python简单实现论文查重(软工第一次项目作业)
前言
| 软件工程 | https://edu.cnblogs.com/campus/gdgy/informationsecurity1812 |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/gdgy/informationsecurity1812/homework/11155 |
| 作业目标 | 代码实现、性能分析、单元测试、异常处理说明、记录PSP表格 |
本文涉及代码已上传个人GitHub
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:从命令行参数给出:论文原文的文件的绝对路径。
从命令行参数给出:抄袭版论文的文件的绝对路径。
从命令行参数给出:输出的答案文件的绝对路径。
我们提供一份样例,课堂上下发,上传到班级群,使用方法是:orig.txt是原文,其他orig_add.txt等均为抄袭版论文。注意:答案文件中输出的答案为浮点型,精确到小数点后两位
查询网上文章,总结出实现思路:
- 先将待处理的数据(中文文章)进行分词,得到一个存储若干个词汇的列表
- 接着计算并记录出列表中词汇对应出现的次数,将这些次数列出来即可认为我们得到了一个向量
- 将两个数据对应的向量代入夹角余弦定理
- 计算的值意义为两向量的偏移度,这里也即对应两个数据的相似度
除了余弦定理求相似度,还可以使用欧氏距离、海明距离等
所用接口
jieba.cut
用于对中文句子进行分词,功能非常强大,详细功能见GitHub
该方法提供多种分词模式供选择,这里只需用到默认最简单的“精确模式”。
代码:
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
运行结果:
他, 来到, 了, 网易, 杭研, 大厦
re.match
由于对比对象为中文或英文单词,因此应该对读取到的文件数据中存在的换行符\n、标点符号过滤掉,这里选择用正则表达式来匹配符合的数据。
代码:
def filter(str):
str = jieba.lcut(str)
result = []
for tags in str:
if (re.match(u"[a-zA-Z0-9\u4e00-\u9fa5]", tags)):
result.append(tags)
else:
pass
return result
这里正则表达式为u"[a-zA-Z0-9\u4e00-\u9fa5]",也即对jieba.cut分词之后的列表中的值,只保留英文a-zA-z、数字0-9和中文\u4e00-\u9fa5的结果。
gensim.dictionary.doc2bow
Doc2Bow是gensim中封装的一个方法,主要用于实现Bow模型。
Bag-of-words model (BoW model) 最早出现在自然语言处理(Natural Language Processing)和信息检索(Information Retrieval)领域.。该模型忽略掉文本的语法和语序等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的。
例如:
text1='John likes to watch movies. Mary likes too.'
text2='John also likes to watch football games.'
基于上述两个文档中出现的单词,构建如下一个词典 (dictionary):
{"John": 1, "likes": 2,"to": 3, "watch": 4, "movies": 5,"also": 6, "football": 7, "games": 8,"Mary": 9, "too": 10}
