大话Spark(5)-三图详述Spark Standalone/Client/Cluster运行模式
之前在 大话Spark(2)里讲过Spark Yarn-Client的运行模式,有同学反馈与Cluster模式没有对比, 这里我重新整理了三张图分别看下Standalone,Yarn-Client 和 Yarn-Cluster的运行流程。
1、独立(Standalone)运行模式
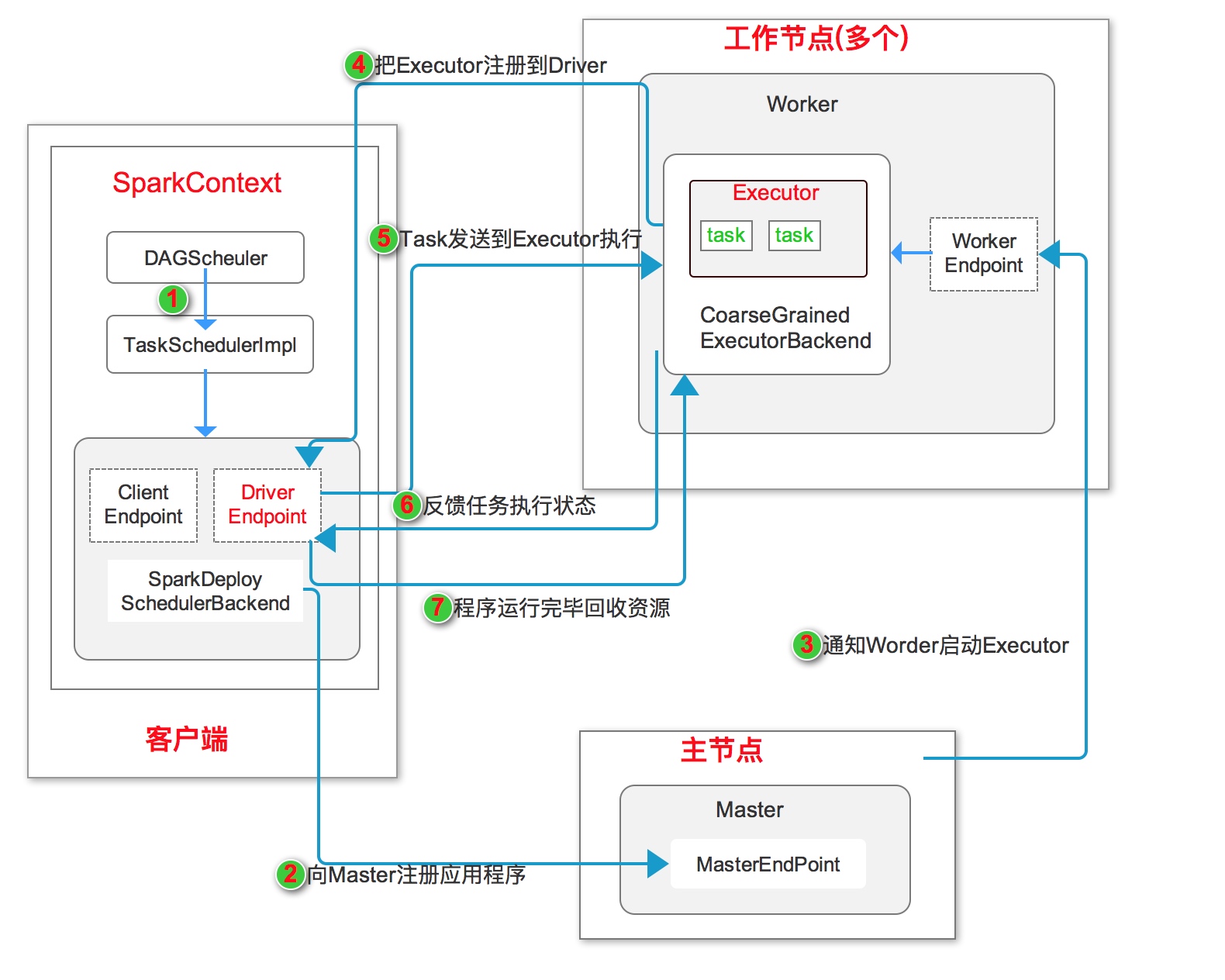 

独立运行模式是Spark自身实现的资源调度框架,由客户端、Master节点和多个Worker节点组成。其中SparkContext既可以运行在Master节点上,也可以运行在客户端。
Worker节点可以通过ExecutorRunner运行在当前节点上的CoarseGrainedExecutorBackend进程,每个Worker节点上存在一个或多个CoarseGrainedExecutorBackend进程,每个进程包含一个Executor对象。 该对象持有一个线程池,每个线程可以执行一个task。
如上图独立模式运行流程图所示:
- 启动应用程序,在SparkContext启动过程中,先初始化DAGScheduler 和 TaskSchedulerImpl两个调度器, 同时初始化SparkDeploySchedulerBackend,并在其内部启动DriverEndpoint 和 ClientEndpoint
- ClientEndpoint向Master注册应用程序。Master收到注册消息后把应用放到待运行应用列表,使用自己的
