Radix tree--reference
source address:http://en.wikipedia.org/wiki/Radix_tree
In computer science, a radix tree (also patricia trie or radix trie or compact prefix tree) is a space-optimized trie data structure where each node with only one child is merged with its child. The result is that every internal node has up to the number of children of the radix r of the radix trie, where r is a positive integer and a power x of 2, having x ≥ 1. Unlike in regular tries, edges can be labeled with sequences of elements as well as single elements. This makes them much more efficient for small sets (especially if the strings are long) and for sets of strings that share long prefixes.
Unlike regular trees (where whole keys are compared en masse from their beginning up to the point of inequality), the key at each node is compared chunk-of-bits by chunk-of-bits, where the quantity of bits in that chunk at that node is the radix r of the radix trie. When the r is 2, the radix trie is binary (i.e., compare that node's 1-bit portion of the key), which minimizes sparseness at the expense of maximizing trie depth—i.e., maximizing up to conflation of nondiverging bit-strings in the key. When r is an integer power of 2 greater or equal to 4, then the radix trie is an r-ary trie, which lessens the depth of the radix trie at the expense of potential sparseness.
As an optimization, edge labels can be stored in constant size by using two pointers to a string (for the first and last elements).[1]
Note that although the examples in this article show strings as sequences of characters, the type of the string elements can be chosen arbitrarily; for example, as a bit or byte of the string representation when using multibyte character encodings or Unicode.
Contents
[hide]
Applications
As mentioned, radix trees are useful for constructing associative arrays with keys that can be expressed as strings. They find particular application in the area of IP routing, where the ability to contain large ranges of values with a few exceptions is particularly suited to the hierarchical organization of IP addresses.[2] They are also used for inverted indexes of text documents in information retrieval.
Operations
Radix trees support insertion, deletion, and searching operations. Insertion adds a new string to the trie while trying to minimize the amount of data stored. Deletion removes a string from the trie. Searching operations include (but are not necessarily limited to) exact lookup, find predecessor, find successor, and find all strings with a prefix. All of these operations are O(k) where k is the maximum length of all strings in the set, where length is measured in the quantity of bits equal to the radix of the radix trie.
Lookup


Finding a string in a Patricia trie
The lookup operation determines if a string exists in a trie. Most operations modify this approach in some way to handle their specific tasks. For instance, the node where a string terminates may be of importance. This operation is similar to tries except that some edges consume multiple elements.
The following pseudo code assumes that these classes exist.
Edge
- Node targetNode
- string label
Node
- Array of Edges edges
- function isLeaf()
function lookup(string x)
{
// Begin at the root with no elements found
Node traverseNode := root;
int elementsFound := 0; // Traverse until a leaf is found or it is not possible to continue
while (traverseNode != null && !traverseNode.isLeaf() && elementsFound < x.length)
{
// Get the next edge to explore based on the elements not yet found in x
Edge nextEdge := select edge from traverseNode.edges where edge.label is a prefix of x.suffix(elementsFound)
// x.suffix(elementsFound) returns the last (x.length - elementsFound) elements of x // Was an edge found?
if (nextEdge != null)
{
// Set the next node to explore
traverseNode := nextEdge.targetNode; // Increment elements found based on the label stored at the edge
elementsFound += nextEdge.label.length;
}
else
{
// Terminate loop
traverseNode := null;
}
} // A match is found if we arrive at a leaf node and have used up exactly x.length elements
return (traverseNode != null && traverseNode.isLeaf() && elementsFound == x.length);
}
Insertion
To insert a string, we search the tree until we can make no further progress. At this point we either add a new outgoing edge labeled with all remaining elements in the input string, or if there is already an outgoing edge sharing a prefix with the remaining input string, we split it into two edges (the first labeled with the common prefix) and proceed. This splitting step ensures that no node has more children than there are possible string elements.
Several cases of insertion are shown below, though more may exist. Note that r simply represents the root. It is assumed that edges can be labelled with empty strings to terminate strings where necessary and that the root has no incoming edge.
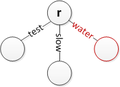
Insert 'water' at the root

