Spark内核-部署模式
| Master URL | Meaning |
|---|---|
| local | 在本地运行,只有一个工作进程,无并行计算能力。 |
| local[K] | 在本地运行,有K个工作进程,通常设置K为机器的CPU核心数量。 |
| local[*] | 在本地运行,工作进程数量等于机器的CPU核心数量。 |
| spark://HOST:PORT | 以Standalone模式运行,这是Spark自身提供的集群运行模式,默认端口号: 7077。详细文档见:Spark standalone cluster。 |
| mesos://HOST:PORT | 在Mesos集群上运行,Driver进程和Worker进程运行在Mesos集群上,部署模式必须使用固定值:--deploy-mode cluster。详细文档见:MesosClusterDispatcher. |
| yarn-client | 在Yarn集群上运行,Driver进程在本地,Executor进程在Yarn集群上,部署模式必须使用固定值:--deploy-mode client。Yarn集群地址必须在HADOOPCONFDIR or YARNCONFDIR变量里定义。 |
| yarn-cluster | 在Yarn集群上运行,Driver进程在Yarn集群上,Work进程也在Yarn集群上,部署模式必须使用固定值:--deploy-mode cluster。Yarn集群地址必须在HADOOPCONFDIR or YARNCONFDIR变量里定义。 |
用户在提交任务给Spark处理时,以下两个参数共同决定了Spark的运行方式。· –master MASTER_URL :决定了Spark任务提交给哪种集群处理。· –deploy-mode DEPLOY_MODE:决定了Driver的运行方式,可选值为Client或者Cluster。
Standalone 模式运行机制
Standalone集群有四个重要组成部分,分别是:
- Driver:是一个进程,我们编写的Spark应用程序就运行在Driver上,由Driver进程执行;2) Master(RM):是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责;3) Worker(NM):是一个进程,一个Worker运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。4) Executor:是一个进程,一个Worker上可以运行多个Executor,Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算,也就是执行我们对RDD定义的例如map、flatMap、reduce等算子操作。
Standalone Client 模式
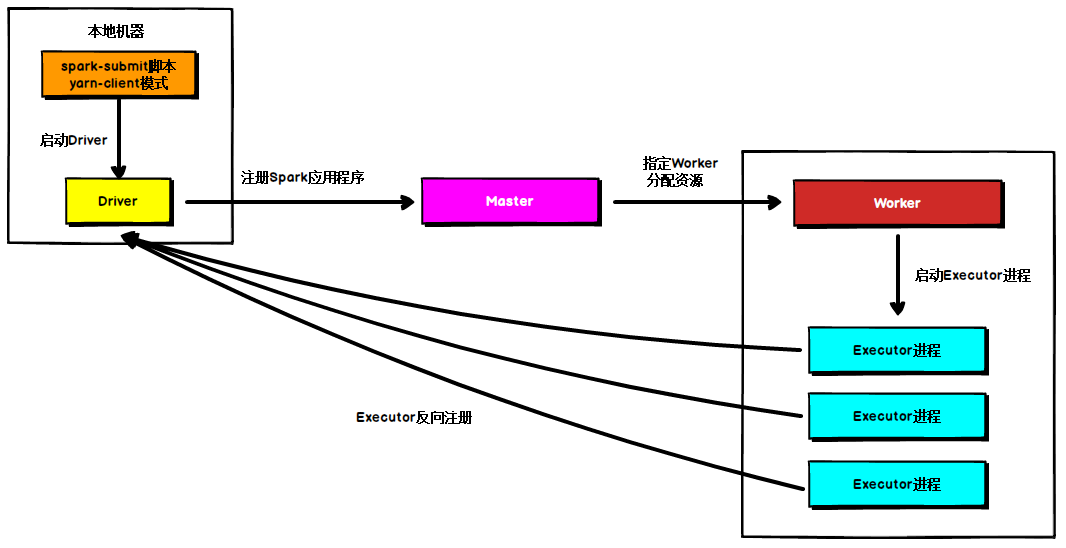
在Standalone Client模式下,Driver在任务提交的本地机器上运行,Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源至少可以启动一个Executor的所有Worker,然后在这些Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成后,Driver开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
Standalone Cluster模式
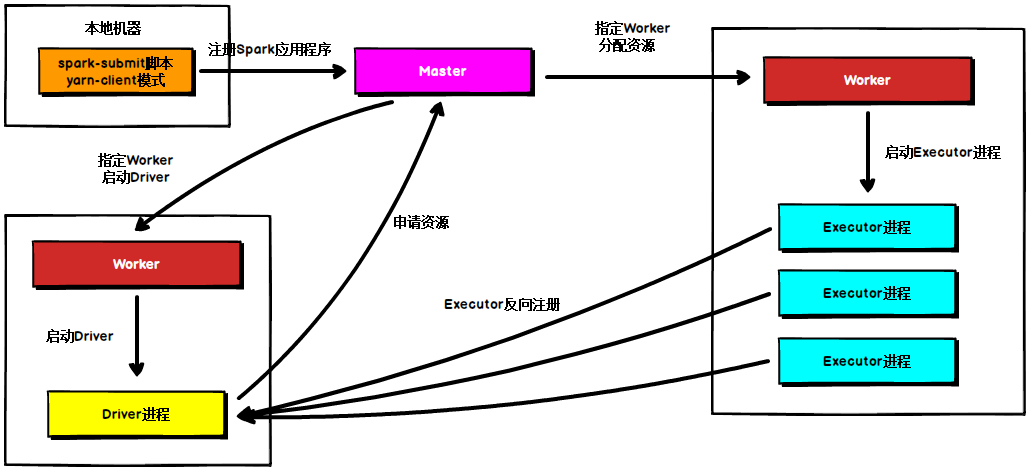
