Attention & Transformer
Attention & Transformer
seq2seq; attention; self-attention; transformer;
1 注意力机制在NLP上的发展
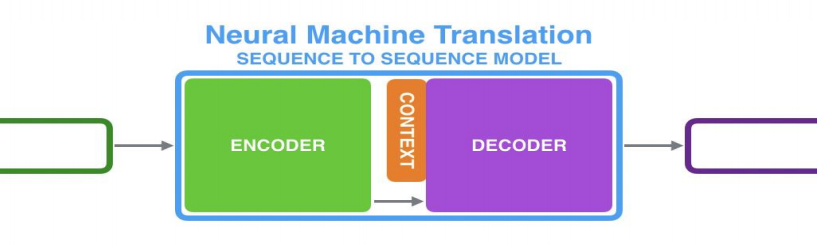
Seq2Seq,Encoder,Decoder
引入Attention,Decoder上对输入的各个词施加不同的注意力 https://wx1.sbimg.cn/2020/09/15/9FZGo.png
Self-attention,Transformer,完全基于自注意力机制

Bert,双向Transformer,mask
XLNet,自回归语言模型,自动编码语言模型,摒弃遮盖
{kind=link}
2 注意力机制
以机器翻译为例;Seq2Seq架构;
2.1 RNN + RNN
Encoder处理输入序列,得到上下文CONTEXT(一个向量,代表源文信息);Decoder处理CONTEXT逐项生成输出序列。
RNN在每个时间步接收两个输入
- 隐状态:上一个时间步传递来的;Decoder的初始隐状态为编码阶段的最后一个隐状态
- 词向量输入:Encoder为输入序列的对应位置的词向量;Decoder为上一个时间步的输出(第一个时间步的输入为Start)
上下文向量定长,模型难处理长句
2.2 RNN+RNN+Attention
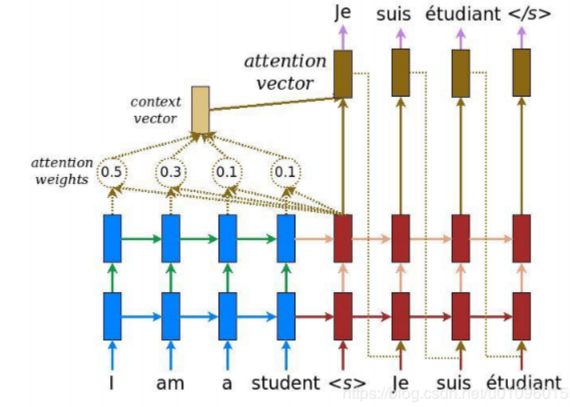
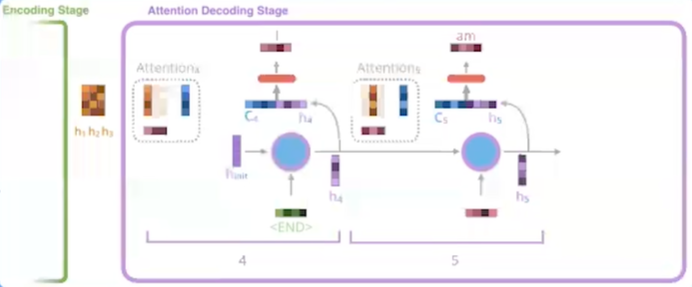