上面的词典中包含10个单词, 每个单词有唯一的索引, 那么每个文本我们可以使用一个10维的向量来表示。如下:
[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
[1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
该向量与原来文本中单词出现的顺序没有关系,而是词典中每个单词在文本中出现的频率。
代码:
def convert_corpus(text1,text2):
texts=[text1,text2]
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
return corpus
gensim.similarities.Similarity
该方法可以用计算余弦相似度,但具体的实现方式官网似乎并未说清楚,这是我查找大量文章得到的一种实现方式:
def calc_similarity(text1,text2):
corpus=convert_corpus(text1,text2)
similarity = gensim.similarities.Similarity('-Similarity-index', corpus, num_features=len(dictionary))
test_corpus_1 = dictionary.doc2bow(text1)
cosine_sim = similarity[test_corpus_1][1]
return cosine_sim
当然也可以根据余弦公式实现计算余弦相似度:
from math import sqrt
def similarity_with_2_sents(vec1, vec2):
inner_product = 0
square_length_vec1 = 0
square_length_vec2 = 0
for tup1, tup2 in zip(vec1, vec2):
inner_product += tup1[1]*tup2[1]
square_length_vec1 += tup1[1]**2
square_length_vec2 += tup2[1]**2
return (inner_product/sqrt(square_length_vec1*square_length_vec2))
cosine_sim = similarity_with_2_sents(vec1, vec2)
print('两个句子的余弦相似度为: %.4f。'%cosine_sim)
代码实现
将上述方法汇总应用,得到代码:
import jieba
import gensim
import re
#获取指定路径的文件内容
def get_file_contents(path):
str = ''
f = open(path, 'r', encoding='UTF-8')
line = f.readline()
while line:
str = str + line
line = f.readline()
f.close()
return str
#将读取到的文件内容先进行jieba分词,然后再把标点符号、转义符号等特殊符号过滤掉
def filter(str):
str = jieba.lcut(str)
result = []
for tags in str:
if (re.match(u"[a-zA-Z0-9\u4e00-\u9fa5]", tags)):
result.append(tags)
else:
pass
return result
#传入过滤之后的数据,通过调用gensim.similarities.Similarity计算余弦相似度
def calc_similarity(text1,text2):
texts=[text1,text2]