资源调度算法分配Worker资源给应用程序。 - 应用程序获得Worker时,Master会通知Worker中的WorkerEndpoint创建CoarseGrainedExecutorBackend进程,在该进程中创建执行容器Executor。
- Executor创建完毕后发送消息到Master 和 DriverEndpoint。在SparkContext创建成功后, 等待Driver端发过来的任务。
- SparkContext分配任务给CoarseGrainedExecutorBackend执行,在Executor上按照一定调度执行任务(这些任务就是自己写的代码)
- CoarseGrainedExecutorBackend在处理任务的过程中把任务状态发送给SparkContext,SparkContext根据任务不同的结果进行处理。如果任务集处理完毕后,则继续发送其他任务集。
- 应用程序运行完成后,SparkContext会进行资源回收。
补充
- SparkContext对任务的划分:每个Action操作都会触发一个job,job给到DAGScheduler,DAGScheduler把job划分成多个Stage(
Stage划分算法),每个Stage创建一个Taskset, TaskSet提交给TaskScheduler,把这些task分配到之前注册来的executor上。 - task的类型分为ShuffleMapTask 和 ResultTask, 只有最后一个task是ResultTask。每一个task针对rdd的一个partition并行执行, 一个stage的task会连续执行一个后续算子。
2、Yarn-Client运行模式
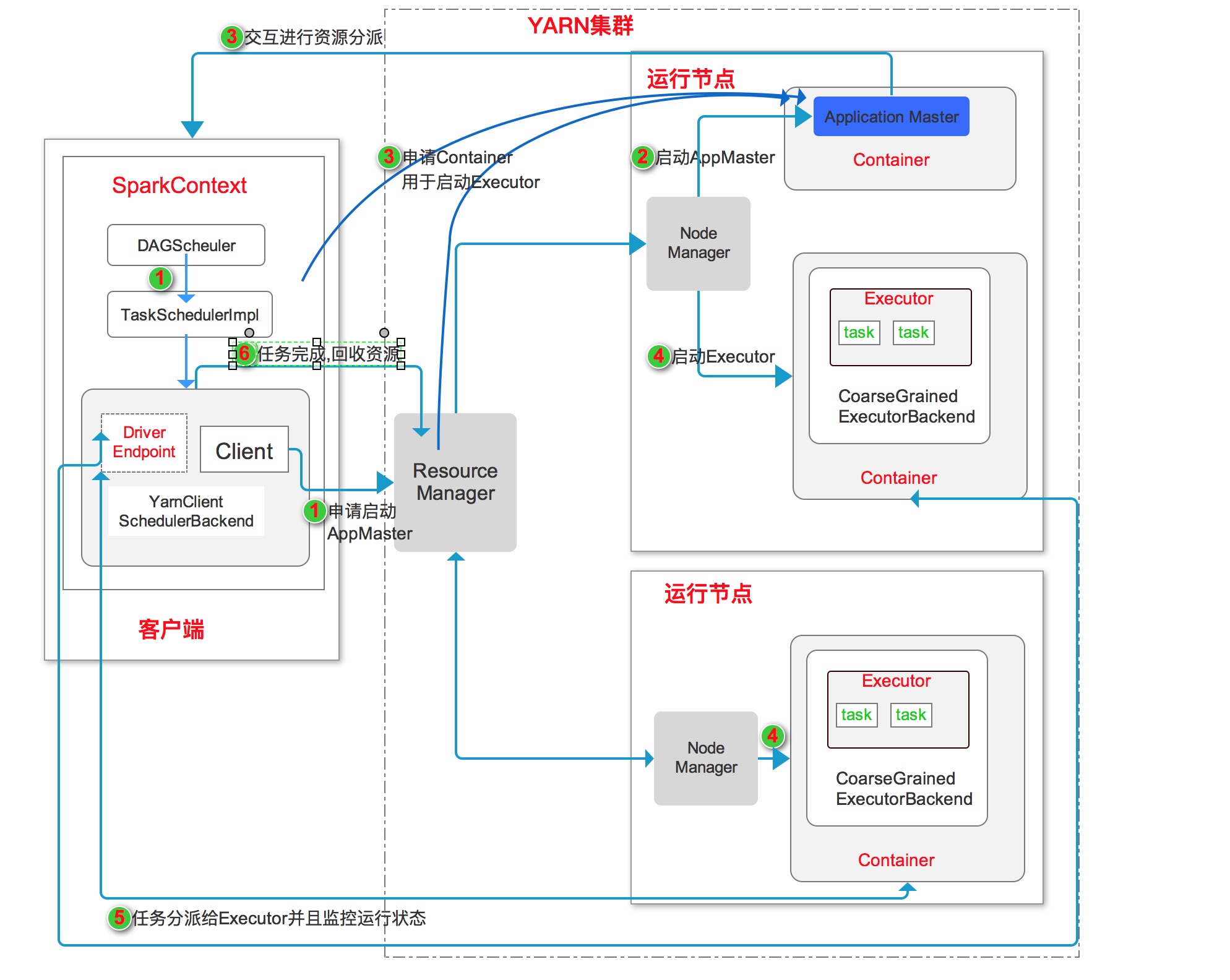 

Yarn-Client工作流程如上图所示:
- 启动应用程序,在SparkContext启动过程中, 初始化DAGScheduler调度器,使用反射方法初始化YarnScheduler 和 YarnClientSchedulerBackend。YarnClientSchedulerBackend内部启动DriverEndpoint 和 Client。Client向Yarn集群的ResourceManager申请启动Application Master。
- ResourceManager收到请求后,在集群中选一个NodeManger,为此应用申请一个Container, 并在其中启动Application Master。前面讲过,Client模式中的ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的派分。
- SparkContext启动完毕后,与Application Master通信,向Resource Manager注册, 根据任务信息申请Container资源。
- Application Master申请到资源后,与NodeManager通信,在Container中启动YarnClientSchedulerBackend,YarnClientSchedulerBackend向客户端中的SparkContext注册并申请taskset。
