ES中文分词器安装以及自定义配置
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了。
ik分词器的下载和安装,测试
第一: 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases ,这里你需要根据你的Es的版本来下载对应版本的IK,这里我使用的是6.8.10的ES,所以就下载ik-6.8.10.zip的文件。
解压-->将文件复制到 es的安装目录/plugin/ik下面即可,完成之后效果如下:
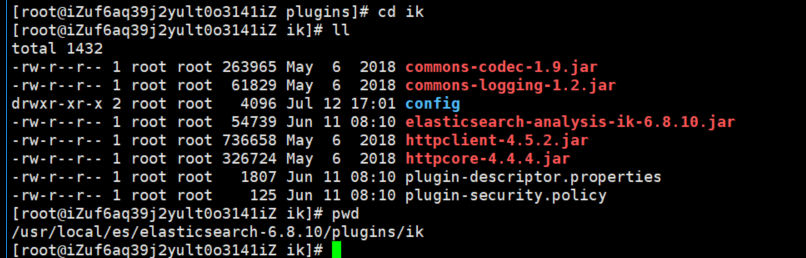
到这里已经完成了,不需要去elasticSearch的 elasticsearch.yml 文件去配置。
重启ElasticSearch
测试效果
未使用ik分词器的效果
### 原生分词
GET /_analyze
{
"analyzer": "standard",
"text": "中华人民共和国"
}
效果:
{
"tokens" : [
{
"token" : "中",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "华",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "人",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "民",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "共",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "和",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 6
}
]
}
ik_smart分词效果:
# ik_smart:会做最粗粒度的拆分
GET /_analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
效果:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
}
]
}
ik_max_word会将文本做最细粒度的拆分
## ik_max_word会将文本做最细粒度的拆分
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国"
}
效果:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 8
}
]
}
对于上面两个分词效果的解释:
- 如果未安装ik分词器,那么,你如果写 "analyzer": "ik_max_word",那么程序就会报错,因为你没有安装ik分词器
- 如果你安装了ik分词器之后,你不指定分词器,不加上 "analyzer": "ik_max_word" 这句话,那么其分词效果跟你没有安装ik分词器是一致的,也是分词成每个汉字。
自定义扩展词
一些热词,自定义的词,ik是不会收录的,这时候我们需要自定义扩展。
比如:王者荣耀。
分词的效果如下,显然是不满足我们需求的,这时候就需要自定义.
GET /_analyze
{
"analyzer": "ik_smart",
"text": "王者荣耀"
}
效果:
{
"tokens" : [
{
"token" : "王者",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "荣耀",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
}
]
}
在config目录下新建ext.dic文件
王者荣耀
进入 es安装目录/plugins/ik/config
编辑IKAnalyzer.cfg.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
重启es,测试效果
{
"tokens" : [
{
"token" : "王者荣耀",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
}
]
}
ES中文分词器安装以及自定义配置的更多相关文章
- solr4.7中文分词器(ik-analyzer)配置
solr本身对中文分词的处理不是太好,所以中文应用很多时候都需要额外加一个中文分词器对中文进行分词处理,ik-analyzer就是其中一个不错的中文分词器. 一.版本信息 solr版本:4.7.0 需 ...
- elasticsearch ik中文分词器安装
特殊说明:灰色文字用来辅助理解的. 安装IK中文分词器 我在百度上搜索了下,大多介绍的都是用maven打包下载下来的源码,这种方法也行,但是不够方便,为什么这么说? 首先需要安装maven吧?其次需要 ...
- elasticsearch中文分词器(ik)配置
elasticsearch默认的分词:http://localhost:9200/userinfo/_analyze?analyzer=standard&pretty=true&tex ...
- ElasticSearch7.3学习(十五)----中文分词器(IK Analyzer)及自定义词库
1. 中文分词器 1.1 默认分词器 先来看看ElasticSearch中默认的standard 分词器,对英文比较友好,但是对于中文来说就是按照字符拆分,不是那么友好. GET /_analyze ...
- Solr4.10与tomcat整合并安装中文分词器
1.solr Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器.Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置.可扩展,并对索引. ...
- 搜索引擎ElasticSearch系列(五): ElasticSearch2.4.4 IK中文分词器插件安装
一:IK分词器简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源 ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- Elasticsearch(10) --- 内置分词器、中文分词器
Elasticsearch(10) --- 内置分词器.中文分词器 这篇博客主要讲:分词器概念.ES内置分词器.ES中文分词器. 一.分词器概念 1.Analysis 和 Analyzer Analy ...
随机推荐
- ctfhub技能树—彩蛋
彩蛋题建议大家首先自己动手去找一找 做 好 准 备 后 再 看 下 文 ! 1.首页 使用域名查询工具查询子域名 2.公众号 此题关注ctfhub公众号即可拿到,不过多赘述. 3. ...
- 【Azure 存储服务】Python模块(azure.cosmosdb.table)直接对表存储(Storage Account Table)做操作示例
什么是表存储 Azure 表存储是一项用于在云中存储结构化 NoSQL 数据的服务,通过无结构化的设计提供键/属性存储. 因为表存储无固定的数据结构要求,因此可以很容易地随着应用程序需求的发展使数据适 ...
- Table controls and tabstrip controls
本文转载自http://www.cnblogs.com/clsoho/archive/2010/01/21/1653268.html ONTROLS Syntax Forms Declaration ...
- InnoDB的主键选择与插入优化
索引的存放方式MyISAM和InnoDB存储引擎在MySQL中,不同存储引擎对索引的实现方式是不同的,总结下MyISAM和InnoDB两个存储引擎的索引实现方式.MyISAM引擎使用B+Tree作为索 ...
- .net code+vue 文件上传
后端技术 .net code 官方文档 https://docs.microsoft.com/zh-cn/aspnet/core/mvc/models/file-uploads?view=aspnet ...
- response返回特性
1. response 返回特性 r=requests.get("http://www.baidu.com")print(r.text) #打印返回正文print(r.status ...
- U盘UEFI+GPT模式安装CentOS7.X系统
1.制作CentOS7安装盘 还是老套路,开局先制作安装盘,UltraISO软碟通,上图 (1) 打开UltraISO软件,选择"文件"-> "打开" ...
- SpringBoot 报错: Circular view path [readingList] 解决办法
spring boot报错: Circular view path [readingList]: would dispatch back to the current handler URL [/re ...
- DevOps运动的缘起 将DevOps想象为一种编程语言里面的一个接口,而SRE类实现了这个接口
SRE vs DevOps:是敌是友? - DockOne.io http://www.dockone.io/article/5935 RE vs DevOps:是敌是友? [编者的话]网站可靠 ...
- Micro Frontends 微前端
Micro Frontends https://martinfowler.com/articles/micro-frontends.html Integration approaches Server ...