关于抓取js加载出来的内容抓取
一.抓取页面
url=https://www.xuexi.cn/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.html
1..首先通过分析页面会发现该页面中的新闻数据都是动态加载出来的,并且通过抓包工具抓取数据可以发现动态数据也不是ajax请求获取的动态数据(因为没有捕获到ajax请求的数据包),那么只剩下一种可能,该动态数据是js动态生成的。
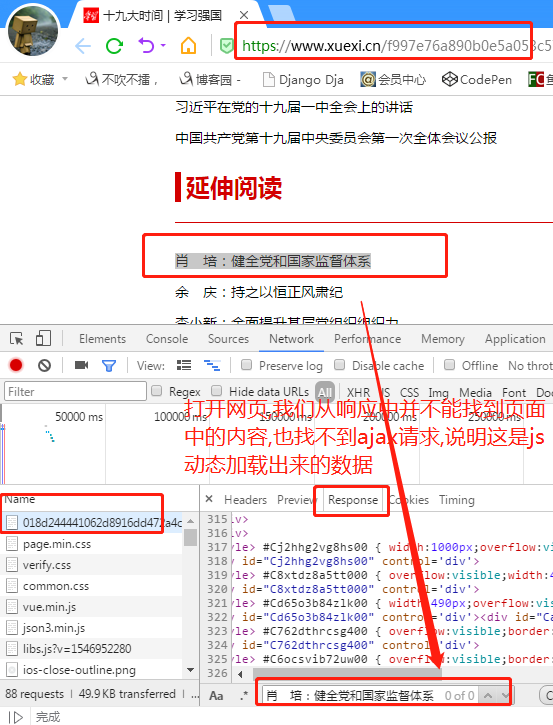
2.通过抓包工具查找到底数据是由哪个js请求产生的动态数据:打开抓包工具,然后对首页url(第一行需求中的url)发起请求,捕获所有的请求数据包。
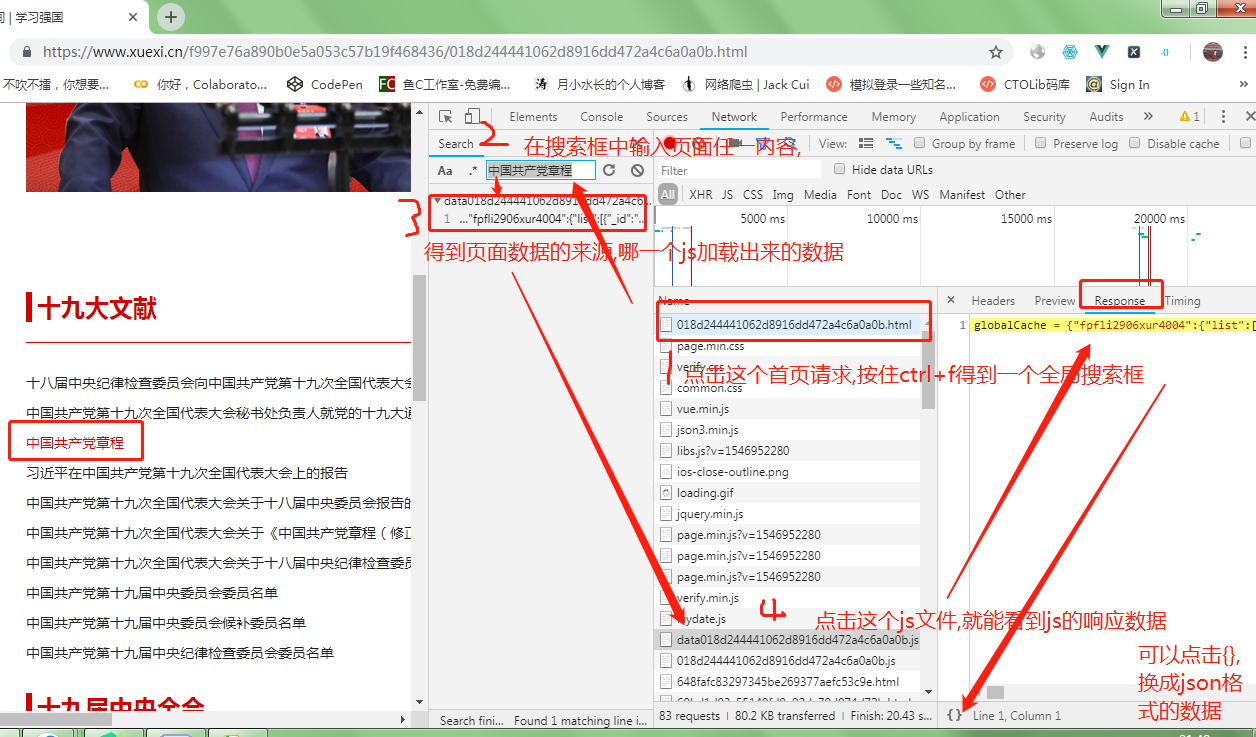
3.分析js数据包响应回来的数据:
该响应数据对应的url可以在抓包工具对应的该数据包的header选项卡中获取。
获取url后,对其发起请求即可获取上图中选中的相应数据,该响应数据类型为