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
similarity = gensim.similarities.Similarity('-Similarity-index', corpus, num_features=len(dictionary))
test_corpus_1 = dictionary.doc2bow(text1)
cosine_sim = similarity[test_corpus_1][1]
return cosine_sim
if __name__ == '__main__':
path1 = "E:\pythonProject1\test\orig_0.8_dis_10.txt" #论文原文的文件的绝对路径(作业要求)
path2 = "E:\pythonProject1\test\orig_0.8_dis_15.txt" #抄袭版论文的文件的绝对路径
save_path = "E:\pythonProject1\save.txt" #输出结果绝对路径
str1 = get_file_contents(path1)
str2 = get_file_contents(path2)
text1 = filter(str1)
text2 = filter(str2)
similarity = calc_similarity(text1, text2)
print("文章相似度: %.4f"%similarity)
#将相似度结果写入指定文件
f = open(save_path, 'w', encoding="utf-8")
f.write("文章相似度: %.4f"%similarity)
f.close()
可以看出两篇文章相似度很大:


运行结果:
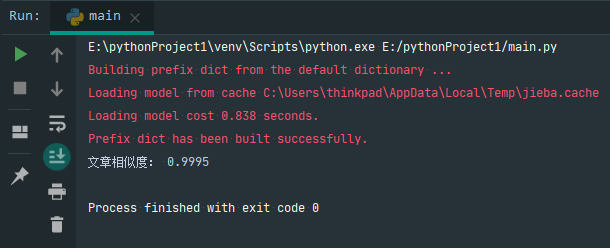
更改路径,
path1 = "E:\pythonProject1\test\orig.txt" ##论文原文的文件的绝对路径
path2 = "E:\pythonProject1\test\orig_0.8_dis_15.txt" #抄袭版论文的文件的绝对路径
可以看出两篇文章相似度较小:
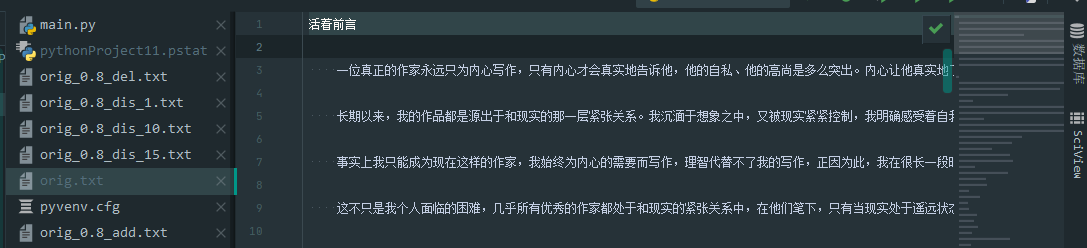
运行结果:
综上,该程序基本符合判断相似度的要求
性能分析
时间耗费
利用pycharm的插件可以得到耗费时间的几个主要函数排名:
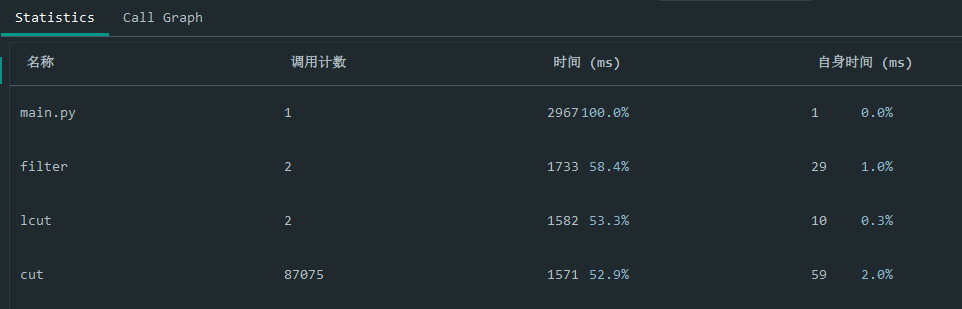
关注到filter函数:由于cut和lcut暂时找不到可提到的其他方法(jieba库已经算很强大了),暂时没办法进行改进,因此考虑对正则表达式匹配改进。
这里是先用lcut处理后再进行匹配过滤,这样做显得过于臃肿,可以考虑先匹配过滤之后再用lcut来处理
改进代码:
def filter(string):
pattern = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]")
string = pattern.sub("", string)
result = jieba.lcut(string)
return result
再做一次运行时间统计:
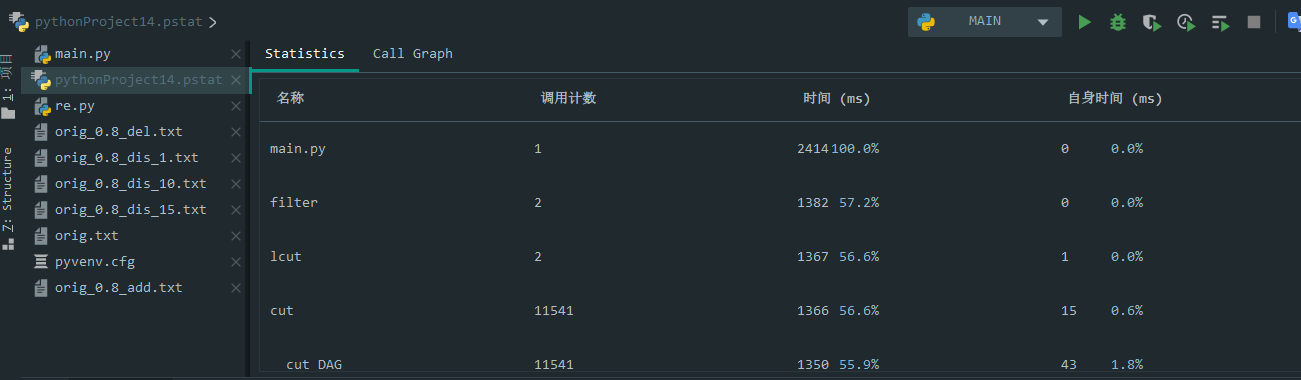
可以看到总耗时快了0.5s,提升了时间效率
代码覆盖率
代码覆盖率100%,满足要求:
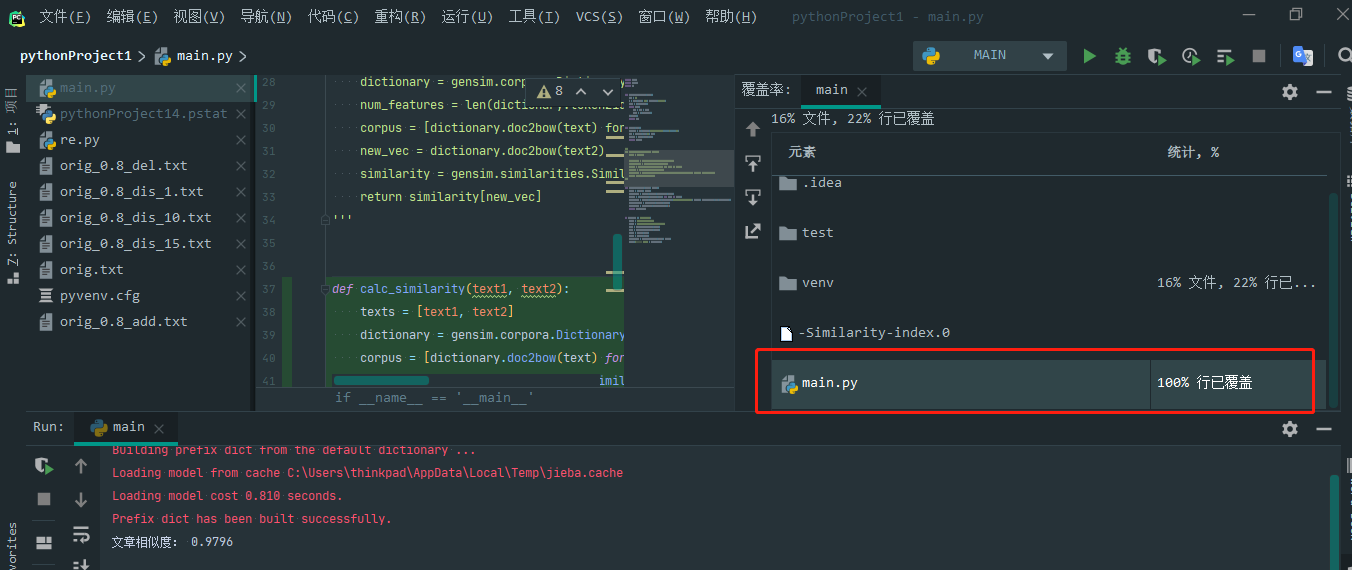
单元测试
这里需要用到python的unittest单元测试框架,详见官网介绍
为了方便进行单元测试,源码的main()应该修改一下:
import jieba
import gensim
import re
#获取指定路径的文件内容