Encoder 向 Decoder 传递更多的数据,不止传递编码阶段的最后一个隐藏状态,而是传递所有隐藏状态。
Decoder增加额外步骤,根据隐状态之间的相关性对不同的隐藏状态打分
为每个编码器隐状态打分;softmax加权;求和

打分后的Encoder隐状态加权后与当前Decoder隐状态结合,作为当前时间步的隐状态输入
Decode 过程中不同的步骤回关注于不同 Encoder 的隐状态
3 Transformer
Attention Is All You Need; self-attention;
3.1 概述
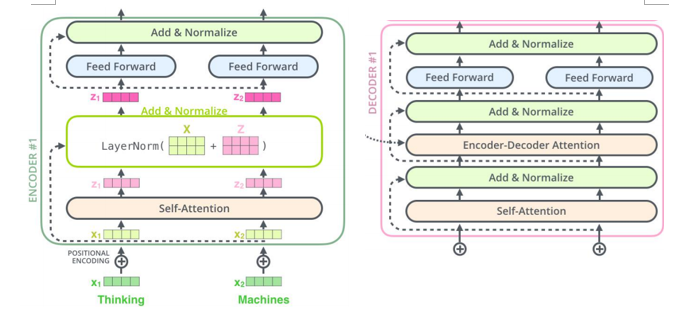
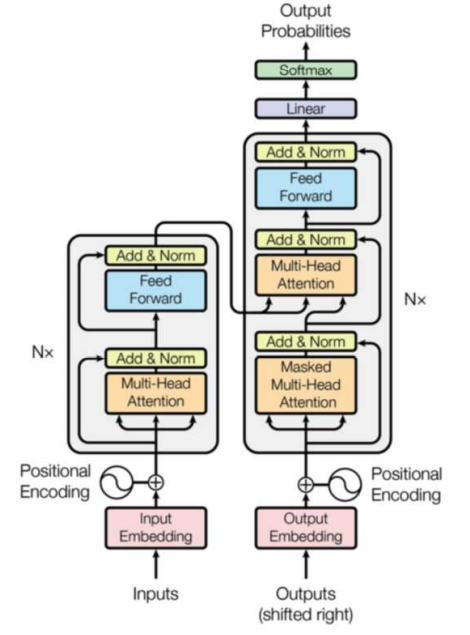
- 仍然由encoder和Decoder组成,完全基于自注意力机制,不使用RNN。
- 编码器和解码器都是一组编码/解码组件组成,原论文使用了6个
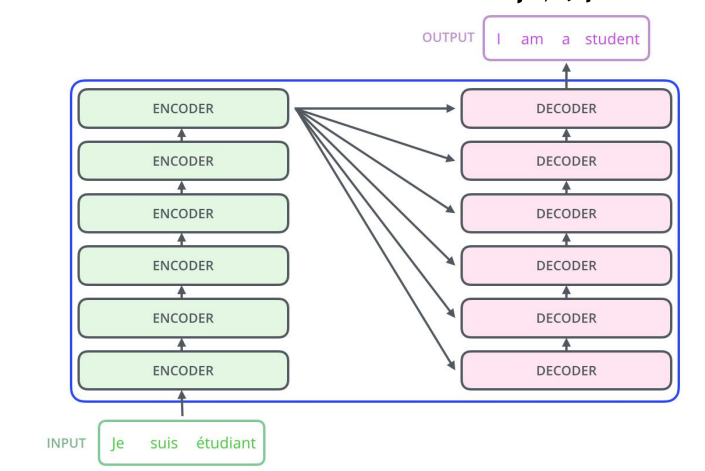
3.2 Encoder 解码器
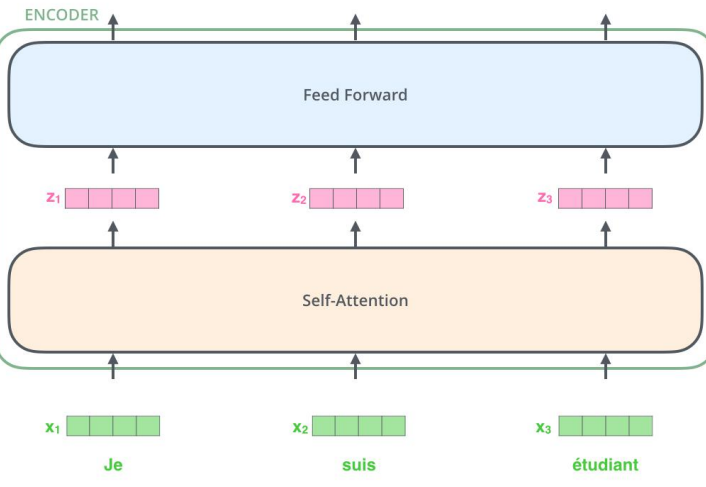
- 编码器由两个子层:自注意力层(见3.3节)、全连接神经网络
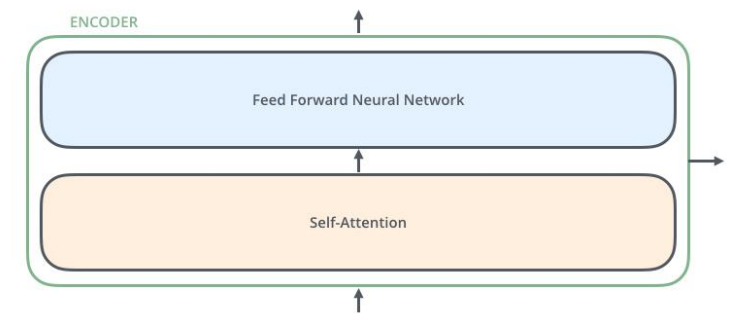
- 每个编码器组件结构相同,但不共享权重。
3.3 自注意力机制
自注意力机制全景图
词嵌入 word embedding
- 发生在最底部的编码器;输入数据[batch_size, word_embedding_size, seq_len];完成嵌入后作为输入经过编码器;每个位置的词并行经过编码器,速度比RNN快。