在Standalone Cluster模式下,任务提交后,Master会找到一个Worker启动Driver进程, Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源至少可以启动一个Executor的所有Worker,然后在这些Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成后,Driver开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。注意Standalone的两种模式下(client/Cluster),Master在接到Driver注册Spark应用程序的请求后,会获取其所管理的剩余资源能够启动一个Executor的所有Worker,然后在这些Worker之间分发Executor,此时的分发只考虑Worker上的资源是否足够使用,直到当前应用程序所需的所有Executor都分配完毕,Executor反向注册完毕后,Driver开始执行main程序。
Yarn 模式运行机制
Yarn Client 模式

在YARN Client模式下,Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存。
ResourceManager接到ApplicationMaster的资源申请后会分配container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
Yarn Cluster 模式
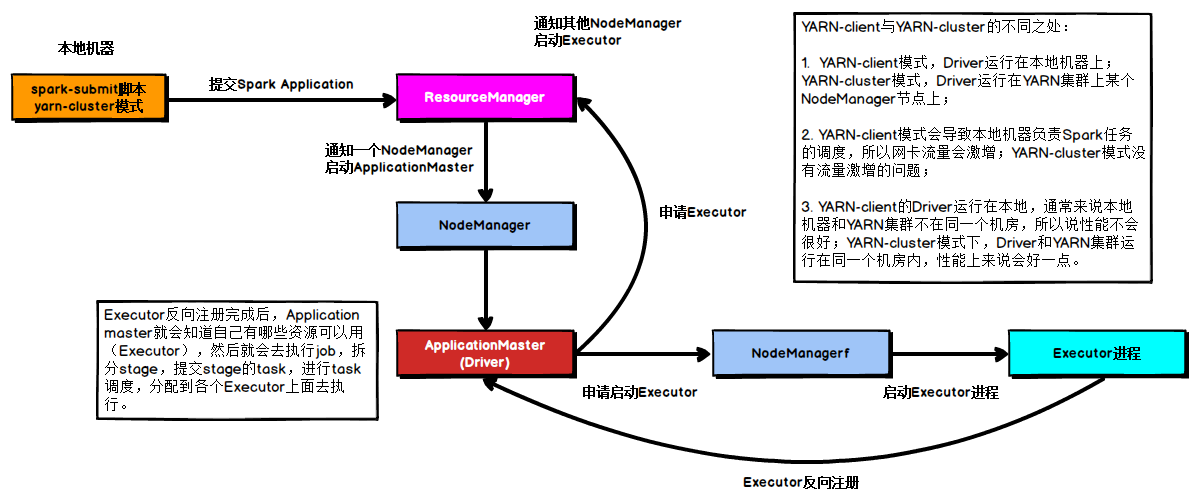
在YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配container,然后在合适的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
作者:十一喵先森
链接:https://juejin.im/post/5e1c414fe51d451cad4111d1
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我的解释:
Standalone Cluster模式
spark集群----一个公司.腾讯
master----老板
worker----部门
driver---项目经理
execotur---执行器---程序员
application---自己编写的程序---客户提要求
流程:
任务提交后,
Master(老板)会找到一个Worker(部门)启动Driver(项目)进程
把application(客户的需求)提交给driver(项目经理),
driver(项目经理)去spark(公司)集群中找到master(老板)要资源,需要多部门配合.
master(老板)会根据调度算法找到可用的多个worker(部门),
Driver(项目经理)在worker(部门)中启动executor(程序员)程序.
Driver(项目经理)开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor(程序员)上执行
Yarn Cluster 模式
Application---需求
ApplicationMaster(Driver)---项目经理
Executor---程序员
yarn---公司
ResourceManager---老板
NodeManager---部门
流程:
本地机器提交application(需求)到resourcemanager(老板),
resourcemanager(老板)在NodeManager(部门)上启动ApplicationManster(项目),就是driver.
