本地缓存高性能之王Caffeine
前言
随着互联网的高速发展,市面上也出现了越来越多的网站和app。我们判断一个软件是否好用,用户体验就是一个重要的衡量标准。比如说我们经常用的微信,打开一个页面要十几秒,发个语音要几分钟对方才能收到。相信这样的软件大家肯定是都不愿意用的。软件要做到用户体验好,响应速度快,缓存就是必不可少的一个神器。缓存又分进程内缓存和分布式缓存两种:分布式缓存如redis、memcached等,还有本地(进程内)缓存如ehcache、GuavaCache、Caffeine等。说起Guava Cache,很多人都不会陌生,它是Google Guava工具包中的一个非常方便易用的本地化缓存实现,基于LRU算法实现,支持多种缓存过期策略。由于Guava的大量使用,Guava Cache也得到了大量的应用。但是,Guava Cache的性能一定是最好的吗?也许,曾经它的性能是非常不错的。正所谓长江后浪推前浪,前浪被拍在沙滩上。我们就来介绍一个比Guava Cache性能更高的缓存框架:Caffeine。
Tips: Spring5(SpringBoot2)开始用Caffeine取代guava.详见官方信息SPR-13797
https://jira.spring.io/browse/SPR-13797
官方性能比较
以下测试都是基于jmh测试的,官网地址
测试为什么要基于jmh测试,可以参考知乎上R回答
在HotSpot VM上跑microbenchmark切记不要在main()里跑循环计时就完事。这是典型错误。重要的事情重复三遍:请用JMH,请用JMH,请用JMH。除非非常了解HotSpot的实现细节,在main里这样跑循环计时得到的结果其实对一般程序员来说根本没有任何意义,因为无法解释。
- 8个线程读,100%的读操作

- 6个线程读,2个线程写,也就是75%的读操作,25%的写操作。
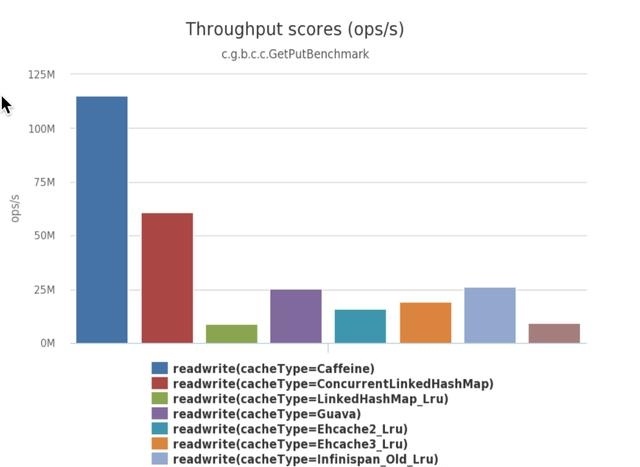
- 8个线程写,100%的写操作
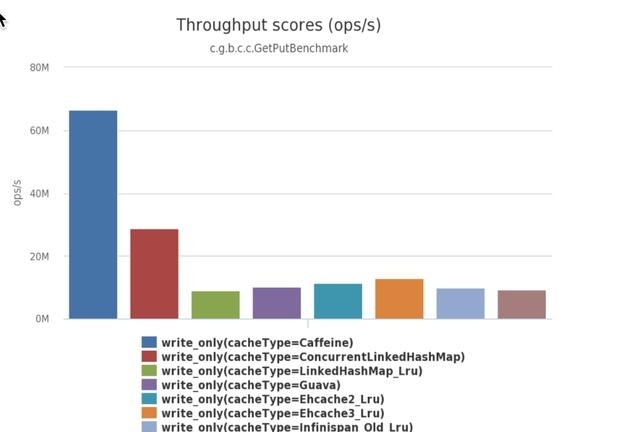
对比结论
可以从数据看出来Caffeine的性能都比Guava要好。然后Caffeine的API的操作功能和Guava是基本保持一致的,并且 Caffeine为了兼容之前是Guava的用户,做了一个Guava的Adapter给大家使用也是十分的贴心。
如何使用
- 在 pom.xml 中添加 caffeine 依赖
<!-- https://mvnrepository.com/artifact/com.github.ben-manes.caffeine/caffeine -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.8.2</version>
</dependency>
创建对象
Cache<String, Object> cache = Caffeine.newBuilder()
.initialCapacity(100)//初始大小
.maximumSize(200)//最大数量
.expireAfterWrite(3, TimeUnit.SECONDS)//过期时间
.build();
创建参数介绍
- initialCapacity: 初始的缓存空间大小
- maximumSize: 缓存的最大数量
- maximumWeight: 缓存的最大权重
- expireAfterAccess: 最后一次读或写操作后经过指定时间过期
- expireAfterWrite: 最后一次写操作后经过指定时间过期
- refreshAfterWrite: 创建缓存或者最近一次更新缓存后经过指定时间间隔,刷新缓存
- weakKeys: 打开key的弱引用
- weakValues:打开value的弱引用
- softValues:打开value的软引用
- recordStats:开发统计功能
注意:
expireAfterWrite和expireAfterAccess同时存在时,以expireAfterWrite为准。maximumSize和maximumWeight不可以同时使用。
添加数据
Caffeine 为我们提供了手动、同步和异步这几种填充策略。
下面我们来演示下手动填充策略吧,其他几种如果大家感兴趣的可以去官网了解下
Cache<String, String> cache = Caffeine.newBuilder()
.build();
cache.put("java金融", "java金融");
System.out.println(cache.getIfPresent("java金融"));
自动添加(自定义添加函数)
public static void main(String[] args) {