并行运算未考虑到顺序关系,通过位置编码(positional encoding)使词嵌入包含位置信息。
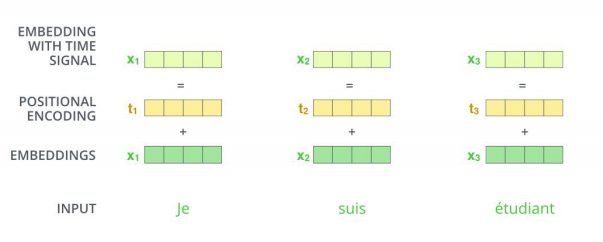
位置编码方式:sin、cos
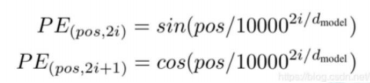
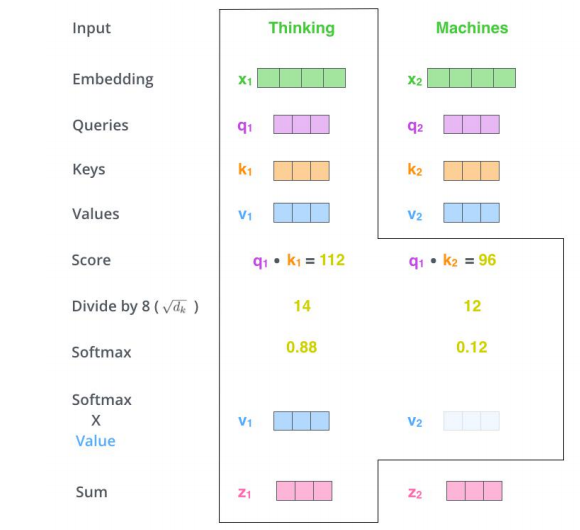
自注意力计算
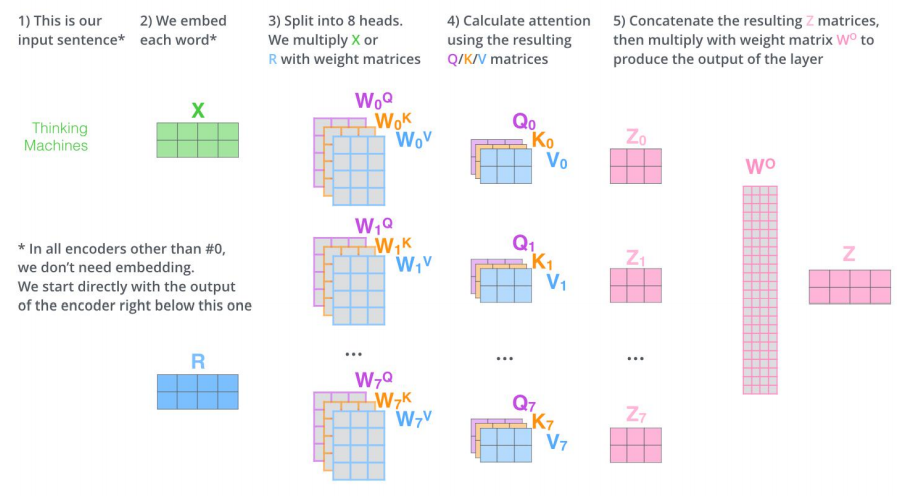
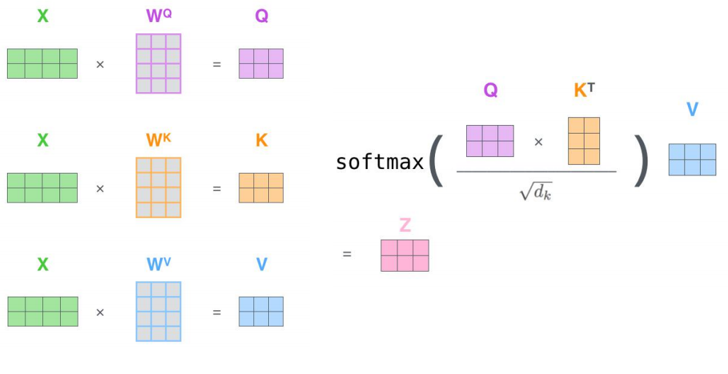
三个参数W(\(W^Q\), \(W^K\),\(W^V\))与输入的向量相乘得到:查询向量q,键向量k,值向量v;新向量维度小于嵌入向量的维数
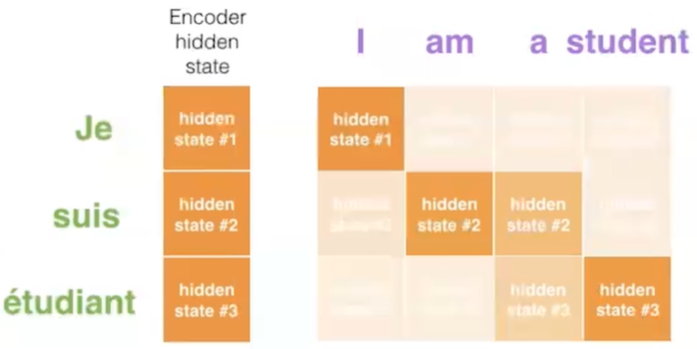
对于一个输入向量,将其q向量与其他词的k向量相乘计算分数;分数高则关系密切
将分数缩放(避免梯度弥散);通过softmax操作转化为概率。
将每个词的v向量用上一步的softmax概率加权求和;得到该输入向量的 z值
234步骤 以矩阵的形式,对多个输入向量并行求z,得到Z矩阵
多头机制
为关注曾提供了多个表示子空间;拓展了模型专注于不同层面的能力
有多组qkv的权重矩阵;e.g. 使用8个关注头则每个编码器解码器会得到8组Z
将所有的Z连接起来和一个权重矩阵\(W^O\)相乘,得到捕捉了所有注意力头的Z矩阵,再将其输入到接下来的全连接层。
