二分类问题续 - 【老鱼学tensorflow2】
前面我们针对电影评论编写了二分类问题的解决方案。
这里对前面的这个方案进行一些改进。
分批训练
model.fit(x_train, y_train, epochs=20, batch_size=512)
这里在训练时增加了一个参数batch_size,使用 512 个样本组成的小批量,将模型训练 20 个轮次。
这个参数可以看成是在训练时不一次性在全部的训练集上进行,而是针对其中的512个题目分批次进行训练。有点类似做512道题目进行训练,然后看结果进行调整,而不是一次性做好25000道题目然后再对答案看哪里有问题。
这样的结果是训练的速度有很明显的提高,原先在我的机器上训练一个轮次要6秒,增加了这个批次参数后,训练一个轮次只要1秒。
数据集再分类
首先我们对数据集进行一下再分类。
前面我们使用了训练集和测试集。
训练集是用来训练数据的,有点类似学习中的练习题;
测试集有点类似考试题。
一般来讲测试集对我们是未知的,我们不知道要考什么试题。
为了能够在练习时我们也能知道当前的学习状况,因此我们会把练习题分出一部分来当做单元测试,这样我们不必等到未知的考题中来了解自己的学习状况。
这里的单元测试题就是验证集。
代码实现为:
# 分解验证集
x_val = x_train[:10000]
y_val = y_train[:10000]
x_train = x_train[10000:]
y_train = y_train[10000:]
#编译模型
model.compile(optimizer=keras.optimizers.RMSprop(), loss=keras.losses.binary_crossentropy, metrics=[keras.metrics.binary_accuracy])
#训练模型
model.fit(x_train, y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val))
绘制训练图形
在训练过程中控制台中会打印出如下的信息:
Train on 15000 samples, validate on 10000 samples
Epoch 1/20
15000/15000 [==============================] - 5s 317us/sample - loss: 0.5072 - binary_accuracy: 0.7900 - val_loss: 0.3850 - val_binary_accuracy: 0.8713
Epoch 2/20
15000/15000 [==============================] - 1s 66us/sample - loss: 0.3022 - binary_accuracy: 0.9020 - val_loss: 0.3317 - val_binary_accuracy: 0.8628
Epoch 3/20
15000/15000 [==============================] - 1s 52us/sample - loss: 0.2223 - binary_accuracy: 0.9283 - val_loss: 0.2890 - val_binary_accuracy: 0.8851
Epoch 4/20
15000/15000 [==============================] - 1s 52us/sample - loss: 0.1773 - binary_accuracy: 0.9424 - val_loss: 0.3087 - val_binary_accuracy: 0.8766
Epoch 5/20
15000/15000 [==============================] - 1s 53us/sample - loss: 0.1422 - binary_accuracy: 0.9546 - val_loss: 0.2819 - val_binary_accuracy: 0.8882
Epoch 6/20
15000/15000 [==============================] - 1s 57us/sample - loss: 0.1203 - binary_accuracy: 0.9635 - val_loss: 0.2935 - val_binary_accuracy: 0.8846
Epoch 7/20
15000/15000 [==============================] - 1s 57us/sample - loss: 0.0975 - binary_accuracy: 0.9709 - val_loss: 0.3163 - val_binary_accuracy: 0.8809
Epoch 8/20
15000/15000 [==============================] - 1s 53us/sample - loss: 0.0799 - binary_accuracy: 0.9778 - val_loss: 0.3383 - val_binary_accuracy: 0.8781
Epoch 9/20
15000/15000 [==============================] - 1s 52us/sample - loss: 0.0666 - binary_accuracy: 0.9814 - val_loss: 0.3579 - val_binary_accuracy: 0.8766
Epoch 10/20
15000/15000 [==============================] - 1s 56us/sample - loss: 0.0519 - binary_accuracy: 0.9879 - val_loss: 0.3926 - val_binary_accuracy: 0.8808
Epoch 11/20
15000/15000 [==============================] - 1s 57us/sample - loss: 0.0430 - binary_accuracy: 0.9899 - val_loss: 0.4163 - val_binary_accuracy: 0.8712
Epoch 12/20
15000/15000 [==============================] - 1s 58us/sample - loss: 0.0356 - binary_accuracy: 0.9921 - val_loss: 0.5044 - val_binary_accuracy: 0.8675