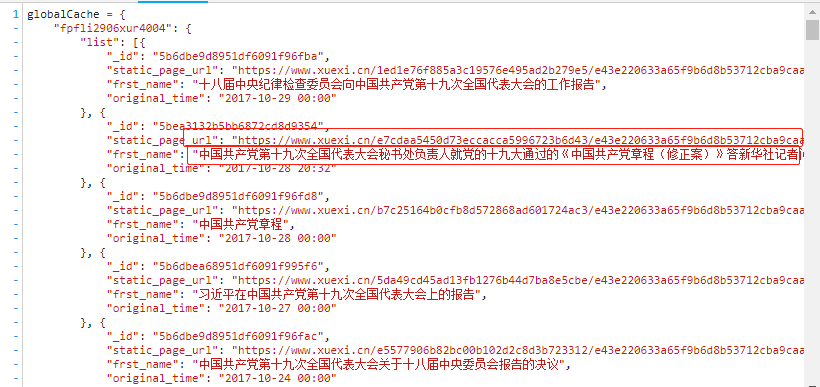
application/javascript类型,所以可以将获取的响应数据通过正则提取出最外层大括号中的数据,
然后使用json.loads将其转为字典类型,然后逐步解析出数据中所有新闻详情页的url即可。4.获取详情页
- 获取详情页中对应的新闻详情数据:对详情页发起请求后,会发现详情页的新闻数据也是动态加载出来的,
因此还是跟上述步骤一样,在抓包工具中对详情页中的局部数据进行搜索,定位到指定的js数据包
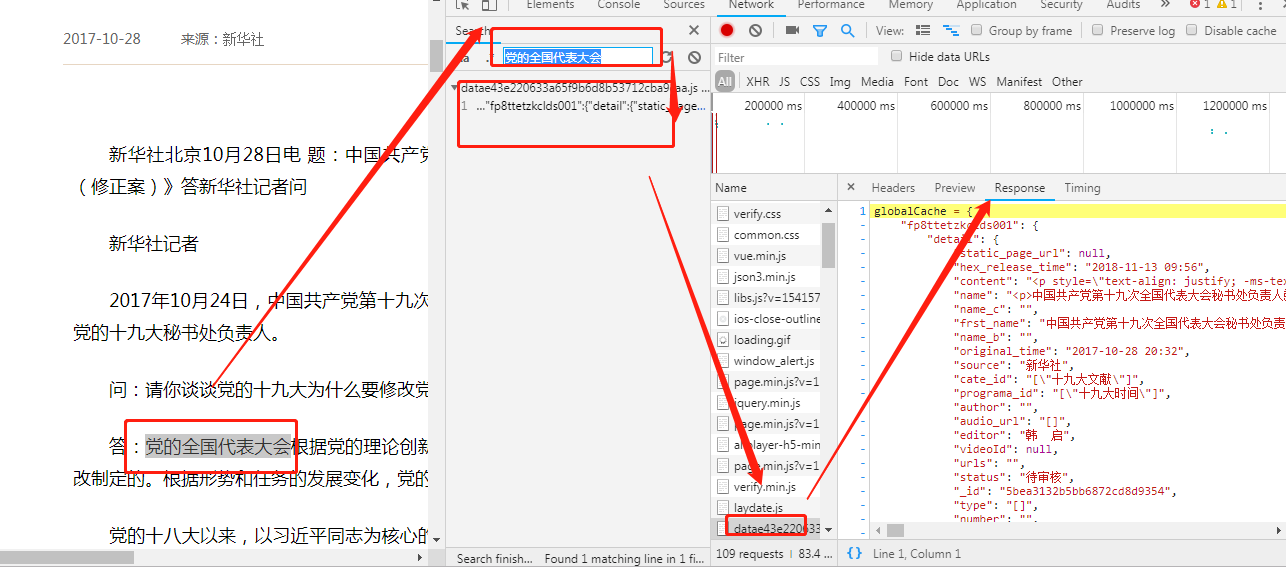
该js数据包的url为:
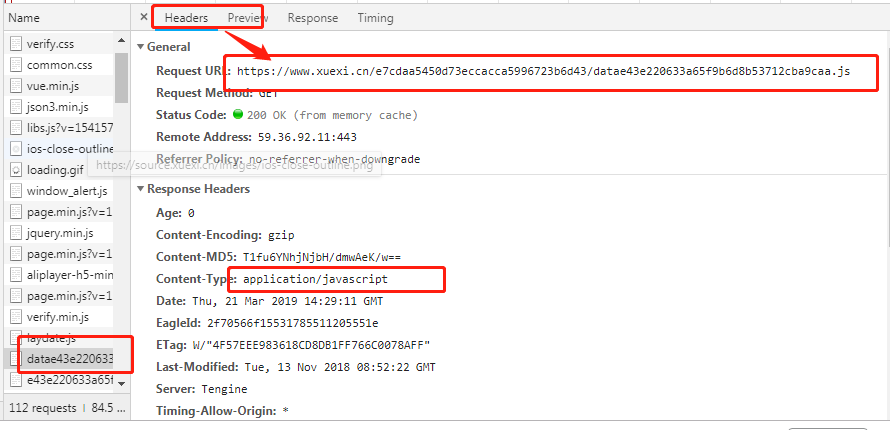
详情页url,获取后,即可请求到该数据包对应的响应数据了,该相应数据中就包含了对应新闻详情数据了。
注意,该响应数据的类型同样为application/javascript,所以数据解析同上!
5.总结发现:
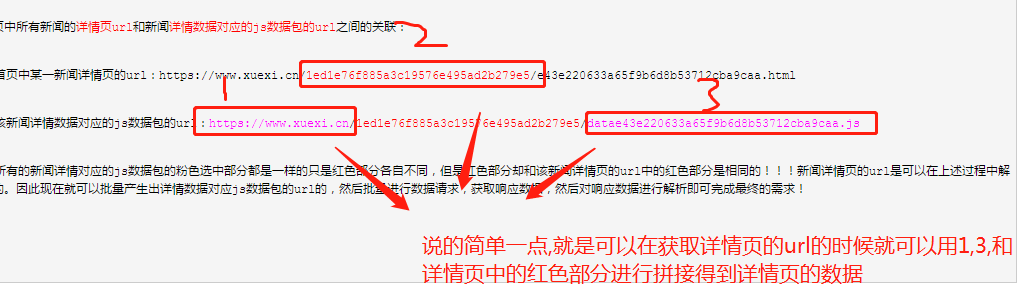
分析首页中所有新闻的详情页url和新闻详情数据对应的js数据包的url之间的关联:
- 首页中某一新闻详情页的url:https://www.xuexi.cn/1ed1e76f885a3c19576e495ad2b279e5/e43e220633a65f9b6d8b53712cba9caa.html
- 该新闻详情数据对应的js数据包的url:https://www.xuexi.cn/1ed1e76f885a3c19576e495ad2b279e5/datae43e220633a65f9b6d8b53712cba9caa.js
- 所有的新闻详情对应的js数据包的粉色选中部分都是一样的只是红色部分各自不同,但是红色部分却和该新闻详情页的url中的红色部分是相同的!!!新闻详情页的url是可以在上述过程中解析出来的。因此现在就可以批量产生出详情数据对应js数据包的url的,然后批量进行数据请求,获取响应数据,然后对响应数据进行解析即可完成最终的需求!
