Hadoop(8)-HDFS的读写数据流程以及机架感知
1. HDFS的写数据流程

1.客户端通过fs模块向NameNode申请文件上传,NameNode检查请求是否合法,如用户权限,目标文件是否已存在,父目录是否存在等等
2.NameNode返回是否可以上传,如果是的话,建立连接通道
3.客户端通过FSDataOutputStream模块请求上传block,NameNode根据网络拓扑距离计算返回的节点,dn1,dn2,dn3
4.客户端与dn1建立连接通道,dn1收到请求后会向dn2发起连接请求,dn2收到请求后会向dn3发起请求.请求通道全部打通后,会从后逐次向前应答,最后应答到客户端,通道建立成功
5.客户端开始上传block,block以packet为单位进行传输,大小为64k,dn1接收到packet后,将packet放入buffer缓冲中,一边往本地磁盘写,一边发送给dn2,dn2接收到后,以同样的方式进行处理和传输给dn3,dn3也进行同样的处理
6.等到block发送完毕后,本次传输结束
2.HDFS的读数据流程
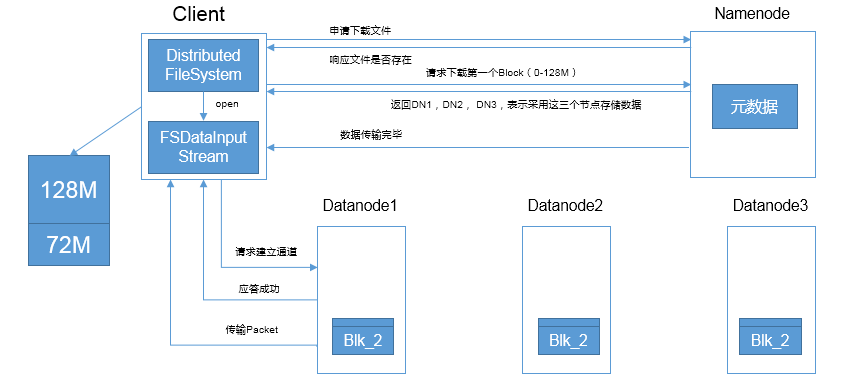
1. 客户端向NameNode申请文件下载,NameNode检查请求的合法性.如果请求合法,返回可以下载的相应,建立连接通道
2. 客户端请求下载文件,NameNode查询元数据,返回DataNode节点,DataNode节点以拓扑距离排序
3. 客户端请求连接第一个DataNode,应答成功后,DataNode开始以Packet传输数据.
4. 客户端接收Packet,边接收边写入磁盘.
5. 文件传输完成,关闭连接.
3.机架感知

通常情况下,如果有三份备份(replication)的话,HDFS的策略是第一个replication在客户端所处的节点上,如果客户端在集群外,从拓扑网络的距离近的节点上随机选一个,第二个replication和第一个replication是同一机架上随机的节点.第三个replication是不同机架上随机的节点
Hadoop(8)-HDFS的读写数据流程以及机架感知的更多相关文章
- 大数据:Hadoop(HDFS 读写数据流程及优缺点)
一.HDFS 写数据流程 写的过程: CLIENT(客户端):用来发起读写请求,并拆分文件成多个 Block: NAMENODE:全局的协调和把控所有的请求,提供 Block 存放在 DataNode ...
- HDFS 读写数据流程
一.上传数据 二.下载数据 三.读写时的节点位置选择 1.网络节点距离(机架感知) 下图中: client 到 DN1 的距离为 4 client 到 NN 的距离为 3 DN1 到 DN2 的距离为 ...
- HDFS读写数据流程
HDFS的组成 1.NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性(创建时间,文件权限,文件大小) 以及每个文件的块列表和块所在的DataNode等.类似于一本书的目录功能. 2 ...