Epoch 13/20
15000/15000 [==============================] - 1s 54us/sample - loss: 0.0274 - binary_accuracy: 0.9943 - val_loss: 0.4995 - val_binary_accuracy: 0.8748
Epoch 14/20
15000/15000 [==============================] - 1s 53us/sample - loss: 0.0225 - binary_accuracy: 0.9957 - val_loss: 0.5040 - val_binary_accuracy: 0.8748
Epoch 15/20
15000/15000 [==============================] - 1s 53us/sample - loss: 0.0149 - binary_accuracy: 0.9984 - val_loss: 0.5316 - val_binary_accuracy: 0.8703
Epoch 16/20
15000/15000 [==============================] - 1s 52us/sample - loss: 0.0137 - binary_accuracy: 0.9984 - val_loss: 0.5672 - val_binary_accuracy: 0.8676
Epoch 17/20
15000/15000 [==============================] - 1s 51us/sample - loss: 0.0116 - binary_accuracy: 0.9985 - val_loss: 0.6013 - val_binary_accuracy: 0.8680
Epoch 18/20
15000/15000 [==============================] - 1s 52us/sample - loss: 0.0060 - binary_accuracy: 0.9998 - val_loss: 0.6460 - val_binary_accuracy: 0.8636
Epoch 19/20
15000/15000 [==============================] - 1s 51us/sample - loss: 0.0067 - binary_accuracy: 0.9993 - val_loss: 0.6791 - val_binary_accuracy: 0.8673
Epoch 20/20
15000/15000 [==============================] - 1s 53us/sample - loss: 0.0074 - binary_accuracy: 0.9987 - val_loss: 0.7243 - val_binary_accuracy: 0.8645
这里会显示出训练集和验证集对应的损失值和精度。
数值上来看不是很直观,我们可以通过图形的方式来进行查看。
在调用model.fit()函数后会有一个返回值:
history = model.fit(x_train, y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val))
这个对象有一个成员 history,它是一个字典,包含训练过程中的所有数据。我们来看一下。
history = model.fit(x_train, y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val))
history_map = history.history
print("history_map:", history_map)
这里的history_map其中的key为:loss,val_loss,binary_accuracy,val_binary_accuracy
我们可以绘制一下训练集和验证集的损失值:loss,val_loss
#训练模型
history = model.fit(x_train, y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val))
history_map = history.history
print("history_map:", history_map)
# 绘制训练集和验证集的损失值
loss_values = history_map['loss']
val_loss_values = history_map['val_loss']
epochs = range(1, len(loss_values) + 1)
import matplotlib.pyplot as plt
plt.plot(epochs, loss_values, label='Training loss')
plt.plot(epochs, val_loss_values, label='Validation loss')
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
运行上述代码时发生了如下的错误:
OMP: Error #15: Initializing libomp.dylib, but found libiomp5.dylib already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://openmp.llvm.org/
需要在绘制图形前设置如下的值:
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
这样显示的损失值图形为:
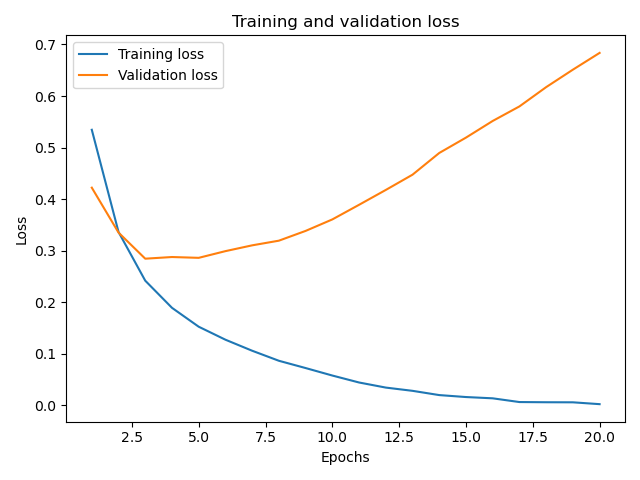
从这个图形中我们发现随着训练迭代次数的增加,训练集中的损失值在不停减小,但是对于验证集的损失值在3-4次时反而增加了。
显示训练集和验证集精度图形
# 显示训练集和验证集的精度
binary_accuracy_values = history_map['binary_accuracy']
val_binary_accuracy_values = history_map['val_binary_accuracy']
plt.clf() #清空图像
plt.plot(epochs, binary_accuracy_values, label='Training accuracy')
plt.plot(epochs, val_binary_accuracy_values, label='Validation accuracy')
