2 为什么要学习 Spark Streaming1.3 Spark 与 Storm 的对比第2章 运行 S ...
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
- 【科普杂谈】一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它比作一个厨房所以需要的各种工具.锅碗瓢盆,各有各的用处,互相之间又有重合.你可 ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- 【原创】大数据基础之Hive(5)hive on spark
hive 2.3.4 on spark 2.4.0 Hive on Spark provides Hive with the ability to utilize Apache Spark as it ...
- 大数据平台R语言web UI应用架构 设计与开发
1. 系统拓扑图 在日常业务分析中,R是非常常用的分析工具,而当数据量较大时,用R语言需要需用更多的时间来完成训练模型,spark作为大规模数据处理框架,采用内存计算,可以短时间内完成大量的数据的处理 ...
- 大数据学习(05)——MapReduce/Yarn架构
Hadoop1.x中的MapReduce MapReduce作为Hadoop最核心的两个组件之一,在1.0版本中就已经存在了.它包含这么几个角色: Client 多数情况下Client的作用就是向服务 ...
随机推荐
- java final思考
final关键之主要用在三个方向: 数据 对于基本类型,final使数据恒定不变:而对于对象引用,final使引用恒定不变即无法再重新new另一个对象给他: 空白final JAVA允许定义一个空白f ...
- eclipse 4.4安装aptana插件
eclipse 4.4安装aptana插件: 1.地址: http://download.aptana.com/studio3/plugin/update/index.html.在线安装即可成功! 2 ...
- 每日一个linux命令4
mkdir命令 linux mkdir 命令用来创建指定的名称的目录,要求创建目录的用户在当前目录中具有写权限,并且指定的目录名不能是当前目录中已有的目录. mkdir test 创建一个空目录 ...
- 小米11和iphone12参数对比哪个好
小米11:搭载最新一代三星的AMOLED屏幕,120Hz屏幕刷新,iPhone12使用全新一代的视网膜屏,6.1英寸屏幕,支持60Hz屏幕刷新,支持HDR显示,P3广色域小米手机爆降800 优惠力度空 ...
- instanceof和isInstance的区别
instanceof 是一个操作符(类似new, ==等) ( Object reference variable ) instanceof (class/interface type) if(a i ...
- NOIP初赛篇——04计算机软件系统
计算机软件是指计算机系统中的程序及其文档,也是用户与硬件之间的接口,用户主要通过软件与计算机进行交流,软件是计算机的灵魂.没有安装软件的计算机称为"裸机",无法完成任何工作.一般软 ...
- Pandas应用案例-股票分析:使用tushare包获取股票的历史行情数据进行数据分析
目标: 使用tushare包获取股票的历史行情数据 输出该股票所有收盘比开盘上涨3%以上的日期 输出该股票所有开盘比前日收盘跌幅超过2%以上的日期 假如为我们从2010年1月1日开始,每月第一个交易日 ...
- Http中的options请求
引自:https://www.jianshu.com/p/5cf82f092201.https://www.cnblogs.com/mamimi/p/10602722.html 一.options是什 ...
- Android 8.0/9.0 wifi 自动连接评分机制
前言 Android N wifi auto connect流程分析 Android N selectQualifiedNetwork分析 Wifi自动连接时的评分机制 今天了解了一下Wifi自动连接 ...
- QQ好友状态,QQ群友状态,究竟是推还是拉? 网页端收消息,究竟是推还是拉?
https://mp.weixin.qq.com/s/KB1zdKcsh4PXXuJh4xb_Zw 网页端收消息,究竟是推还是拉? 原创 58沈剑 架构师之路 2020-12-28 https:/ ...