二.关于该网址的另一个子网页
url=https://www.xuexi.cn/261c9a142ef8e6375ed554815a26d585/f2d8ff735982530b7a8c9bb90fa99f68.html
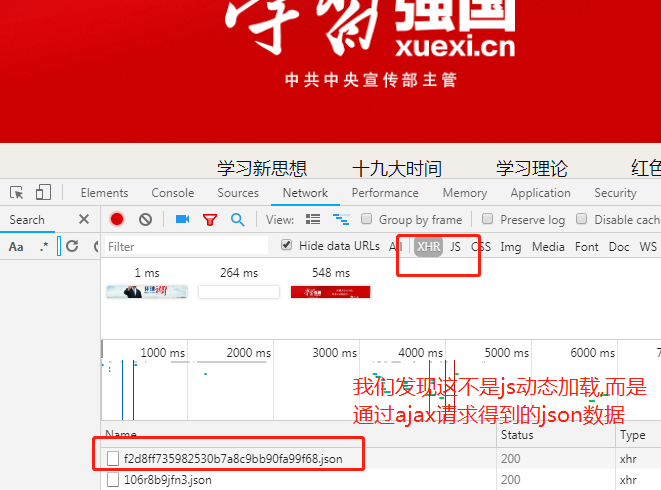
1. 分析发现他的代码不是js动态加载,而是ajax请求得到的一个json文件
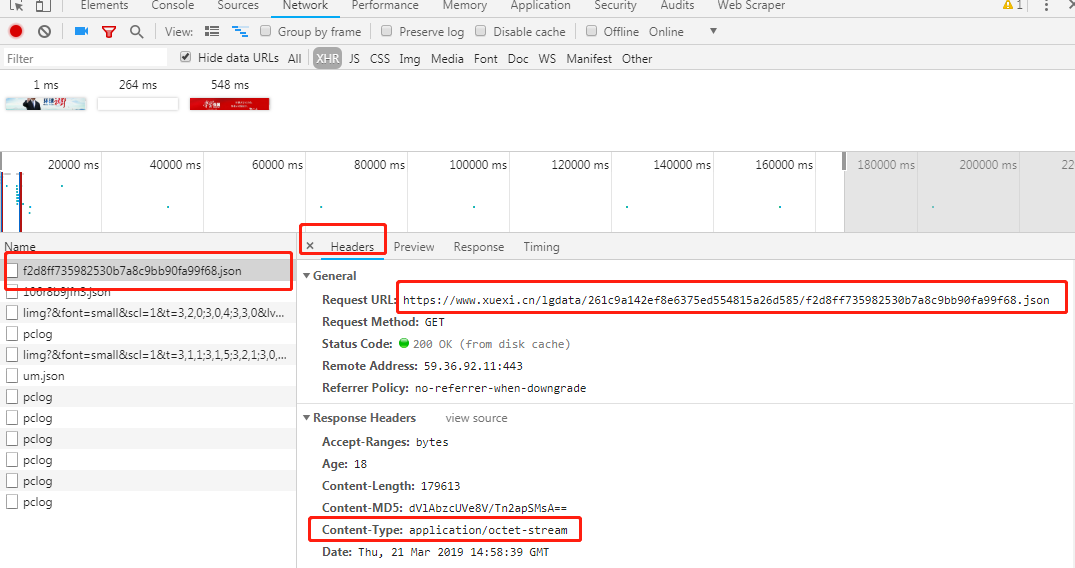
2.再看清一下他的请求头
ajax发起的一个get请求
看了一下contentype:
真尼玛的啃爹.老子不认识你啊,怎么解?不知道,先睡觉去
最近有学习了一个新的库,jsonpath,感觉好用,解析这个网站刚刚好哦,只需要返回的是json格式就行
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#author tom
import requests
from jsonpath import jsonpath
import json
import pymongo
#抓取
def get_url(url):
info_list=[]
data_dic=requests.get(url=url,headers=headers).json()
print(type(data_dic))
link_list=jsonpath(data_dic,"$..list..link")
text_list=jsonpath(data_dic,"$..list..text")
for (text,link) in zip(text_list,link_list):
dic={
'text':text,
'link':link
}
info_list.append(dic)
save(dic) #保存到mongodb,其实这样并不好
#最好是采集完数据再一次性写入,对数据库负担才不大,还没想好,怎么弄
#保存数据源函数
def save(dic):
# 连接数据库
#指定数据库
client = pymongo.MongoClient(host='127.0.0.1', port=27017)
db=client.test
collection=db.xuexi
collection.save(dic) if __name__ == '__main__':
url = 'https://www.xuexi.cn/lgdata/261c9a142ef8e6375ed554815a26d585/f2d8ff735982530b7a8c9bb90fa99f68.json'
headers ={'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'}
get_url(url)
关于抓取js加载出来的内容抓取的更多相关文章
- 爬虫再探实战(三)———爬取动态加载页面——selenium
自学python爬虫也快半年了,在目前看来,我面临着三个待解决的爬虫技术方面的问题:动态加载,多线程并发抓取,模拟登陆.目前正在不断学习相关知识.下面简单写一下用selenium处理动态加载页面相关的 ...