def get_file_contents(path):
string = ''
f = open(path, 'r', encoding='UTF-8')
line = f.readline()
while line:
string = string + line
line = f.readline()
f.close()
return string
#将读取到的文件内容先把标点符号、转义符号等特殊符号过滤掉,然后再进行结巴分词
def filter(string):
pattern = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]")
string = pattern.sub("", string)
result = jieba.lcut(string)
return result
#传入过滤之后的数据,通过调用gensim.similarities.Similarity计算余弦相似度
def calc_similarity(text1, text2):
texts = [text1, text2]
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
similarity = gensim.similarities.Similarity('-Similarity-index', corpus, num_features=len(dictionary))
test_corpus_1 = dictionary.doc2bow(text1)
cosine_sim = similarity[test_corpus_1][1]
return cosine_sim
def main_test():
path1 = input("输入论文原文的文件的绝对路径:")
path2 = input("输入抄袭版论文的文件的绝对路径:")
str1 = get_file_contents(path1)
str2 = get_file_contents(path2)
text1 = filter(str1)
text2 = filter(str2)
similarity = calc_similarity(text1, text2) #生成的similarity变量类型为<class 'numpy.float32'>
result=round(similarity.item(),2) #借助similarity.item()转化为<class 'float'>,然后再取小数点后两位
return result
if __name__ == '__main__':
main_test()
为了使预期值更好确定,这里考虑只取返回的相似度值的前两位,借助round(float,2)即可处理,由于生成的similarity类型为<class 'numpy.float32'>,因此应当先转化为<class 'float'>,查找对应解决方法:通过xxx.item()即可转化。
再新建单元测试文件unit_test.py:
import unittest
from main import main_test
class MyTestCase(unittest.TestCase):
def test_something(self):
self.assertEqual(main_test(),0.99) #首先假设预测的是前面第一组运行的测试数据
if __name__ == '__main__':
unittest.main()
可以发现预测值为0.99正确:
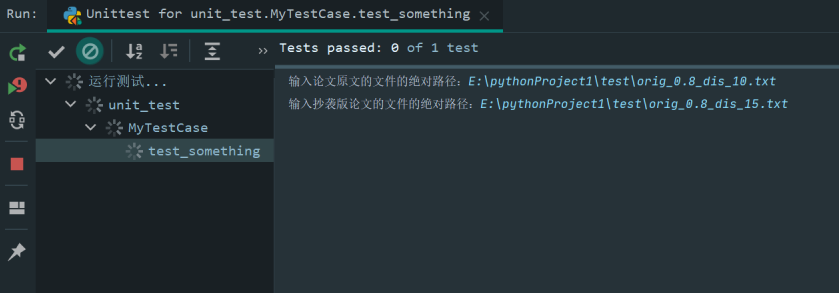
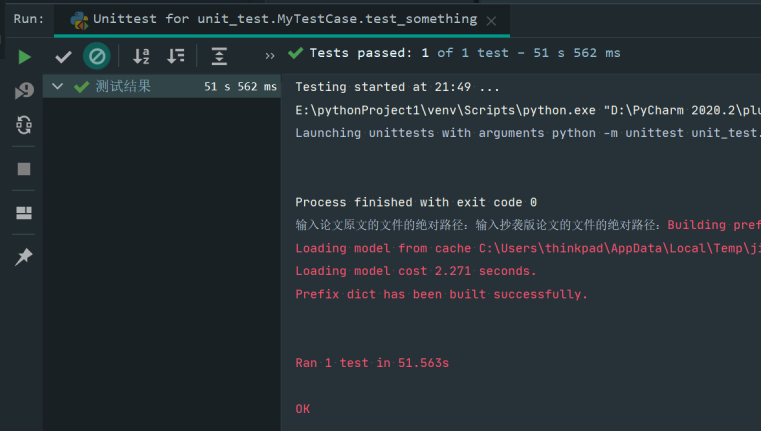
相似度仍然预测为0.99,但路径更改为之前测试的第二组数据:
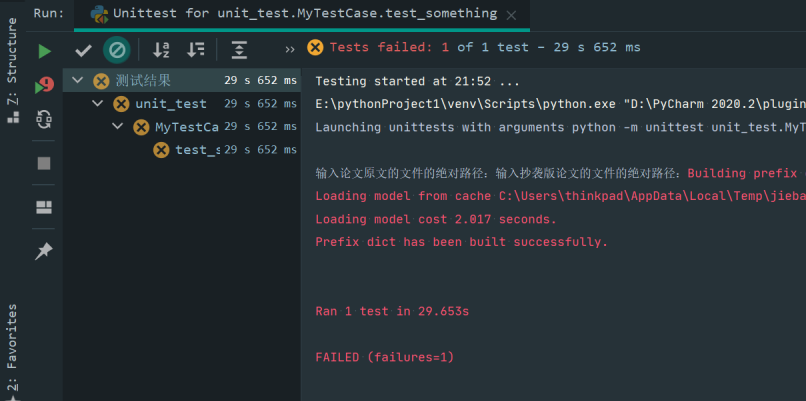
可以发现预测失败。
异常处理说明
在读取指定文件路径时,如果文件路径不存在,程序将会出现异常,因此可以在读取指定文件内容之前先判断文件是否存在,若不存在则做出响应并且结束程序。
这里引入os.path.exists()方法用于检验文件是否存在:
def main_test():
path1 = input("输入论文原文的文件的绝对路径:")
path2 = input("输入抄袭版论文的文件的绝对路径:")
if not os.path.exists(path1) :
print("论文原文文件不存在!")
exit()
if not os.path.exists(path2):
print("抄袭版论文文件不存在!")
exit()
······
PSP表格记录
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 150 |
| · Estimate | · 估计这个任务需要多少时间 | 120 | 150 |
| Development | 开发 | 480 | 300 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 100 |
| · Design Spec | · 生成设计文档 | 30 | 10 |
| · Design Review | · 设计复审 | 30 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 5 |
| · Design | · 具体设计 | 10 | 5 |
| · Coding | · 具体编码 | 120 | 120 |
| · Code Review | · 代码复审 | 20 | 5 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 20 |
| Reporting | 报告 | 30 | 20 |
| · Test Repor | · 测试报告 | 20 | 10 |
| · Size Measurement | · 计算工作量 | 5 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 5 | 5 |
| Total | 总计 | 1150 | 915 |
参考文章
https://titanwolf.org/Network/Articles/Article?AID=26627f5e-1ce9-40cb-a091-b771ae91d69d
http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
https://blog.csdn.net/qq_40938678/article/details/105354002
python简单实现论文查重(软工第一次项目作业)的更多相关文章
- 2020BUAA软工结伴项目作业
2020BUAA软工结伴项目作业 17373010 杜博玮 项目 内容 这个作业属于哪个课程 2020春季计算机学院软件工程(罗杰 任健) 这个作业的要求在哪里 结伴项目作业 我在这个课程的目标是 学 ...
- 2020BUAA软工个人项目作业
2020BUAA软工个人项目作业 17373010 杜博玮 项目 内容 这个作业属于哪个课程 2020春季计算机学院软件工程(罗杰 任健) 这个作业的要求在哪里 个人项目作业 我在这个课程的目标是 学 ...
- [BUAA软工]第一次结对作业
[BUAA软工]结对作业 本次作业所属课程: 2019BUAA软件工程 本次作业要求: 结对项目 我在本课程的目标: 熟悉结对合作,为团队合作打下基础 本次作业的帮助:理解一个c++ 项目的开发历程 ...