- SparkContext和运行中的任务保持通信,获取任务的状态和进度,随时掌握各个任务的运行状况,可以在任务失败时重启任务。
- 应用程序运行完成后,SparkContext向ResourceManager申请注销并关闭自己。
3、Yarn-Cluster运行模式
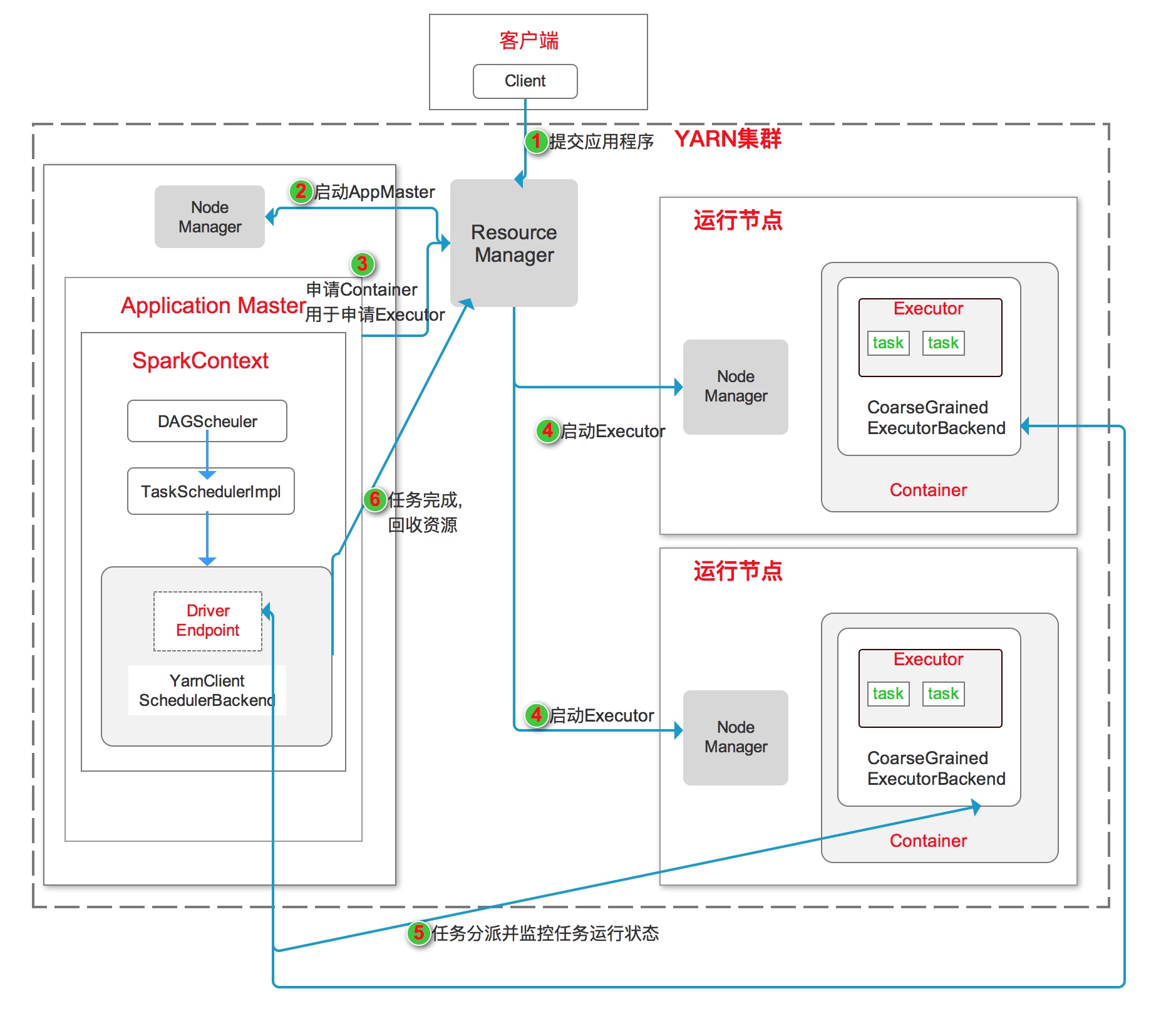 

Yarn-Cluster工作流程如上图所示:
- 客户端启动Client项YARN集群提交应用程序。
- ResourceManager收到请求后,再集群中选一个NodeManger,为此应用申请一个Container, 并在其中启动Application Master。在Application Master中进行SparkContext的初始化操作
- Application Master向ResourceManager注册,为各个任务申请资源,并监控任务的运行状态直到结束
- Application Master申请到资源后,与NodeManager通信,在Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend向客户端中的SparkContext注册并申请taskset。
- CoarseGrainedExecutorBackend运行任务并向Application Master汇报运行的状态和进度.