Insert 'slower' while keeping 'slow'

Insert 'test' which is a prefix of 'tester'

Insert 'team' while splitting 'test' and creating a new edge label 'st'

Insert 'toast' while splitting 'te' and moving previous strings a level lower
Deletion
To delete a string x from a tree, we first locate the leaf representing x. Then, assuming x exists, we remove the corresponding leaf node. If the parent of our leaf node has only one other child, then that child's incoming label is appended to the parent's incoming label and the child is removed.
Additional operations
- Find all strings with common prefix: Returns an array of strings which begin with the same prefix.
- Find predecessor: Locates the largest string less than a given string, by lexicographic order.
- Find successor: Locates the smallest string greater than a given string, by lexicographic order.
History
Donald R. Morrison first described what he called "Patricia trees" in 1968;[3] the name comes from the acronym PATRICIA, which stands for "Practical Algorithm To Retrieve Information Coded In Alphanumeric". Gernot Gwehenberger independently invented and described the data structure at about the same time.[4] PATRICIA tries are radix tries with radix equals 2, which means that each bit of the key is compared individually and each node is a two-way (i.e., left versus right) branch.
Comparison to other data structures
(In the following comparisons, it is assumed that the keys are of length k and the data structure contains n members.)
Unlike balanced trees, radix trees permit lookup, insertion, and deletion in O(k) time rather than O(log n). This doesn't seem like an advantage, since normallyk ≥ log n, but in a balanced tree every comparison is a string comparison requiring O(k) worst-case time, many of which are slow in practice due to long common prefixes (in the case where comparisons begin at the start of the string). In a trie, all comparisons require constant time, but it takes m comparisons to look up a string of length m. Radix trees can perform these operations with fewer comparisons, and require many fewer nodes.
Radix trees also share the disadvantages of tries, however: as they can only be applied to strings of elements or elements with an efficiently reversible mapping to strings, they lack the full generality of balanced search trees, which apply to any data type with a total ordering. A reversible mapping to strings can be used to produce the required total ordering for balanced search trees, but not the other way around. This can also be problematic if a data type onlyprovides a comparison operation, but not a (de)serialization operation.
Hash tables are commonly said to have expected O(1) insertion and deletion times, but this is only true when considering computation of the hash of the key to be a constant time operation. When hashing the key is taken into account, hash tables have expected O(k) insertion and deletion times, but may take longer in the worst-case depending on how collisions are handled. Radix trees have worst-case O(k) insertion and deletion. The successor/predecessor operations of radix trees are also not implemented by hash tables.
Variants