- BUAA软工-结对项目作业
结对项目作业 项目 内容 这个作业属于哪个课程 2020春季计算机学院软件工程(罗杰 任健) 这个作业的要求在哪里 结对项目作业 我在这个课程的目标是 通过这门课锻炼软件开发能力和经验,强化与他人合作 ...
- 【BUAA 软工个人项目作业】玩转平面几何
BUAA 软件工程个人项目作业 项目 内容 课程:2020春季软件工程课程博客作业(罗杰,任健) 博客园班级链接 作业:BUAA软件工程个人项目作业 作业要求 课程目标 学习大规模软件开发的技巧与方法 ...
- BUAA 软工 结对项目作业
1.相关信息 Q A 这个作业属于哪个课程 2020春季计算机学院软件工程(罗杰 任健) 这个作业的要求在哪里 结对项目作业 我在这个课程的目标是 系统地学习软件工程开发知识,掌握相关流程和技术,提升 ...
- [2019BUAA软工]第一次团队作业
Team V1 团队启动 BUAA Team V1 于2019年3月正式成立,将开始为期四个月的合作. 队员介绍 Name Summary Sefie wxmwy V1-bug制造公司资深工程师精 ...
- 论文 查重 知网 万方 paperpass
相信各个即将毕业的学生或在岗需要评职称.发论文的职场人士,论文检测都是必不可少的一道程序.面对市场上五花八门的检测软件,到底该如何选择?选择查重后到底该如何修改?现在就做一个知识的普及.其中对于中国的 ...
- PaperBye-一个可以自动改重的免费论文查重网站
推荐一个自动降重的免费论文查重软件,可自动降低论文重复率,一边修改,一边查重,免费查重网址:https://www.paperbye.com
随机推荐
- Robot Framework自动化测试框架核心指南-如何做好自动化测试平台框架的设计
自动化测试如果需要能高效快速的支撑软件项目的测试,项目的快速迭代以及上线,除了以上我们介绍的需要许多的Lib来支持以及需要高效的去编写自动化测试案例外,还需要一个好的自动化测试框架平台来支撑我们的自动 ...
- Template DB MySQL学习总结
Zabbix 5.0下如何应用Template DB MySQL来监控MySQL数据库呢?下面简单整理一下如何配置.应用Zabbix下自带的模板Template DB MySQL.其实非常简单. Te ...
- servlet web项目连接数据库报错
报错信息类似这样: Wed May 27 14:15:54 CST 2020 WARN: Establishing SSL connection without server's identity v ...
- leetcode刷题-57插入区间
题目 给出一个无重叠的 ,按照区间起始端点排序的区间列表. 在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间). 示例 1: 输入:intervals = ...
- Java自定义异常的用法
package day162020072701.day1601; /** * @author liuwenlong * @create 2020-07-27 09:25:44 */ @Suppress ...
- 学习 | css3实现进度条加载
进度条加载是页面加载时的一种交互效果,这样做的目的是提高用户体验. 进度条的的实现分为3大部分:1.页面布局,2.进度条动效,3.何时进度条增加. 文件目录 加载文件顺序 <link rel=& ...
- JVM运行时数据区--堆
一个进程对应一个jvm实例,一个运行时数据区,又包含多个线程,这些线程共享了方法区和堆,每个线程包含了程序计数器.本地方法栈和虚拟机栈. 核心概述 1.一个jvm实例只存在一个堆内存,堆也是java内 ...
- Hadoop演进与Hadoop生态
1.了解对比Hadoop不同版本的特性,可以用图表的形式呈现. (1)0.20.0~0.20.2: Hadoop的0.20分支非常稳定,虽然看起来有些落后,但是经过生产环境考验,是 Hadoop历史上 ...
- Java多线程--公平锁与非公平锁
上一篇文章介绍了AQS的基本原理,它其实就是一个并发包的基础组件,用来实现各种锁,各种同步组件的.它包含了state变量.加锁线程.等待队列等并发中的核心组件,现在我们来看一下多线程获取锁的顺序问题. ...
- Oracle添加键值对盲注
前言 遇到一种注入点,存在于POST参数中,却不能用sqlmap扫出: 分析 request参数格式: %24Q_value1=test1&orderCol=&order=+ASC+& ...