Cache<String, String> cache = Caffeine.newBuilder()
.build();
// 1.如果缓存中能查到,则直接返回
// 2.如果查不到,则从我们自定义的getValue方法获取数据,并加入到缓存中
String val = cache.get("java金融", k -> getValue(k));
System.out.println(val);
}
/**
* 缓存中找不到,则会进入这个方法。一般是从数据库获取内容
* @param k
* @return
*/
private static String getValue(String k) {
return k + ":value";
}
过期策略
Caffeine 为我们提供了三种过期策略
,分别是基于大小(size-based)、基于时间(time-based)、基于引用(reference-based)
基于大小(size-based)
LoadingCache<String, String> cache = Caffeine.newBuilder()
// 最大容量为1
.maximumSize(1)
.build(k->getValue(k));
cache.put("java金融1","java金融1");
cache.put("java金融2","java金融2");
cache.put("java金融3","java金融3");
cache.cleanUp();
System.out.println(cache.getIfPresent("java金融1"));
System.out.println(cache.getIfPresent("java金融2"));
System.out.println(cache.getIfPresent("java金融3"));
运行结果如下:淘汰了两个只剩下一个。
null
null
java金融3
基于时间(time-based)
Caffeine提供了三种定时驱逐策略:
expireAfterWrite(long, TimeUnit)
- 在最后一次写入缓存后开始计时,在指定的时间后过期。
LoadingCache<String, String> cache = Caffeine.newBuilder()
// 最大容量为1
.maximumSize(1)
.expireAfterWrite(3, TimeUnit.SECONDS)
.build(k->getValue(k));
cache.put("java金融","java金融");
Thread.sleep(1*1000);
System.out.println(cache.getIfPresent("java金融"));
Thread.sleep(1*1000);
System.out.println(cache.getIfPresent("java金融"));
Thread.sleep(1*1000);
System.out.println(cache.getIfPresent("java金融"));
运行结果第三秒的时候取值为空。
java金融
java金融
null
expireAfterAccess
- 在最后一次读或者写入后开始计时,在指定的时间后过期。假如一直有请求访问该key,那么这个缓存将一直不会过期。
LoadingCache<String, String> cache = Caffeine.newBuilder()
// 最大容量为1
.maximumSize(1)
.expireAfterAccess(3, TimeUnit.SECONDS)
.build(k->getValue(k));
cache.put("java金融","java金融");
Thread.sleep(1*1000);
System.out.println(cache.getIfPresent("java金融"));
Thread.sleep(1*1000);
System.out.println(cache.getIfPresent("java金融"));
Thread.sleep(1*1000);
System.out.println(cache.getIfPresent("java金融"));
Thread.sleep(3001);
System.out.println(cache.getIfPresent("java金融"));
运行结果:读和写都没有的情况下,3秒后才过期,然后就输出了null。
java金融
java金融
java金融
null
expireAfter(Expiry)
