23 mysql怎么保证数据不丢失?
MySQL的wal机制,得到的结论是:只要redo log和binlog 持久化到磁盘,就能确保mysql异常重新启动后,数据是可以恢复的。
binlog的写入机制
其实,binlog的写入逻辑比较简单:事务执行过程中,先把日志写到binlog cache,事务提交的时候,再把binlog cache的内容写到binlog文件中。
一个事务的binlog是不能被拆开的,因此不论事务多大,也要确保一次性写入,这就涉及到binlog cache的保存问题。
系统给binlog cache分配了一片内存,每个线程一个,参数binlog_cache用于控制单个线程内binlog cache所占内存的大小,如果超过这个值,就要暂存磁盘。
事务提交的时候,执行器把binlog cache的完整事务写入到binlog 文件中,并清空binlog cache,状态如图
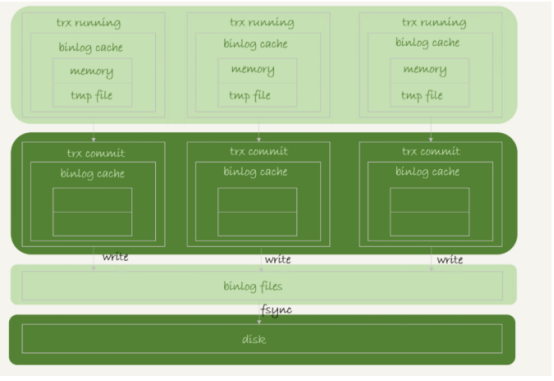
可以看到每个线程都自己的binlog cache,但是公用一个binlog文件。
图中的write就是把日志写入到文件系统中的page cache,并没有把数据持久化到磁盘,所以速度比较快
图中的fsync,将数据持久化到磁盘的操作,一般情况下,我们认为fsync才是占磁盘的IOPS。
write和fsync由参数sync_binlog控制
1 sync_binlog=0 表示每次提交的时候事务都只write,不fsync
2 sync_binlog=1 表示事务每次提交都会fsync到磁盘
3 sync_binlog=N(N>1)表示每次提交事务都会write,但累计N个事务后才fsync
因此,在出现io瓶颈的情况下,可以调整sync_binlog的值偏大一点,可以提升性能,但是在实际业务场景中,考虑到丢失日志量的可控性,一般不建议将该值设置为0,比较常见的是设置为100~1000中的某个数值。
但是,将sync_binlog设置为N,对应的风险是:如果主机发生异常重启,将丢失N个事务的binlog 日志。
redo log的写入机制
事务在执行过程中,生成的redo log是要先写到redo log buffer,那redo log buffer的内容是不是每次生成后都要直接持久化到磁盘呢?答案是不需要,
如果事务运行期间,mysql发生异常重启,那么这部分日志就丢失了,由于事务还没有提交,丢失的就不影响。
那么在事务还没有提交的时候,redo log buffer中的部分日志会不会持久化到磁盘呢?答案是会有的,这个要从redo log的三种状态说起
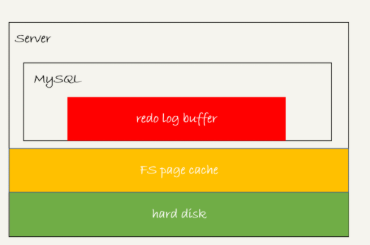
三种状态分别是:
1 存在redo log buffer中,物理上就是mysql的进程内存中,红色部分。
2 写到磁盘(write),但是没有持久化(fsync)到磁盘物理上就是操作系统的page cache,黄色的部分。
3 持久化到磁盘,对应的是hard disk,图中绿色的部分。