- 应用程序运行完成后,SparkContext向ResourceManager申请注销并关闭。
小结
Spark虽然有多种运行模式,但是其运行架构基本上由三部分组成,
- SparkContext
- ClusterManager(集群资源管理器)
- Executor(任务执行进程)
SparkContext用于负责与ClusterManager通信,进行资源的申请、任务的分配和监控等,负责作业执行的全生命周期管理。
ClusterManager提供了资源的分配和管理,不同模式下角色有所不同。Standalone模式下由Master提供,Yarn模式下由ResourceManager担任。
原文链接:
大话Spark(5)-三图详述Spark Standalone/Client/Cluster运行模式
大话Spark(5)-三图详述Spark Standalone/Client/Cluster运行模式的更多相关文章
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...
- Tomcat 的三种(bio,nio.apr) 高级 Connector 运行模式及apr配置
转: http://www.oschina.net/question/54100_16195omcat的运行模式有3种.修改他们的运行模式.3种模式的运行是否成功,可以看他的启动控制台,或者启动日志. ...
- Spark 学习(三) maven 编译spark 源码
spark 源码编译 scala 版本2.11.4 os:ubuntu 14.04 64位 memery 3G spark :1.1.0 下载源码后解压 1 准备环境,安装jdk和scala,具体参考 ...
- Spark思维导图之Spark SQL
- Spark思维导图之Spark Streaming
- Spark思维导图之Spark RDD
- Spark思维导图之Spark Core
- 【转】Tomcat 的三种(bio,nio.apr) 高级 Connector 运行模式
转载地址:http://www.oschina.net/question/54100_16195 tomcat的运行模式有3种.修改他们的运行模式.3种模式的运行是否成功,可以看他的启动控制台,或 ...
- Tomcat 的三种(bio,nio.apr) 高级 Connector 运行模式
tomcat的运行模式有3种.修改他们的运行模式.3种模式的运行是否成功,可以看他的启动控制台,或者启动日志.或者登录他们的默认页面http://localhost:8080/查看其中的服务器状态. ...
随机推荐
- Codeforces Round #655 (Div. 2) C. Omkar and Baseball
题目链接:https://codeforces.com/contest/1372/problem/C 题意 给出一个大小为 $n$ 的排列,每次操作可以选取一个连续子数组任意排列其中的元素,要求每个元 ...
- HttpServletResponse的学习
关于Response对象的一些方法和属性可以查看官方文档:https://javaee.github.io/javaee-spec/javadocs/ 比如里面定义了许多常量: 这些都是服务器向浏览器 ...
- CF1474-C. Array Destruction
CF1474-C. Array Destruction 题意: 题目给出一个长度为\(2n\)的正整数序列,现在问你是否存在一个\(x\)使得可以不断的进行如下操作,直到这个序列变为空: 从序列中找到 ...
- 国产网络损伤仪SandStorm -- 只需要上下拖拽能调整链路规则顺序
国产网络损伤仪SandStorm(弱网络测试)可以模拟出带宽限制.时延.时延抖动.丢包.乱序.重复报文.误码.拥塞等网络状况,在实验室条件下准确可靠地测试出网络应用在真实网络环境中的性能,以帮助应用程 ...
- c++ 输出文件夹(不包括子文件夹)中后缀文件
参考:_finddata_t结构体用法 - 麒麒川的博客 - CSDN博客 准备知识部分: MessageBox MessageBox function (winuser.h) | Microsoft ...
- JavaScript调试技巧之console.log()
与alert()函数类似,console.log()也可以接受变量并将其与别的字符串进行拼接: 代码如下: //Use variable var name = "Bob"; con ...
- Python_K-means算法
from sklearn import cluster [centroid, label, inertia] = cluster.k_means(data_to_be_classified, num_ ...
- favicon.ico All In One
favicon.ico All In One link rel="icon" type="image/x-icon" href="http://exa ...
- vue 自动注册全局组件
vue 自动注册全局组件 vue 注册全局组件的方式 const plugins = { install(Vue) { const requireComponent = require.context ...
- Linux bash shell All In One
Linux bash shell All In One Linux https://tinylab.gitbooks.io/shellbook/content/zh/chapters/01-chapt ...