- 在expireAfter中需要自己实现Expiry接口,这个接口支持expireAfterCreate,expireAfterUpdate,以及expireAfterRead了之后多久过期。注意这个是和expireAfterAccess、expireAfterAccess是互斥的。这里和expireAfterAccess、expireAfterAccess不同的是,需要你告诉缓存框架,他应该在具体的某个时间过期,获取具体的过期时间。
LoadingCache<String, String> cache = Caffeine.newBuilder()
// 最大容量为1
.maximumSize(1)
.removalListener((key, value, cause) ->
System.out.println("key:" + key + ",value:" + value + ",删除原因:" + cause))
.expireAfter(new Expiry<String, String>() {
@Override
public long expireAfterCreate(@NonNull String key, @NonNull String value, long currentTime) {
return currentTime;
}
@Override
public long expireAfterUpdate(@NonNull String key, @NonNull String value, long currentTime, @NonNegative long currentDuration) {
return currentTime;
}
@Override
public long expireAfterRead(@NonNull String key, @NonNull String value, long currentTime, @NonNegative long currentDuration) {
return currentTime;
}
})
.build(k -> getValue(k));
删除
- 单个删除:Cache.invalidate(key)
- 批量删除:Cache.invalidateAll(keys)
- 删除所有缓存项:Cache.invalidateAll
总结
本文只是对Caffeine的一个简单使用的介绍,它还有很多不错的东西,比如缓存监控、事件监听、W-TinyLFU算法(高命中率、低内存占用)感兴趣的同学可以去官网查看。
结束
- 由于自己才疏学浅,难免会有纰漏,假如你发现了错误的地方,还望留言给我指出来,我会对其加以修正。
- 如果你觉得文章还不错,你的转发、分享、赞赏、点赞、留言就是对我最大的鼓励。
- 感谢您的阅读,十分欢迎并感谢您的关注。
参考
https://www.itcodemonkey.com/article/9498.html
https://juejin.im/post/5dede1f2518825121f699339
https://www.cnblogs.com/CrankZ/p/10889859.html
https://blog.csdn.net/hy245120020/article/details/78080686
https://github.com/ben-manes/caffeine
本地缓存高性能之王Caffeine的更多相关文章
- 本地缓存性能之王Caffeine
前言 随着互联网的高速发展,市面上也出现了越来越多的网站和app.我们判断一个软件是否好用,用户体验就是一个重要的衡量标准.比如说我们经常用的微信,打开一个页面要十几秒,发个语音要几分钟对方才能收到. ...
- SpringBoot 集成缓存性能之王 Caffeine
使用缓存的目的就是提高性能,今天码哥带大家实践运用 spring-boot-starter-cache 抽象的缓存组件去集成本地缓存性能之王 Caffeine. 大家需要注意的是:in-memeory ...
- Caffeine Cache-高性能Java本地缓存组件
前面刚说到Guava Cache,他的优点是封装了get,put操作:提供线程安全的缓存操作:提供过期策略:提供回收策略:缓存监控.当缓存的数据超过最大值时,使用LRU算法替换.这一篇我们将要谈到一个 ...
- Java高性能本地缓存框架Caffeine
一.序言 Caffeine是一个进程内部缓存框架,使用了Java 8最新的[StampedLock]乐观锁技术,极大提高缓存并发吞吐量,一个高性能的 Java 缓存库,被称为最快缓存. 二.缓存简介 ...
- springboot之本地缓存(guava与caffeine)
1. 场景描述 因项目要使用本地缓存,具体为啥不用redis等,就不讨论,记录下过程,希望能帮到需要的朋友. 2.解决方案 2.1 使用google的guava作为本地缓存 初步的想法是使用googl ...