日志写到redo log buffer是很快的,write写到page cache也很快,但是持久化的速度就相对要慢很多。为了控制redo log的写入策略,innodb提供了参数innodb_fush_log_at_trx_commit,它有三种取值:
1 设置为0的时候,表示每次事务提交都会只把redo log留在redo log buffer中
2 设置为1的时候,事务的每次提交都会持久化到磁盘
3 设置为2的时候,事务的每次提交都会把redo log 写入到page cache中
Innodb有一个后台线程,每1秒就会把redo log buffer中的写入到redo log,调用write写入系统的page cache,然后调用fsync持久化到磁盘。
注意,事务执行过程中的redo log也是直接写在redo log buffer中的,这些redo log也会被后台线程一起持久化到磁盘,也就是说,一个没有提交的事务的redo log,也可能会已经持久化到了磁盘的。
实际上,除了后台线程每秒一次的轮询操作,还有场景让没有提交的事务的redo log写入到磁盘中。
1 redo log buffer占用的空间即将达到innodb_log_buffer_size的一半,后台线程会主动写盘。注意,由于这个事务并没有提交,所以这个写盘动作只是write,而没有调用fsync,也就是只留在了文件系统page cache中。
2 并行的事务提交的时候,顺带将这个redo log buffer持久到了磁盘。假设事务A执行到一半,已经写了一些redo log buffer,这时候另外一个线程的事务B提交,如果innodb_flush_log_at_trx_commit设置为1,那么按照这个参数的逻辑,事务B要把redo buffer里的日志全部持久化到磁盘,这时候,就会带上事务A的redo log buffer的日子一起持久化到磁盘。
两阶段提交的时候,时序上redo log先prepare,在写binlog,最后再把redo log commit。
如果把参数innodb_flush_log_at_trx_commit设置为1,那么redo log在prepare阶段就要持久化一次,因为有一个崩溃恢复逻辑是要依赖于prepare的redo log,再加上binlog来恢复。
每秒一次的后台轮询刷盘,再加上崩溃恢复的这个逻辑,innodb就认为redo log在commit的时候就不需要fsync了,只会write到文件系统的page cache中就够了。
通常我们说的”双1”模式,就是把参数sync_binlog和innodb_flush_log_at_trx_commit都设置为1。也就说,一个事务完整提交前,需要等待两次刷盘,一次是redo log(prepare)阶段,一次是binlog。
这时候,如果看到mysql的tps是2w的话,每秒就会写4w次磁盘,但是,用工具测试,磁盘能力也就2w左右,怎么实现tps为2w呢?
要解释这个问题,就要用到组提交(group commit)机制了
日志的逻辑序列号(LSN)是单调递增的,用来对应redo log的一个个写入点,每次写入的长度为length的redo log,LSN就会加上length。