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
图形显示为:
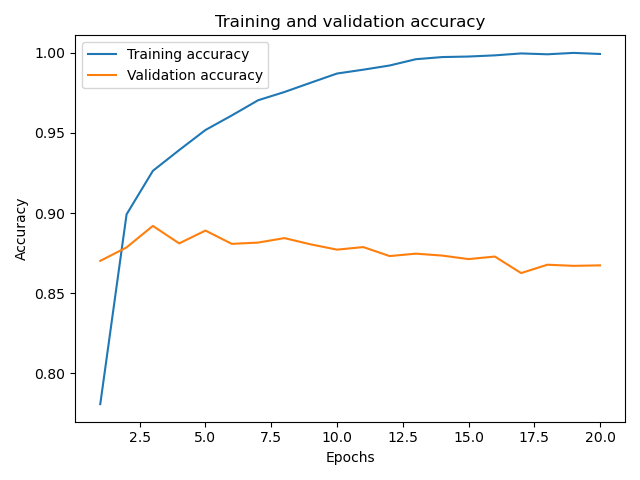
可以看到随着迭代次数的增加,训练集的精度一直在提高,但是验证集的精度在迭代3-4次之后并没有一个显著的提高。
这里就可能存在一个过拟合的现象,也就是在训练集中模型有很好的表现,但在验证集和测试集中模型的结果并没有很好的表现。
在这种情况下,为了防止过拟合,我们可以在 4 轮之后停止训练。通常来说,我们可以使用许多方法来降低过拟合,我们将在后面的博文中再来介绍。
目前完整的代码为:
import tensorflow.keras as keras
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=10000)
# print("x_train:", x_train, "y_train:", y_train)
# data = keras.datasets.imdb.get_word_index()
# word_map = dict([(value, key) for (key,value) in data.items()])
# words = []
# for word_index in x_train[0]:
# words.append(word_map[word_index])
# print(" ".join(words))
import numpy as np
def vectorize_sequence(data, words_size = 10000):
words_vector = np.zeros((len(data), words_size))
for row, word_index in enumerate(data):
words_vector[row, word_index] = 1.0
return words_vector
x_train = vectorize_sequence(x_train)
x_test = vectorize_sequence(x_test)
#构建模型
model = keras.models.Sequential()
model.add(keras.layers.Dense(16, activation=keras.activations.relu, input_shape=(10000, )))
model.add(keras.layers.Dense(16, activation=keras.activations.relu))
model.add(keras.layers.Dense(1, activation=keras.activations.sigmoid))
# 分解验证集
x_val = x_train[:10000]
y_val = y_train[:10000]
x_train = x_train[10000:]
y_train = y_train[10000:]
#编译模型
model.compile(optimizer=keras.optimizers.RMSprop(), loss=keras.losses.binary_crossentropy, metrics=[keras.metrics.binary_accuracy])
#训练模型
history = model.fit(x_train, y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val))
history_map = history.history
print("history_map:", history_map)
# 绘制训练集和验证集的损失值
loss_values = history_map['loss']
val_loss_values = history_map['val_loss']
epochs = range(1, len(loss_values) + 1)
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
import matplotlib.pyplot as plt
plt.plot(epochs, loss_values, label='Training loss')
plt.plot(epochs, val_loss_values, label='Validation loss')
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
# 显示训练集和验证集的精度
binary_accuracy_values = history_map['binary_accuracy']
val_binary_accuracy_values = history_map['val_binary_accuracy']
plt.clf() #清空图像
plt.plot(epochs, binary_accuracy_values, label='Training accuracy')
plt.plot(epochs, val_binary_accuracy_values, label='Validation accuracy')
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
# 测试
results = model.evaluate(x_test, y_test)
print(results)
# 预测
results = model.predict(x_test)
print(results)
为了调优模型,你可以尝试着增加更多的隐藏层,调整隐藏层中的单元个数,调整损失函数,调整激活函数,调整这些参数之后再来看下模型的精度的变化。
更多参考系列文章:老鱼学机器学习&深度学习目录
二分类问题续 - 【老鱼学tensorflow2】的更多相关文章
- 二分类问题 - 【老鱼学tensorflow2】
什么是二分类问题? 二分类问题就是最终的结果只有好或坏这样的一个输出. 比如,这是好的,那是坏的.这个就是二分类的问题. 我们以一个电影评论作为例子来进行.我们对某部电影评论的文字内容为好评和差评. ...
- tensorflow RNN循环神经网络 (分类例子)-【老鱼学tensorflow】
之前我们学习过用CNN(卷积神经网络)来识别手写字,在CNN中是把图片看成了二维矩阵,然后在二维矩阵中堆叠高度值来进行识别. 而在RNN中增添了时间的维度,因为我们会发现有些图片或者语言或语音等会在时 ...
