词嵌入之Word2Vec
词嵌入要解决什么问题
在自然语言系统中,词被看作最为基本的单元,如何将词进行向量化表示是一个很基本的问题,词嵌入(word embedding)就是把词映射为低维实数域向量的技术。
下面先介绍几种词的离散表示技术,然后总结其缺点,最后介绍词的分布式表示及其代表技术(word2vec)。
词的离散表示
One-hot表示
根据语料构造一个大小为V的词汇表,并为每一个词分配一个id。
每个词都可以表示为一个V维向量,除了该词id对应的维度为1外,其余维度为0。
n-gram
与One-hot类似,只是统计单元由单个的词变成了连续的几个词,如2-gram是统计连续的两个单词构造词典。
离散表示的缺点
- 词向量维度随着词汇表大小的增长而增长带来的内存问题;
- 词向量过于稀疏,浪费内存,丢失信息;
- 无法衡量词和词之间的关系。
词的分布式表示
词的分布式表示的核心思想是:一个词是由这个词的周边词汇一起来构成精确的语义信息,因此可以用一个词附近的其他词来表示该词。词的分布式表示有以下几种代表方法:
共现矩阵
使用固定大小的滑窗统计词与词在窗口内的共现次数,然后将每个词表示为一个大小为V的矩阵,每个维度为该词与该维度对应词的共现次数。
共现矩阵方法仍然会存在内存问题以及稀疏性问题。
Word2Vec
谷歌2013年提出的Word2Vec是目前最常用的词嵌入模型之一,它实际上是一种浅层的神经网络模型,有两种网络结构,分别为CBoW和Skip-gram,目的都是得到词的稠密表示。需要指出的是,两种方法都会先采用滑动窗口的方式来对语料库进行窗口采集,所不同的是窗口内数据的使用方式。
CBoW
对于每一个窗口,CBOW通过中间词两边的上下文来预测中间词,从而学习词向量的表达,即根据context预测target word。CBOW结构如下图:
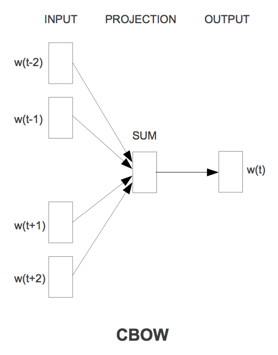
从数学上看,CBoW模型等价于一个词袋模型的向量乘以一个Embedding矩阵,从而得到一个连续的embedding向量。这也是CBoW模型名称的由来。
设CBoW网络结构中从输入层到隐藏层的矩阵为\(U\in \mathbb{R}^{d*M}\),从隐藏层到输出层的矩阵为\(V\in \mathbb{R}^{d*M}\),其中d为词向量维度,M为词汇表大小。则使用CBoW预测的目标词的概率为:
\[p(w_o|context)=\frac{e^{V_{w_o}^T\sum_{w_c\in context}U_{w_c}}}{\sum_{w\in vocab}e^{V_{w}^T\sum_{w_c\in context}U_{w_c}}}
\]其中,\(U_w\)和\(V_w\)分别是矩阵U和V对应词w的列,vocab为整个词汇表,\(w_o\)为中心词,context为上下文。
Skip-gram
与CBoW相反,Skip-gram使用中间词来预测上下文借此学习词向量,即根据target word来预测context。Skip-gram结构如下图:
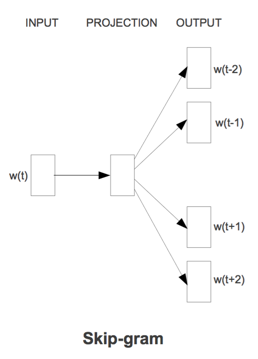
继承CBoW中的符号,使用Skip-gram预测的上下文词的概率为:
\[p(w_o|w_i)=\frac{e^{V_{w_o}^TU_{w_i}}}{\sum_{w\in vocab}e^{V_{w}^TU_{w_i}}}
\]其中,\(w_i\)为中心词,\(w_o\)为上下文中的词。
不管是CBoW还是Skip-gram,训练完成后,都是将矩阵U的每一列当作对应词的向量化表示。但我们发现,它们所要最大化的概率中都存在归一化的过程,归一化复杂度正比于词汇表大小,当词汇表很大的时候,这是极其耗时的。因此需要对这一步进行改良,具体改良办法有两种:
层次Softmax
层次Softmax的基本思想是将复杂的归一化概率分解为一系列条件概率乘积的形式,每一层条件概率对应一个二分类问题,可以通过一个简单的逻辑回归函数去拟合。这样,我们将对V个词的概率归一化问题,转化成了对\(\log_2V\)个词的概率拟合问题。
通过构造一棵二叉树可以很直观地理解这一过程,二叉树的每一个叶节点代表一个词,假设词w从根节点到叶节点的路径编码分别为\(e_1,e_2,..e_k\),对应的子树分别为\(T_1,T_2,...,Tk\),其中k为路径长度。以Skip-gram为例,其所要最大化的概率可以转化为:
\[p(w_o|w_i)=\prod_{j=1}^kp(e_j|T_j,V_{w_o}^TU_{w_i})
\]需要指出的是,层次Softmax进行最大化的时候,是对路径上的每一个逻辑回归分别优化的,即假定各逻辑回归间没有关联。
层次Softmax存在的问题是人为增强了词与词之间的耦合性。例如,一个word出现的条件概率的变化,会影响到其路径上所有非叶节点的概率变化,间接地对其他word出现的条件概率带来不同程度的影响。
通常使用霍夫曼编码来构造层次Softmax的二叉树,因为霍夫曼编码可以保证二叉树的平均路径最短,最大程度减小模型的复杂度。
负采样
不同于层次Softmax的修改最大化概率的计算方式,负采样直接修改了需要最大化的概率。
以Skip-gram为例,原始Skip-gram的目标函数为:
\[\arg \max _\theta\prod_{w\in Text}[\prod_{c\in C(w)}p(c|w;\theta)]
\]其中,C(w)表示词w的上下文单词集合,上述概率可以简写为:
\[\arg \max _\theta\prod_{(w,c)\in D}p(c|w;\theta)
\]其中,D为语料库中所有单词和上下文单词的集合。
为了避免计算\(p(c|w;\theta)\)过程中的归一化,可以换一个角度来思考问题。因为Word2Vec的最终目的是得到词向量矩阵U,因此训练任务并非仅仅只能是根据输入词预测输出词的概率,可以将任务修改为预测某一个词是否是输入词的上下文词的概率。这样,问题就由原来的多分类问题转变成了二分类问题,每个二分类问题可以通过一个简单的逻辑回归函数去拟合。目标函数变为:
\[\arg \max _\theta\prod_{(w,c)\in D}p(1|w,c;\theta)
\]由于只存在正样本,这样优化将使得所有词的词向量趋于一致,所以考虑负采样,即引入负样本,那么目标函数变为:
\[\arg \max _\theta\prod_{(w,c)\in D}p(1|w,c;\theta)\prod_{(w,c)\in D'}p(0|w,c;\theta)
\\
=\arg \max _\theta\sum_{(w,c)\in D}\log p(1|w,c;\theta)+\sum_{(w,c)\in D'}\log p(0|w,c;\theta)
\\
=\arg \max _\theta\sum_{(w,c)\in D}\log \sigma(V_c^TU_w)+\sum_{(w,c)\in D'}\log \sigma(-V_c^TU_w)
\]具体负采样的方法是依据词频进行带权采样,假设语料库中词w的频率为\(n_w\),则词w被负采样的概率为:
\[\frac{n_w^\alpha}{\sum_w n_w^\alpha}
\]其中,\(\alpha\)一般为小于1的正数起到放缩作用,使得频率小的词被采样的几率得到提升,频率大的词被采样的几率被降低,这样能增加低频词被采样到的机会,可以显著提高低频词的词向量的准确度。\(\alpha\)在原论文中的取值为0.75。有一个小问题是当负采样到输入词时会丢弃。
词嵌入之Word2Vec的更多相关文章
- [ DLPytorch ] word2vec&词嵌入
word2vec WordEmbedding 对词汇进行多维度的描述,形成一个密集的矩阵.这样每两个词之间的相似性可以通过进行内积的大小体现出来.越大说明距离越远,则越不相似. Analogies(类 ...
- 词向量表示:word2vec与词嵌入
在NLP任务中,训练数据一般是一句话(中文或英文),输入序列数据的每一步是一个字母.我们需要对数据进行的预处理是:先对这些字母使用独热编码再把它输入到RNN中,如字母a表示为(1, 0, 0, 0, ...
- DeepLearning.ai学习笔记(五)序列模型 -- week2 自然语言处理与词嵌入
一.词汇表征 首先回顾一下之前介绍的单词表示方法,即one hot表示法. 如下图示,"Man"这个单词可以用 \(O_{5391}\) 表示,其中O表示One_hot.其他单词同 ...