LSN也会写到innodb的数据页中,来确保数据不会被多次执行重复的redo log,关于lsn,redo log和checkpoint后面会提到。
如图所示,是三个并发事务(trx1,trx2,trx3)在prepare阶段,都写完redo log buffer,持久化到磁盘的过程,对应的LSN分别是50,120,160
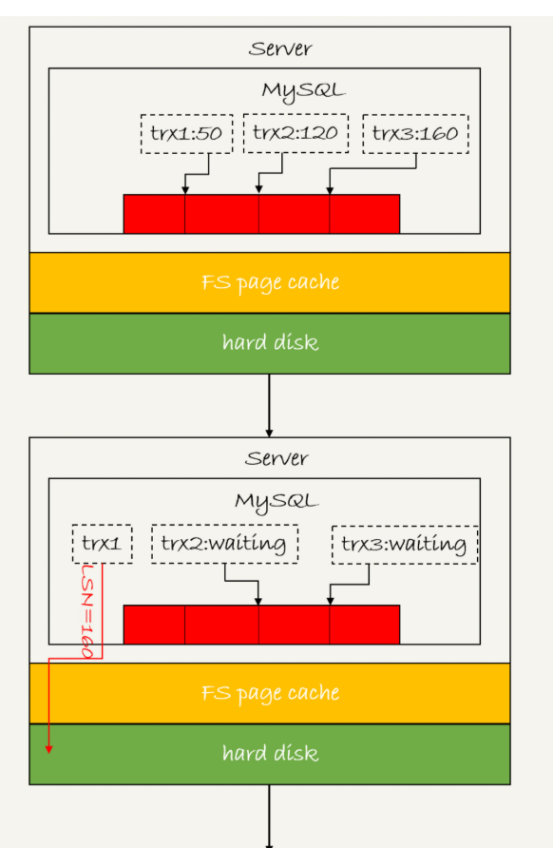
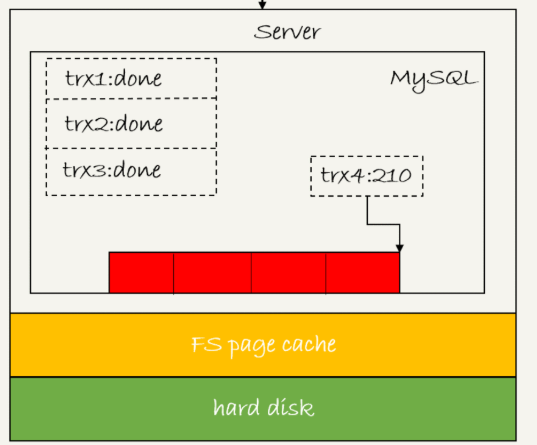
从图中看到
1 trx1是第一个到达,会被选为这个组的leader
2 等trx1要开始写盘的时候,这个组里面已经有了三个事务,这时候LSN变成了160
3 trx1去写盘的时候,带的就是lsn=160,因此等trx1返回时,所有lsn小于160的redo log都已经持久化到磁盘
4 这时候trx2和trx3就可以直接返回了。
所以,一次组提交里面,组员越多,节约磁盘的iops的效果就越好,但如果只是单线程压测,那就还是一个事务对应一次持久化操作了。
在并发更新的场景下,第一个事务写完redo log buffer以后,接下来这个fsync越晚调用,组员就能越多,节约的iops效果就越好。
为了让一次fsync带的组员更多,mysql有一个优化,托时间。
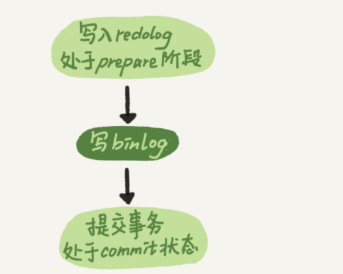
图中,把写binlog当成一个动作,但实际上写binlog分为两步
1 先把binlog从binlog cache中写道磁盘上的binlog文件
2 调用fsync持久化
Mysql为了让组提交的效果更好,把redo log做fsync的时间拖到了步骤1之后,上图变成如下
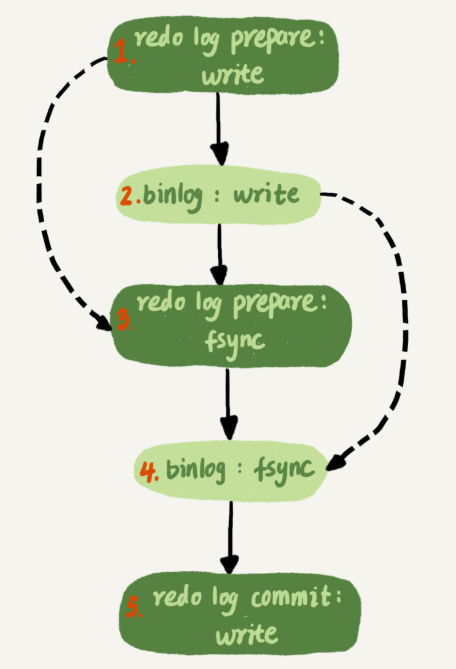
这么一来,binlog也可以组提交了,在执行上图的第四步把binlog fsync到磁盘时,如果有多个事务的binlog已经写完了,也是一起持久化的,这样也可以减少iops的消耗。
不过通常情况下第3步执行得会很快,所以binlog的write和fsync间的间隔很短,导致能合到一起持久化的binlog比较少,因此binlog的组提交的效果通常不如redo log的效果那么好。
如果想提升binlog的组提交效果,可以通过设置(5.7)binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count来实现
1 binlog_group_commit_sync_delay参数,表示延迟多少微妙后才调用fsync
2 binlog_group_commit_sync_no_delay_count 参数,表示累计多少次后才调用fsync
这两个条件是或的关系,也就说只要满足其中一个就会调用fsync
当binlog_group_commit_sync_delay为0的时候,另外的参数也就无效了。
WAL机制主要得益于两个方面
1 redo log和binlog都是顺序写,磁盘的顺序写比随机写速度快。
2 组提交机制,可以大幅度降低磁盘的iops的消耗。
到这里,如果mysql出现了性能瓶颈,而且瓶颈在io上,可以考虑呢些方法来提升?