3.4 Decoder 解码器
结构:自注意力,encoder-decoder attention,全连接层
自注意力层:仅对输出序列中之前的位置;在softmax之前,把将来生成的位置设置为-inf
encoder-decoder attention
在自注意力层、全连接神经网络之间加入了一个encoder和decoder之间的注意力层,类似seq2seqRNN模型中的注意力。
最后一个Encoder的输出,转换为K和V的集合,每个decoder在其encoder-decoder attention层中使用这些KV。
工作方式与多头注意力类似,区别在于是从Encoder Stack的输出中获取KV。
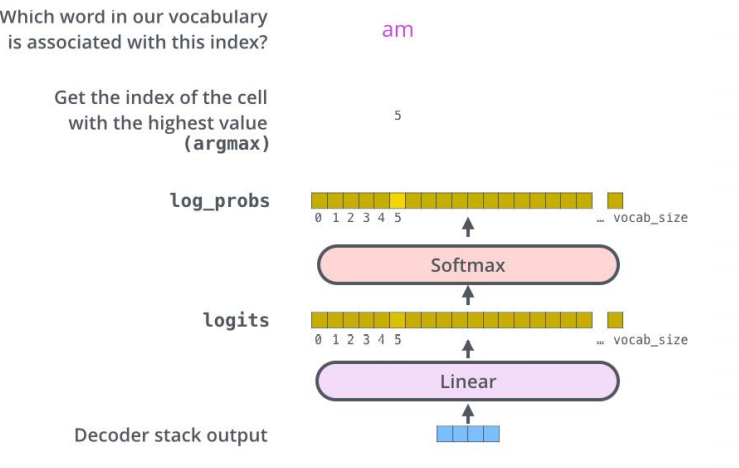
经过N层decoder,最终的输出通过线性层和softmax层得到输出的词
3.5 细节补充
残差和归一化 解码器编码器都有
Attention & Transformer的更多相关文章
- 2. Attention Is All You Need(Transformer)算法原理解析
1. 语言模型 2. Attention Is All You Need(Transformer)算法原理解析 3. ELMo算法原理解析 4. OpenAI GPT算法原理解析 5. BERT算法原 ...
- 深入浅出Transformer
Transformer Transformer是NLP的颠覆者,它创造性地用非序列模型来处理序列化的数据,而且还获得了大成功.更重要的是,NLP真的可以"深度"学习了,各种基于tr ...