- HDFS 读/写数据流程
1. HDFS 写数据流程 客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件, NameNode 检查目标文件是否已存在,父目录是否存在: NameNo ...
- HDFS数据流——写数据流程
剖析HDFS文件写入 假设文件ss.avi共200m,其写入HDFS指定路径/user/atguigu/ss.avi流程如下: 1)客户端向namenode请求上传文件到指定路径,namenode通过 ...
- Apache Hadoop集群安装(NameNode HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 ).HA的集 ...
- hadoop笔记-hdfs文件读写
概念 文件系统 磁盘进行读写的最小单位:数据块,文件系统构建于磁盘之上,文件系统的块大小是磁盘块的整数倍. 文件系统块一般为几千字节,磁盘块一般512字节. hdfs的block.pocket.chu ...
- Hadoop之HDFS文件读写过程
一.HDFS读过程 1.1 HDFS API 读文件 Configuration conf = new Configuration(); FileSystem fs = FileSystem.get( ...
- Hadoop_08_客户端向HDFS读写(上传)数据流程
1.HDFS的工作机制: HDFS集群分为两大角色:NameNode.DataNode (Secondary Namenode) NameNode负责管理整个文件系统的元数据 DataNode 负责管 ...
随机推荐
- 【Linux】TFTP & NFS 服务器配置
Why?--交叉开发 一.交叉开发模型 宿主机(PC)------ 网络.串口.USB.JTAG ------ 目标机(ARM系统) PC机作为TFTP & NFS 服务器,目标机从网络下载软 ...
- 【Linux】Linux入门及常见基本操作命令详解
本文基于 Red Hat Enterprise Linux 6 一.Linux 入门体验 1.1 root用户登陆 1.2 图形化与纯字符模式切换 init 5 - 图形模式 init 3 - 纯字符 ...
- ORACLE查询删除重复记录三种方法
本文列举了3种删除重复记录的方法,分别是rowid.group by和distinct,小伙伴们可以参考一下. 比如现在有一人员表 (表名:peosons) 若想将姓名.身份证号.住址这三个字段完 ...
- 1.appium介绍
appium介绍 官方网站 1.特点 appium 是一个自动化测试开源工具,支持 iOS 平台和 Android 平台上的原生应用,web应用和混合应用. “移动原生应用”是指那些用iOS或者 An ...
- makefile中的循环控制
GNU make的foreach函数 foreach函数仅GNU make支持: 下面的代码中使用了函数foreach和shell files=main.exe a.exe b.exe all: ec ...
- TCP的建立和关闭
一.TCP头信息 简单的至少应该知道,源端口,目的端口,序号,确认号,标志位,校验和 二.TCP的建立 1.客户端将SYN标志位置1,同时生成随机的序号,确认号是0. 2.服务器接收到SYN,知道有人 ...
- 浅析内存对齐与ANSI C中struct型数据的内存布局-内存对齐规则
这些问题或许对不少朋友来说还有点模糊,那么本文就试着探究它们背后的秘密. 首先,至少有一点可以肯定,那就是ANSI C保证结构体中各字段在内存中出现的位置是随它们的声明顺序依次递增的,并且第一个字段的 ...
- Array GCD CodeForces - 624D (dp,gcd)
大意: 给定序列, 给定常数a,b, 两种操作, (1)任选一个长为$t$的子区间删除(不能全部删除), 花费t*a. (2)任选$t$个元素+1/-1, 花费t*b. 求使整个序列gcd>1的 ...
- php 引用变量
什么是引用: 官方给的解释是:用不同的名字访问同一个变量内容. 1.普通的变量 运行之后内存空间变化是这样的: 2.引用变量 运行之后内存变化是这样的: 几乎没有什么变化. 3.使用unset 销毁的 ...
- 五、设置 IntelliJ IDEA 主题和字体的方法
我们已经用 IntelliJ IDEA 创建了第一个 Java 项目 HelloWorld,如下图所示: 观察上图,大家有没有发现一些问题,例如,整个界面的字体是不是都太小了一点啊?不知道大家感受如何 ...