1 设置binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count参数,减少binlog的写盘次数,这个方法是基于”额外的故意等待来实现”,因此可能会增加语句返回的响应时间,但是没有丢失数据的风险。
2 将sync_binlog设置为大于1的值(100~1000),这样做的风险是,主机掉电会丢失binlog日志。
3 将innodb_flush_log_at_trx_commit=2,这样做的风险是,主机掉电就丢失数据。
不建议把innodb_flush_log_at_trx_commit设置为0,如果=0的话,redo只保存在内存中,这样的话,mysql本身异常重启也会丢失数据,风险太大,
而redo log写到文件系统的page cache的速度也是很快,所以这个参数设置为2和0的性能差不多,但是,这样2就不会在mysql异常重启时丢失数据。
小结
如果保证binlog和redo log是完整的,就可以保证mysql是crash-safe的。
问题1,执行一个update语句以后,再去执行hexdump命令直接查看idb文件,为什么没有看到数据改变?
回答:这可能是因为WAL机制的原因,update语句执行完成,innodb只保证redolog,内存,可能还没来得及将数据写到磁盘。
问题2,为什么binlog cache每个线程自己维护,而redo log buffer是全局公用?
回答:mysql这么设计,binlog是不能”被打断”,一个事务的binlog必须连续写,因此要整个事务完成后,再一起写入到文件里。
而redo log没有这个要求,中间生成的日志可以写到redo log buffer中,还可以被写到磁盘中。
问题3,事务执行期间,还没到提交阶段,如果发生crash,redo log肯定丢失,这会不会导致主备不一致。
回答:不会,这时候binlog还在binlog cache里,没发给备库,carsh后,redo log和binlog都没有,从业务角度看事务还没有提交,所以数据是一致的。
问题4,如果binlog写完后发生crash,这时候还没有给客户端答复就重启了,等客户端重新连接进来,发现事务已经提交成功,这是不是bug
回答:不是,
假设整个事务提交成功了,redo log commit完成了,备库也收到binlog并执行了,但是主库和客户端网络断开了,导致事务成功的包返回不了,这时候客户端收到”网络断开”异常,这种也是算事务成功的,不能认为是bug
实际上数据库的crash-safe保证的是:
1 如果客户端收到事务成功的消息,事务就一定持久化了
2 如果客户端收到失败(比如pk冲突,rollback等)的消息,事务就一定失败了
3 如果客户端收到”执行异常”的消息,应用需要重连通过当前查询来继续后续的逻辑,此时数据库只需要保证内部(数据和日志之间,主库和备库之间)一致就可以了。
23 mysql怎么保证数据不丢失?的更多相关文章
- Spark Streaming使用Kafka保证数据零丢失
来自: https://community.qingcloud.com/topic/344/spark-streaming使用kafka保证数据零丢失 spark streaming从1.2开始提供了 ...
- Kafka如何保证数据不丢失
Kafka如何保证数据不丢失 1.生产者数据的不丢失 kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到,其中状态有0,1,-1. 如果是 ...
- [转帖]kafka 如何保证数据不丢失
kafka 如何保证数据不丢失 https://www.cnblogs.com/MrRightZhao/p/11498952.html 一般我们在用到这种消息中件的时候,肯定会考虑要怎样才能保证数 ...