- 学习笔记CB009:人工神经网络模型、手写数字识别、多层卷积网络、词向量、word2vec
人工神经网络,借鉴生物神经网络工作原理数学模型. 由n个输入特征得出与输入特征几乎相同的n个结果,训练隐藏层得到意想不到信息.信息检索领域,模型训练合理排序模型,输入特征,文档质量.文档点击历史.文档 ...
- DLNg序列模型第二周NLP与词嵌入
1.使用词嵌入 给了一个命名实体识别的例子,如果两句分别是“orange farmer”和“apple farmer”,由于两种都是比较常见的,那么可以判断主语为人名. 但是如果是榴莲种植员可能就无法 ...
- NLP领域的ImageNet时代到来:词嵌入「已死」,语言模型当立
http://3g.163.com/all/article/DM995J240511AQHO.html 选自the Gradient 作者:Sebastian Ruder 机器之心编译 计算机视觉领域 ...
- ng-深度学习-课程笔记-16: 自然语言处理与词嵌入(Week2)
1 词汇表征(Word representation) 用one-hot表示单词的一个缺点就是它把每个词孤立起来,这使得算法对词语的相关性泛化不强. 可以使用词嵌入(word embedding)来解 ...
- 词嵌入向量WordEmbedding
词嵌入向量WordEmbedding的原理和生成方法 WordEmbedding 词嵌入向量(WordEmbedding)是NLP里面一个重要的概念,我们可以利用WordEmbedding将一个单 ...
- 词向量 词嵌入 word embedding
词嵌入 word embedding embedding 嵌入 embedding: 嵌入, 在数学上表示一个映射f:x->y, 是将x所在的空间映射到y所在空间上去,并且在x空间中每一个x有y ...
随机推荐
- css 06-CSS盒模型详解
06-CSS盒模型详解 #盒子模型 #前言 盒子模型,英文即box model.无论是div.span.还是a都是盒子. 但是,图片.表单元素一律看作是文本,它们并不是盒子.这个很好理解,比如说,一张 ...
- 图的建立以及应用(BFS,DFS,Prim)
关于带权无向图的一些操作 题目:根据图来建立它的邻接矩阵,通过邻接矩阵转化为邻接表,对邻接表进行深度优先访问和广度优先访问,最后用邻接矩阵生成它的最小生成树: 1.输入一个带权无向图(如下面图1和图2 ...
- matplotlib的学习2-基本用法
import matplotlib.pyplot as plt import numpy as np x = np.linspace(-1, 1, 50)#范围-1 到 1,个数是50 y = 2*x ...
- Nocalhost,让开发回归原始又简单
在刚刚结束的 2020 腾讯云 Techo Park 大会 DevOps 分论坛「开发乘云起,扶摇九万里」上,CODING CEO 张海龙发布了由 CODING 团队自主研发的全新产品 Nocalho ...
- 使用CentOS8来部署php7.4
使用CentOS8来部署php7.4 #安装REMI源 dnf install https://rpms.remirepo.net/enterprise/remi-release-8.rpm #查看P ...
- Autofac的基本使用---1、前言
Autofac的基本使用---目录 代码地址 https://github.com/catbiscuit/AutofacStudy 参考网上的大神,原博文地址 https://www.cnblogs. ...
- H3C路由器配置——动态路由OSPF协议
一.介绍 1.OSPF协议介绍 (1).OSPF(Open Shortest Path First,开放最短路径优先)路由协议是用于网际协议(IP)网络的链路状态路由协议.是一个被各厂商设备广泛支持的 ...
- npm 各种常用命令
全局删除 node-gyp npm -g uninstall node-gyp 再次安装依赖 npm install 更改包内容后重建 npm rebuild 清除缓存 npm cache clean ...
- [leetcode712]202. Happy Number判断快乐数字
题目很简单,就是用哈希表存,判断有没有重复 学到了:java中字符串的比较有两种: 1.==这种是比较引用,只用两个字符串变量指向同一个地址才相等 2..equals()这种是值的比较,只要两个字符串 ...
- 高效扩展工具让 VS Code 如虎添翼
Codelf 变量命名神器 Star:10688 https://github.com/unbug/codelf 新建项目,变量,类,方法,接口都需要命名,一个好的命名可以一眼看出这个地方的功能,Co ...