- C#使用phantomjs,爬取AJAX加载完成之后的页面
1.开发思路:入参根据apiSetting配置文件,分配静态文件存储地址,可实现不同站点的静态页生成功能.静态页生成功能使用无头浏览器生成,生成之后的字符串进行正则替换为固定地址,实现本地正常访问. ...
- 优化JS加载时间过长的一种思路
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/. 1.背景 去年公司在漳州的一个项目中,现场工程人员反映地图部分出图有点 ...
- JS 加载html 在IE7 IE8下 可调试
实际背景 就是都是HTML 公共头部底部 然后中间部分加载不同的HTML文件 有点跟模板引擎一样 jQuery 有个load函数 加载html文件的路径 获取html内容 到中间部分 正常下是不能用 ...
- 解决JS加载速度慢
在网页中的js文件引用会很多,js引用通常为 <script src="xxxx.js"></script> 通过如下方法可以增加js加载速度 <sc ...
- FusionCharts简单教程(二)-----使用js加载图像和setDataXML()加载数据
前面一篇对FusionCharts进行了一个简单的介绍,而且建立了我们第一个图形,但是那个是在HTML中使用<OBJECT>和<EMBED>标记来加载图形的,但是这 ...
- [f]动态判断js加载完成
在正常的加载过程中,js文件的加载是同步的,也就是说在js加载的过程中,浏览器会阻塞接下来的内容的解析.这时候,动态加载便显得尤为重要了,由于它是异步加载,因此,它可以在后台自动下载,并不会妨碍其它内 ...
- 使用js加载器动态加载外部Javascript文件
原文:http://www.cnblogs.com/xdp-gacl/p/3927417.html 今天在网上找到了一个可以动态加载js文件的js加载器,具体代码如下: JsLoader.js var ...
- (转)JS加载顺序
原文:http://blog.csdn.net/dannywj1371/article/details/7048076 JS加载顺序 做一名合格的前端开发工程师(12篇)——第一篇 Javascrip ...
随机推荐
- Django--form基础
一.Django--form功能 用户提交数据验证 生成html标签 二.基础实例 需求 利用Django的form功能,接收用户注册信息. urls.py 1 2 3 4 5 from app01 ...
- js加载页面使用execute_script选定加载位置
#由于js逐步加载页面,存在未显示的网页无法加载源码 from selenium import webdriver driver = webdriver.Firefox() init_element ...
- YDNJS(上卷):this 的绑定对象
函数中的 this 是在调用时被绑定的,this 指向谁完全取决于函数的调用位置. 确定 this 的绑定对象的方式有 4 种. 默认绑定 默认绑定就是将函数中的 this 绑定给了全局对象 wind ...
- HTTP协议相关介绍
一.HTTP请求方法 根据HTTP标准,HTTP请求可以使用多种请求方法.HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法.HTTP1.1新增了五种请求方法:OPTIONS, ...
- CORS同源策略
同源策略以及跨域资源共享在大部分情况下针对的是Ajax请求.同源策略主要限制了通过XMLHttpRequest实现的Ajax请求,如果请求的是一个“异源”地址,浏览器将不允许读取返回的内容. 支持同源 ...
- wpf path语法
http://www.cnblogs.com/HQFZ/p/4452548.html WPF系列 Path表示语法详解(Path之Data属性语法)
- 15分XX秒后订单自动关闭(倒计时)
//订单记录 function get_order(){ //请求订单ajax方法 XX.send_api("method",{data},function(){ var date ...
- [other] 代码量代码复杂度统计-lizard
[other] 代码量代码复杂度统计-lizard lizard的可以用来统计下面的一些数据 不包含代码注释的代码行数 CCN 代码的复杂度,也就是分支复杂度 token的个数(关键字,标示符,常量, ...
- 用firebug 进行表单自定义提交
在一些限制网页功能的场合,例如,防止复制内容,防止重复提交,限制操作的时间段/用户等,网页上一些按钮是灰化的(禁用的),这通常是通过设置元素的 disable属性来实现的.但在后台并没有做相应的功能限 ...
- The method identifyUser(Arrays.asList("group001"), String, new HashMap<>()) is undefined for the type AipFace
在使用百度云的人脸识别sdk时遇到了这个错误,网上百度不到解决的方法,当我浏览百度云的时候发现了这个 于是考虑到版本可能更新,出现了新的函数代替旧的函数,于是去查文档,文档链接如下 https://c ...