- kafka 如何保证数据不丢失
一般我们在用到这种消息中件的时候,肯定会考虑要怎样才能保证数据不丢失,在面试中也会问到相关的问题.但凡遇到这种问题,是指3个方面的数据不丢失,即:producer consumer 端数据不丢失 b ...
- Elasticsearch如何保证数据不丢失?
目录 如何保证数据写入过程中不丢 直接落盘的 translog 为什么不怕降低写入吞吐量? 如何保证已写数据在集群中不丢 in-memory buffer 总结 LSM Tree的详细介绍 参考资料 ...
- Spark Streaming和Kafka整合保证数据零丢失
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制.为了体验这个关键的特性,你需要满足以下几个先决条件: 1.输入的数据来自可靠的数据源 ...
- rabbitmq保证数据不丢失方案
rabbitmq如何保证消息的可靠性 1.保证消息不丢失 1.1.开启事务(不推荐) 1.2.开启confirm(推荐) 1.3.开启RabbitMQ的持久化(交换机.队列.消息) 1.4.关闭Rab ...
- kafka保证数据不丢失机制
kafka如何保证数据的不丢失 1.生产者如何保证数据的不丢失:消息的确认机制,使用ack机制我们可以配置我们的消息不丢失机制为-1,保证我们的partition的leader与follower都保存 ...
- Spark Streaming和Kafka整合是如何保证数据零丢失
转载:https://www.iteblog.com/archives/1591.html 当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢 ...
随机推荐
- js 格式化时间日期函数小结2
方法一: // 对Date的扩展,将 Date 转化为指定格式的String // 月(M).日(d).小时(h).分(m).秒(s).季度(q) 可以用 1-2 个占位符, // 年(y)可以用 ...
- spring mvc:拦截器不拦截静态资源的三种处理方式
方案一.拦截器中增加针对静态资源不进行过滤(涉及spring-mvc.xml) <mvc:resources location="/" mapping="/**/* ...
- spring3: 基于Schema的AOP
6.3 基于Schema的AOP 基于Schema的AOP从Spring2.0之后通过“aop”命名空间来定义切面.切入点及声明通知. 在Spring配置文件中,所以AOP相关定义必须放在<a ...
- Educational Codeforces Round 27
期末后恢复性训练,结果完美爆炸... A,题意:2n个人,分成两队,要求无论怎么分配,第一队打赢第二队 #include<bits/stdc++.h> #define fi first # ...
- LeetCode OJ:Product of Array Except Self(除己之外的元素乘积)
Given an array of n integers where n > 1, nums, return an array output such that output[i] is equ ...
- Chrome字体变粗
如图.解决方案,看看CSS中用了什么字体,卸载某个字体. 因为我装了一个新的字体,CSS中有这个字体的网页都会变粗.删掉这个字体就恢复正常了
- PostgreSQL窗口函数(转)
转自:http://time-track.cn/postgresql-window-function.html PostgreSQL提供了窗口函数的特性.窗口函数也是计算一些行集合(多个行组成的集合, ...
- Okhttp源码简单解析(一)
业余时间把源码clone下来大致溜了一遍,并且也参阅了其余大神的博客,在这里把自己的心得记录下来共享之,如有不当的地方欢迎批评指正.本文是Okttp源码解析系列的第一篇,不会深入写太多的东西,本篇只是 ...
- 迁移 Windows 上 Oracle 11.2.0.3.0 到 Linux 上 Oracle 11.2.0.3.0
一.迁移前数据库基本信息统计 查看数据库版本 SELECT * FROM V$VERSION; /* Oracle Database 11g Enterprise Edition Release 11 ...
- Apache中 RewriteCond 规则参数介绍 转
摘要: RewriteCond指令定义了规则生效的条件,即在一个RewriteRule指令之前可以有一个或多个RewriteCond指令.条件之后的重写规则仅在当前URI与Pattern匹配并且满足此 ...