A common extension of radix trees uses two colors of nodes, 'black' and 'white'. To check if a given string is stored in the tree, the search starts from the top and follows the edges of the input string until no further progress can be made. If the search-string is consumed and the final node is a black node, the search has failed; if it is white, the search has succeeded. This enables us to add a large range of strings with a common prefix to the tree, using white nodes, then remove a small set of "exceptions" in a space-efficient manner by inserting them using black nodes.
The HAT-trie is a radix tree based cache-conscious data structure that offers efficient string storage and retrieval, and ordered iterations. Performance, with respect to both time and space, is comparable to the cache-conscious hashtable.[5][6] See HAT trie implementation notes at [1]
Radix tree--reference的更多相关文章
- Trie / Radix Tree / Suffix Tree
Trie (字典树) "A", "to", "tea", "ted", "ten", "i ...
- 基数树(radix tree)
原文 基数(radix)树 Linux基数树(radix tree)是将指针与long整数键值相关联的机制,它存储有效率,并且可快速查询,用于指针与整数值的映射(如:IDR机制).内存管理等.ID ...
- Linux内核Radix Tree(二)
1. 并发技术 由于需要页高速缓存是全局的,各进程不停的访问,必须要考虑其并发性能,单纯的对一棵树使用锁导致的大量争用是不能满足速度需要的,Linux中是在遍历树的时候采用一种RCU技术,来实现同 ...
- Linux内核Radix Tree(一)
一.概述 Linux radix树最广泛的用途是用于内存管理,结构address_space通过radix树跟踪绑定到地址映射上的核心页,该radix树允许内存管理代码快速查找标识为dirty或wri ...
- Linux 内核中的数据结构:基数树(radix tree)
转自:https://www.cnblogs.com/wuchanming/p/3824990.html 基数(radix)树 Linux基数树(radix tree)是将指针与long整数键值相 ...
- PART(Persistent Adaptive Radix Tree)的Java实现源码剖析
论文地址 Adaptive Radix Tree: https://db.in.tum.de/~leis/papers/ART.pdf Persistent Adaptive Radix Tree: ...
- 一步一步分析Gin框架路由源码及radix tree基数树
Gin 简介 Gin is a HTTP web framework written in Go (Golang). It features a Martini-like API with much ...
- Red–black tree ---reference wiki
source address:http://en.wikipedia.org/wiki/Red%E2%80%93black_tree A red–black tree is a type of sel ...
- Linux内核Radix Tree(三):API介绍
1. 单值查找radix_tree_lookup 函数radix_tree_lookup执行查找操作,查找方法是:从叶子到树顶,通过数组索引键值值查看数组元素的方法,一层层地查找slot.其列 ...
- The router relies on a tree structure which makes heavy use of common prefixes, it is basically a compact prefix tree (or just Radix tree).
https://github.com/julienschmidt/httprouter/
随机推荐
- .Net中的并行编程-1.路线图(转)
大神,大神,膜拜膜拜,原文地址:http://www.cnblogs.com/zw369/p/3834559.html 目录 .Net中的并行编程-1.路线图 分析.Net里线程同步机制 .Net中的 ...
- GeoServer中GeoWebCache(GWC)的使用
本文介绍GeoWebCache的使用方法,包括如何切缓存,访问缓存wms/wmts服务,如何复用栅格缓存等. 文章大部分内容转载自https://www.cnblogs.com/naaoveGIS/p ...
- git Problem with the SSL CA cert (path? access rights?)
问题: [root@localhost opt]# git clone https://github.com/docker/docker.git 正克隆到 'docker'...fatal: unab ...
- VM12安装Mac系统操作指南
1.第一步,操作按照这个链接来搞 VMware 12安装Mac OS 系统使用的是 OS X 10.11.1(15B42) 2.激活工具一定要使用 unlocker208 3.初次安装可能存在的报错 ...
- 【bzoj4514】: [Sdoi2016]数字配对 图论-费用流
[bzoj4514]: [Sdoi2016]数字配对 好像正常的做法是建二分图? 我的是拆点然后 S->i cap=b[i] cost=0 i'->T cap=b[i] cost=0 然后 ...
- soapui
webservice 的请求可使用工具:soapui 天气预报的接口地址:http://www.webxml.com.cn/WebServices/WeatherWebService.asmx?wsd ...
- leecode刷题(1)-- 删除排序数组中的重复项
删除排序数组中的重复项 给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度.不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的 ...
- [原创]ObjectARX开发环境搭建之VS2010+ObjectARX2012Wizard+Addin工具条问题修复
目前ObjectARX版本越来越高,也越来越简化开发,如果需要同时开发低版本和高版本的ARX程序,就需要搭建批量编译环境,以满足ARX开发的需要. 批量编译的搭建网络上已经有了很多的教程,基本上都是基 ...
- P2645 斯诺克 题解
P2645 斯诺克 题目背景 镇海中学开设了很多校本选修课程,有体育类.音乐类.美术类.无线电测向.航空航海航天模型制作等,力争使每位学生高中毕业后,能学到一门拿得出手的兴趣爱好,为将来的终身发展打下 ...
- 10、C++函数
1.定义函数和函数调用: 1.1.定义函数: 可以将函数分为两类,没有返回值的函数,和有返回值得函数,没有返回值得函数被称为void函数,其通用格式如下: void funtionname (para ...