- tensorflow卷积神经网络-【老鱼学tensorflow】
前面我们曾有篇文章中提到过关于用tensorflow训练手写2828像素点的数字的识别,在那篇文章中我们把手写数字图像直接碾压成了一个784列的数据进行识别,但实际上,这个图像是2828长宽结构的,我 ...
- numpy有什么用【老鱼学numpy】
老鱼为了跟上时代潮流,也开始入门人工智能.机器学习了,瞬时觉得自己有点高大上了:). 从机器学习的实用系列出发,我们会以numpy => pandas => scikit-learn =& ...
- 为何学习matplotlib-【老鱼学matplotlib】
这次老鱼开始学习matplotlib了. 在上个pandas最后一篇博文中,我们已经看到了用matplotlib进行绘图的功能,这次更加系统性地学习一下关于matplotlib的功能. matlab由 ...
- tensorflow分类-【老鱼学tensorflow】
前面我们学习过回归问题,比如对于房价的预测,因为其预测值是个连续的值,因此属于回归问题. 但还有一类问题属于分类的问题,比如我们根据一张图片来辨别它是一只猫还是一只狗.某篇文章的内容是属于体育新闻还是 ...
- matplotlib坐标轴设置续-【老鱼学matplotlib】
本次会讲解如何修改坐标轴的位置. 要修改轴,就要先得到当前轴:plt.gca(),这个函数名挺怪的,其实是如下英文字母的首字母:get current axis,也就是得到当前的坐标轴. import ...
- python开发环境搭建及numpy基本属性-【老鱼学numpy】
目的 本节我们将介绍如何搭建python的开发环境以及numpy的基本属性,这样可以检验我们的numpy是否安装正确了. python开发环境的搭建 工欲善其事必先利其器,我用得比较顺手的是Intel ...
- numpy的基础运算-【老鱼学numpy】
概述 本节主要讲解numpy数组的加减乘除四则运算. np.array()返回的是numpy的数组,官方称为:ndarray,也就是N维数组对象(矩阵),N-dimensional array obj ...
随机推荐
- 位运算处理字符大小写转换 - 关联Leetcode 709. 转成小写字母
大写变小写.小写变大写 : 字符 ^= 32; 大写变小写.小写变小写 : 字符 |= 32; 小写变大写.大写变大写 : 字符 &= -33; 题目 实现函数 ToLowerCase(),该 ...
- 浅谈 FTP、FTPS 与 SFTP
无论是网盘还是云存储,上传都是一项很简单的操作.那些便捷好用的上传整理工具所用的 FTP 协议到底是什么意义,繁杂的模式又有何区别? 二狗子最近搭建了一个图片分享网站,每天都有好多人在他的网站上传许多 ...
- 使用Unity的50个建议
关于这些建议 这些建议并不适用于所有的项目 这些建议是基于我与3-20人的小团队项目经验总结出来的 结构.可重复使用性.明晰度都是有价的——团队规模和项目规模决定了是否值得付这个价. 一些建议也许公然 ...
- 小程序开发-组件navigator导航篇
navigator 页面链接 navigator的open-type属性 可选值 navigate.redirect.switchTab,对应于wx.navigateTo.wx.redirectTo. ...
- C#知识点:抽象类和接口浅谈
首先介绍什么是抽象类? 抽象类用关键字abstract修饰的类就是叫抽象类,抽象类天生的作用就是被继承的,所以不能实例化,只能被继承.而且 abstract 关键字不能和sealed一起使用,因为se ...
- 转载:Window配置Redis环境和简单使用
原作:https://www.cnblogs.com/wxjnew/p/9160855.html 我自己的尝试:https://www.cnblogs.com/xiandedanteng/p/1214 ...
- 原生JDK网络编程- NIO
什么是NIO? NIO 库是在 JDK 1.4 中引入的.NIO 弥补了原来的 I/O 的不足,它在标准 Java 代码中提供了高速的.面向块的 I/O.NIO翻译成 no-blocking io 或 ...
- YOLOv4: Darknet 如何于 Docker 编译,及训练 COCO 子集
YOLO 算法是非常著名的目标检测算法.从其全称 You Only Look Once: Unified, Real-Time Object Detection ,可以看出它的特性: Look Onc ...
- Ant Jmeter Jenkins生成html测试报告
Ant配置1. 将jmeter安装目录或者源码目录下\apache-jmeter-3.1\extras的ant-jmeter-1.1.1.jar复制到ant安装目录下apache-ant-1.10.3 ...
- ui自动化--鼠标操作ActionChains
需要先引入鼠标操作模块:from selenium.webdriver.common.action_chains import ActionChains 实际上ActionChains这个模块的实现的 ...