ES中文分词器安装以及自定义配置
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了。
ik分词器的下载和安装,测试
第一: 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases ,这里你需要根据你的Es的版本来下载对应版本的IK,这里我使用的是6.8.10的ES,所以就下载ik-6.8.10.zip的文件。
解压-->将文件复制到 es的安装目录/plugin/ik下面即可,完成之后效果如下:
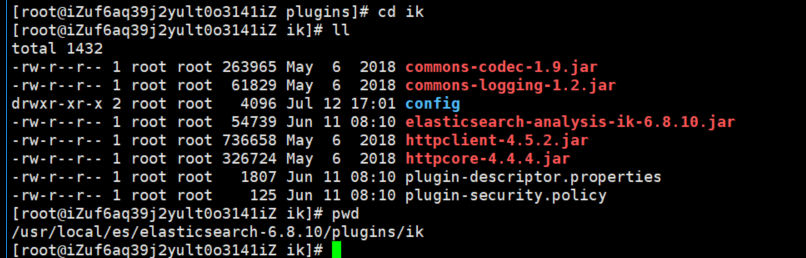
到这里已经完成了,不需要去elasticSearch的 elasticsearch.yml 文件去配置。
重启ElasticSearch
测试效果
未使用ik分词器的效果
### 原生分词
GET /_analyze
{
"analyzer": "standard",
"text": "中华人民共和国"
}
效果:
{
"tokens" : [
{
"token" : "中",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "华",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "人",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "民",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "共",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "和",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 6
}
]
}
ik_smart分词效果:
# ik_smart:会做最粗粒度的拆分
GET /_analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
效果:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
}
]
}
ik_max_word会将文本做最细粒度的拆分
## ik_max_word会将文本做最细粒度的拆分
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国"
}
效果:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 8
}
]
}
对于上面两个分词效果的解释:
- 如果未安装ik分词器,那么,你如果写 "analyzer": "ik_max_word",那么程序就会报错,因为你没有安装ik分词器
- 如果你安装了ik分词器之后,你不指定分词器,不加上 "analyzer": "ik_max_word" 这句话,那么其分词效果跟你没有安装ik分词器是一致的,也是分词成每个汉字。
自定义扩展词
一些热词,自定义的词,ik是不会收录的,这时候我们需要自定义扩展。
比如:王者荣耀。
分词的效果如下,显然是不满足我们需求的,这时候就需要自定义.
GET /_analyze
{
"analyzer": "ik_smart",
"text": "王者荣耀"
}
效果:
{
"tokens" : [
{
"token" : "王者",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "荣耀",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
}
]
}
在config目录下新建ext.dic文件
王者荣耀
进入 es安装目录/plugins/ik/config
编辑IKAnalyzer.cfg.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
重启es,测试效果
{
"tokens" : [
{
"token" : "王者荣耀",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
}
]
}
ES中文分词器安装以及自定义配置的更多相关文章
- solr4.7中文分词器(ik-analyzer)配置
solr本身对中文分词的处理不是太好,所以中文应用很多时候都需要额外加一个中文分词器对中文进行分词处理,ik-analyzer就是其中一个不错的中文分词器. 一.版本信息 solr版本:4.7.0 需 ...
- elasticsearch ik中文分词器安装
特殊说明:灰色文字用来辅助理解的. 安装IK中文分词器 我在百度上搜索了下,大多介绍的都是用maven打包下载下来的源码,这种方法也行,但是不够方便,为什么这么说? 首先需要安装maven吧?其次需要 ...
- elasticsearch中文分词器(ik)配置
elasticsearch默认的分词:http://localhost:9200/userinfo/_analyze?analyzer=standard&pretty=true&tex ...
- ElasticSearch7.3学习(十五)----中文分词器(IK Analyzer)及自定义词库
1. 中文分词器 1.1 默认分词器 先来看看ElasticSearch中默认的standard 分词器,对英文比较友好,但是对于中文来说就是按照字符拆分,不是那么友好. GET /_analyze ...
- Solr4.10与tomcat整合并安装中文分词器
1.solr Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器.Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置.可扩展,并对索引. ...
- 搜索引擎ElasticSearch系列(五): ElasticSearch2.4.4 IK中文分词器插件安装
一:IK分词器简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源 ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- Elasticsearch(10) --- 内置分词器、中文分词器
Elasticsearch(10) --- 内置分词器.中文分词器 这篇博客主要讲:分词器概念.ES内置分词器.ES中文分词器. 一.分词器概念 1.Analysis 和 Analyzer Analy ...
随机推荐
- 【Java】计算机软件、博客的重要性、编程语言介绍和发展史
之前学得不踏实,重新复习一遍,打扎实基础中. 记录 Java核心技术-宋红康_2019版 & Java零基础学习-秦疆 文章目录 软件开发介绍 软件开发 什么是计算机? 硬件及冯诺依曼结构 计 ...
- ctfhub技能树—密码口令—默认口令
打开靶机 查看页面内容 根据题目提示,去搜索北京亿中邮信息技术有限公司邮件网关的默认口令 尝试登录 成功拿到flag
- 【开源】我和 JAP(JA Plus) 的故事
JA Plus 故事 程序员的故事如此简单之绕不过去的开源情结 我们准备做一件伟大的事,也可以说是一件真真正正普惠的事. 絮 是的,你没有看错,就是"絮"而非"序&quo ...
- python异步回调顺序?是否加锁?
话不多说,直接上代码: import time from functools import partial from concurrent.futures.process import Process ...
- mybatis中传集合时 报异常 invalid comparison: java.util.Arrays$ArrayList and java.lang.String
犯了一个低级的错误,在传集合类型的参数时,把他当成字符串处理了,导致报类型转换的错误 把 and nsrsbh!=' ' 删掉就行了
- win32 修改Edit控件文本颜色与背景色
#define WM_CTLCOLORMSGBOX 0x0132 #define WM_CTLCOLOREDIT 0x0133 //编辑控件Edit #define WM_CTLCOLORLISTBO ...
- 使用Logback日志
使用Logback日志 spring boot内部使用Logback作为日志实现的框架. Logback和log4j非常相似,如果你对log4j很熟悉,那对logback很快就会得心应手. logba ...
- std::thread线程库详解(3)
目录 目录 前言 lock_guard scoped_lock (C++17) unique_lock shared_lock 总结 ref 前言 前两篇的博文分别介绍了标准库里面的线程和锁,这一次的 ...
- ElasticSearch-IK分词器和集成使用
1.查询存在问题分析 在进行字符串查询时,我们发现去搜索"搜索服务器"和"钢索"都可以搜索到数据: 而在进行词条查询时,我们搜索"搜索"却没 ...
- 01. struts2介绍
struts2优点 与Servlet API 耦合性低.无侵入式设计 提供了拦截器,利用拦截器可以进行AOP编程,实现如权限拦截等功能 支持多种表现层技术,如:JSP.freeMarker.veloc ...