- 本地缓存解决方案-Caffeine Cache
1.1 关于Caffeine Cache Google Guava Cache是一种非常优秀本地缓存解决方案,提供了基于容量,时间和引用的缓存回收方式.基于容量的方式内部实现采用LRU算法,基于引 ...
- spring boot: 用redis的消息订阅功能更新应用内的caffeine本地缓存(spring boot 2.3.2)
一,为什么要更新caffeine缓存? 1,caffeine缓存的优点和缺点 生产环境中,caffeine缓存是我们在应用中使用的本地缓存, 它的优势在于存在于应用内,访问速度最快,通常都不到1ms就 ...
- spring boot:使用spring cache+caffeine做进程内缓存(本地缓存)(spring boot 2.3.1)
一,为什么要使用caffeine做本地缓存? 1,spring boot默认集成的进程内缓存在1.x时代是guava cache 在2.x时代更新成了caffeine, 功能上差别不大,但后者在性能上 ...
- 本地缓存Caffeine
Caffeine 说起Guava Cache,很多人都不会陌生,它是Google Guava工具包中的一个非常方便易用的本地化缓存实现,基于LRU算法实现,支持多种缓存过期策略.由于Guava的大量使 ...
随机推荐
- C++调用C接口
目录 C++调用C代码 解决调用失败问题 思考:那C代码能够被C程序调用吗 C代码既能被C++调用又能被C调用 C++调用C代码 一个C语言文件p.c #include <stdio.h> ...
- Golang自学系列
为什么会有这个系列? 因为我要往架构方向靠拢啊. 关于架构,其实架构的书我看了<架构整洁之道>,也有<实现驱动领域设计>.但是我感觉明显还不够,所以我在极客时间买了一个架构相关 ...
- 老猿学5G:融合计费基于QoS流计费QBC的触发器Triggers
☞ ░ 前往老猿Python博文目录 ░ 一.引言 SMF中的功能体CTF在用户上网时达到一定条件就会向CHF上报流量,而CTF什么时候触发流量上报是由CTF中的触发器来控制的.在<老猿学5G: ...
- 老猿Python博客文章目录索引
本目录提供老猿Python所有相关博文的一级目录汇总,带星号的为收费专栏: 一.专栏列表 本部分为老猿所有专栏的列表,每个专栏都有该专栏置顶的博文目录: 专栏:Python基础教程目录 专栏:* 使用 ...
- PyQt(Python+Qt)学习随笔:PyQt帮助文档导入assistant后离线查阅
在按照<第15.6节 PyQt5安装与配置>完成PyQt5及PyQt5-tools的安装后,发现Qt Designer中的帮助不能使用,报错: 按照<PyQt学习随笔:Qt Desi ...
- 「Elasticsearch」SpringBoot快速集成ES
Elastic Search 的底层是开源库 Lucene.但是Lucene的使用门槛比较高,必须自己写代码去调用它的接口.而Elastic Search的出现正是为了解决了这个问题,它是 Lucen ...
- javascript是面向对象的,怎么体现javascript的继承关系?
一个简单的例子: var A =function(){ } A.prototype = { v : 5, tmp : 76, echo : function(){console.log(this.tm ...
- bootstrap table 控制checkbox在某些状态不显示
首先columns:[{field:'column',checkbox:true}];然后设置$("#tableName").bootstrapTable('hideColumn' ...
- 将ACCESS 的数据库中的表的文件 导出了EXCEL格式
将ACCESS 的数据库中的表的文件 导出了EXCEL格式 '''' '将ACCESS数据库中的某个表的信息 导出为EXCEL 文件格式 'srcfName ACCESS 数据库文件路径 'desfN ...
- 【题解】「UVA681」Convex Hull Finding
更改了一下程序的错误. Translation 找出凸包,然后逆时针输出每个点,测试数据中没有相邻的边是共线的.多测. Solution 首先推销一下作者的笔记 由此进入>>> ( ...