- [NLP] REFORMER: THE EFFICIENT TRANSFORMER
1.现状 (1) 模型层数加深 (2) 模型参数量变大 (3) 难以训练 (4) 难以fine-tune 2. 单层参数量和占用内存分析 层 参数设置 参数量与占用内存 1 layer 0.5Bill ...
- 文本建模、文本分类相关开源项目推荐(Pytorch实现)
Awesome-Repositories-for-Text-Modeling repo paper miracleyoo/DPCNN-TextCNN-Pytorch-Inception Deep Py ...
- 关于NLP和深度学习,准备好好看看这个github,还有这篇介绍
这个github感觉很不错,把一些比较新的实现都尝试了: https://github.com/brightmart/text_classification fastText TextCNN Text ...
- BERT解析及文本分类应用
目录 前言 BERT模型概览 Seq2Seq Attention Transformer encoder部分 Decoder部分 BERT Embedding 预训练 文本分类试验 参考文献 前言 在 ...
- ACNet: 特别的想法,腾讯提出结合注意力卷积的二叉神经树进行细粒度分类 | CVPR 2020
论文提出了结合注意力卷积的二叉神经树进行弱监督的细粒度分类,在树结构的边上结合了注意力卷积操作,在每个节点使用路由函数来定义从根节点到叶子节点的计算路径,结合所有叶子节点的预测值进行最终的预测,论文的 ...
- 从RNN到BERT
一.文本特征编码 1. 标量编码 美国:1 中国:2 印度:3 … 朝鲜:197 标量编码问题:美国 + 中国 = 3 = 印度 2. One-hot编码 美国:[1,0,0,0,…,0]中国:[0, ...
- Transformer【Attention is all you need】
前言 Transfomer是一种encoder-decoder模型,在机器翻译领域主要就是通过encoder-decoder即seq2seq,将源语言(x1, x2 ... xn) 通过编码,再解码的 ...
随机推荐
- 你的Idea还可用吗?不妨试试这个神器!
@ 目录 一.STS安装 1.STS下载 2.STS安装 二.STS使用 1.STS配置JDK 2.STS配置Maven 3.使用STS创建SpringBoot项目 三.优化STS 1.主题美化 2. ...
- mySQL初学者需要掌握的【数据库与表的基本操作】
本内容会持续更新的哦! 注:"字段"="列","记录''="行" 文章目录 一:数据库的基本操作 二.数据表的基本操作 1.创建与 ...
- Linux之【安装系统后的调优和安全设置】
关闭SElinux功能 •修改配置文件使其永远生效 第一种修改方法vi vi /etc/sysconfig/selinuc 或者 vi /etc/selinux/config修改: SELINUX=d ...
- 【手把手学习flutter】Flutter打Android包的基本配置和包体积优化策略
[手把手学习flutter]Flutter打Android包的基本配置和包体积优化策略 关注「松宝写代码」,回复"加群" 加入我们一起学习,天天向上 前言 因为最近参加2020FE ...
- Moviepy音视频开发:开发视频转gif动画或jpg图片exe图形化工具的案例
☞ ░ 前往老猿Python博文目录 ░ 一.引言 老猿之所以学习和研究Moviepy的使用,是因为需要一个将视频转成动画的工具,当时在网上到处搜索查找免费使用工具,结果找了很多自称免费的工具,但转完 ...
- TextClip构造方法报OSError:MoviePy creation of None failed because of the following [WinError 2]系统找不到指定的文件
☞ ░ 前往老猿Python博文目录 ░ 在使用moviepy的构造方法创建实例时报错: "C:\Program Files\Python37\python.exe" F:/stu ...
- 第10.2节 查看导入的Python模块
在Python中,要查看导入模块,可以使用sys.modules来查看,不过sys包含了所有导入模块包括内建模块,如果需要过滤掉内建模块甚至扩展模块,则需要对sys.modules进行一下过滤. 一. ...
- PyQt(Python+Qt)学习随笔:QListWidget插入多项的insertItems方法
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 除了insertItem方法能插入项外,QListWidget支持一次插入多个项,对应的方法就是in ...
- Python中高级知识(非专题部分)学习随笔
Python学习随笔:使用xlwings读取和操作Execl文件 Python学习随笔:使用xlwings新建Execl文件和sheet的方法 博客地址:https://blog.csdn.net/L ...
- spring整合mybatis01
title: spring整合mybatis01 date: 2020-03-09 19:47:40 tags:整合的第一种方式 spring整合mybatis 1.mybatis回顾 mybatis ...