ApplicationMaster(项目经理)向ResourceManager(老板)申请Executor(程序员)内存,
在合适的多个NodeManager(部门)上启动Executor(程序员)进程,
Driver(项目经理)开始执行main函数,
并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor(程序)上执行。
Spark内核-部署模式的更多相关文章
- 【待补充】Spark 集群模式 && Spark Job 部署模式
0. 说明 Spark 集群模式 && Spark Job 部署模式 1. Spark 集群模式 [ Local ] 使用一个 JVM 模拟 Spark 集群 [ Standalone ...
- Spark job 部署模式
Spark job 的部署有两种模式,Client && Cluster spark-submit .. --deploy-mode client | cluster [上传 Jar ...
- 【大数据】Spark内核解析
1. Spark 内核概述 Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spa ...
- Apache Spark技术实战之8:Standalone部署模式下的临时文件清理
未经本人同意严禁转载,徽沪一郎. 概要 在Standalone部署模式下,Spark运行过程中会创建哪些临时性目录及文件,这些临时目录和文件又是在什么时候被清理,本文将就这些问题做深入细致的解答. 从 ...
- Apache Spark技术实战之6 --Standalone部署模式下的临时文件清理
问题导读 1.在Standalone部署模式下,Spark运行过程中会创建哪些临时性目录及文件? 2.在Standalone部署模式下分为几种模式? 3.在client模式和cluster模式下有什么 ...
- Spark安装部署(local和standalone模式)
Spark运行的4中模式: Local Standalone Yarn Mesos 一.安装spark前期准备 1.安装java $ sudo tar -zxvf jdk-7u67-linux-x64 ...
- 【Spark】Spark的Standalone模式安装部署
Spark执行模式 Spark 有非常多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则执行在集群中,眼下能非常好的执行在 Yarn和 Mesos 中.当然 Spark 还有自带的 St ...
- spark运行模式之二:Spark的Standalone模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
- spark运行模式之一:Spark的local模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
随机推荐
- 厉害!这份阿里面试官 甩出的Spring源码笔记,GitHub上已经爆火
前言 时至今日,Spring 在 Java 生态系统与就业市场上,面试出镜率之高,投产规模之广,无出其右.随着技术的发展,Spring 从往日的 IoC 框架,已发展成 Cloud Native 基础 ...
- 深度分析:Java 静态方法/变量,非静态方法/变量的区别,今天一并帮你解决!
静态/非静态 方法/变量的写法 大家应该都明白静态方法/字段比普通方法/字段的写法要多一个static关键字,简单写下他们的写法吧,了解的可以直接略过 class Test{ // 静态变量 publ ...
- ABBYY FineReader 15高级转换功能详解
ABBYY FineReader 15(Windows系统)OCR文字识别软件拥有强大的OCR项目功能,能帮助用户检查识别区域.验证识别出的文本.预处理图像以提高 OCR精确性等等.其强大的OCR微调 ...
- 如何使用ABBYY FineReader 手动管理文档区域
在运用OCR编辑器时,ABBYY FineReader 15(Windows系统)OCR文字识别软件会对扫描仪或数码相机导入的图像进行识别和检测.在识别和检测之前,软件会自动对PDF文档中的文本.图片 ...
- 换系统之后为什么iMindMap会提示“许可证使用的次数过多”
iMindMap是一款十分受欢迎的思维导图软件,随着12版本的上线,iMindMap新增了很多新用户,最近小编发现有不少新用户在群里反映:"为什么购买iMindMap时说可以支持换机,但是在 ...
- guitar pro系列教程(九):Guitar Pro音谱“编辑”讲解
对广大音乐人来说,guitar pro不只是一款看谱软件,更是制谱辅助创作的好搭档 打开guitar pro创作软件的 主界面,你会看到"编辑"的字样,单击一下,会弹出下面的界面, ...
- zabbix的搭建及操作(4)实现邮件,钉钉,微信报警
实现邮件报警 网页版邮箱中开启 POP3/SMTP/IMAP 生成授权码并记录 Server端安装配置邮件服务器 1.Yum安装邮件服务器 yum -y install mailx dos2unix ...
- 关于UILabel标签控件的使用小节
前段时间一直想停下来,总结一下近期在开发中遇到的一些问题顺便分享一下解决问题的思路和方法,无奈人生就像蒲公英,看似自由却身不由己.太多的时间和精力被占用在新项目的开发和之前项目的维护中,总之一句话外包 ...
- mysql 数据文件
mysql8.0取消了frm文件 . ibd数据和索引
- synchronized底层揭秘
前言 上篇文章我们从硬件级别探索,对可见性和有序性的认识上升了一个高度,却迟迟没有介绍原子性的解决方案. 今天我们就来聊一聊原子性的解决方案,锁. 引入锁机制,除了可以保证原子性,同时也可以保证可见性 ...