Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)
一、使用Logstash将mysql数据导入elasticsearch
1、在mysql中准备数据:
mysql> show tables;
+----------------+
| Tables_in_yang |
+----------------+
| im |
+----------------+
1 row in set (0.00 sec) mysql> select * from im;
+----+------+
| id | name |
+----+------+
| 2 | MSN |
| 3 | QQ |
+----+------+
2 rows in set (0.00 sec)
2、简单实例配置文件准备:
[root@master bin]# cat mysqles.conf
input {
stdin {}
jdbc {
type => "jdbc"
jdbc_connection_string => "jdbc:mysql://192.168.200.100:3306/yang?characterEncoding=UTF-8&autoReconnect=true"
# 数据库连接账号密码;
jdbc_user => "root"
jdbc_password => "010209"
# MySQL依赖包路径;
jdbc_driver_library => "/mnt/mysql-connector-java-5.1.38.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
statement => "SELECT * FROM `im`"
}
}
output {
elasticsearch {
# 配置ES集群地址
hosts => ["192.168.200.100:9200"]
# 索引名字,必须小写
index => "im"
}
stdout {
}
}
3、实例结果:
[root@master bin]# ./logstash -f mysqles.conf
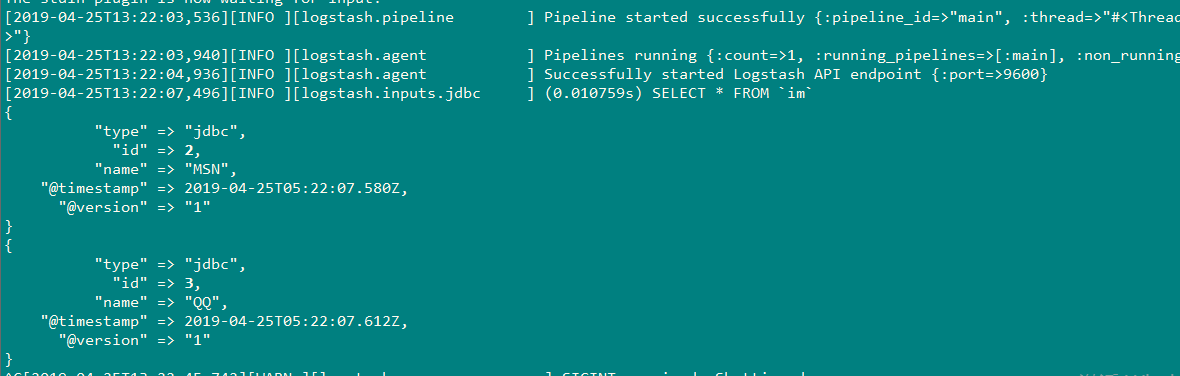

4、更多选项配置如下(单表同步):
input {
stdin {}
jdbc {
type => "jdbc"
# 数据库连接地址
jdbc_connection_string => "jdbc:mysql://192.168.1.1:3306/TestDB?characterEncoding=UTF-8&autoReconnect=true""
# 数据库连接账号密码;
jdbc_user => "username"
jdbc_password => "pwd"
# MySQL依赖包路径;
jdbc_driver_library => "mysql/mysql-connector-java-5.1.34.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 数据库重连尝试次数
connection_retry_attempts => "3"
# 判断数据库连接是否可用,默认false不开启
jdbc_validate_connection => "true"
# 数据库连接可用校验超时时间,默认3600S
jdbc_validation_timeout => "3600"
# 开启分页查询(默认false不开启);
jdbc_paging_enabled => "true"
# 单次分页查询条数(默认100000,若字段较多且更新频率较高,建议调低此值);
jdbc_page_size => "500"
# statement为查询数据sql,如果sql较复杂,建议配通过statement_filepath配置sql文件的存放路径;
# sql_last_value为内置的变量,存放上次查询结果中最后一条数据tracking_column的值,此处即为ModifyTime;
# statement_filepath => "mysql/jdbc.sql"
statement => "SELECT KeyId,TradeTime,OrderUserName,ModifyTime FROM `DetailTab` WHERE ModifyTime>= :sql_last_value order by ModifyTime asc"
# 是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false);
lowercase_column_names => false
# Value can be any of: fatal,error,warn,info,debug,默认info;
sql_log_level => warn
#
# 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中;
record_last_run => true
# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值;
use_column_value => true
# 需要记录的字段,用于增量同步,需是数据库字段
tracking_column => "ModifyTime"
# Value can be any of: numeric,timestamp,Default value is "numeric"
tracking_column_type => timestamp
# record_last_run上次数据存放位置;
last_run_metadata_path => "mysql/last_id.txt"
# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false;
clean_run => false
#
# 同步频率(分 时 天 月 年),默认每分钟同步一次;
schedule => "* * * * *"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
# convert 字段类型转换,将字段TotalMoney数据类型改为float;
mutate {
convert => {
"TotalMoney" => "float"
}
}
}
output {
elasticsearch {
# 配置ES集群地址
hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"]
# 索引名字,必须小写
index => "consumption"
}
stdout {
codec => json_lines
}
}
5、多表同步:
多表配置和单表配置的区别在于input模块的jdbc模块有几个type,output模块就需对应有几个type;
input {
stdin {}
jdbc {
# 多表同步时,表类型区分,建议命名为“库名_表名”,每个jdbc模块需对应一个type;
type => "TestDB_DetailTab"
# 其他配置此处省略,参考单表配置
# ...
# ...
# record_last_run上次数据存放位置;
last_run_metadata_path => "mysql\last_id.txt"
# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false;
clean_run => false
#
# 同步频率(分 时 天 月 年),默认每分钟同步一次;
schedule => "* * * * *"
}
jdbc {
# 多表同步时,表类型区分,建议命名为“库名_表名”,每个jdbc模块需对应一个type;
type => "TestDB_Tab2"
# 多表同步时,last_run_metadata_path配置的路径应不一致,避免有影响;
# 其他配置此处省略
# ...
# ...
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
# output模块的type需和jdbc模块的type一致
if [type] == "TestDB_DetailTab" {
elasticsearch {
# host => "192.168.1.1"
# port => "9200"
# 配置ES集群地址
hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"]
# 索引名字,必须小写
index => "detailtab1"
# 数据唯一索引(建议使用数据库KeyID)
document_id => "%{KeyId}"
}
}
if [type] == "TestDB_Tab2" {
elasticsearch {
# host => "192.168.1.1"
# port => "9200"
# 配置ES集群地址
hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"]
# 索引名字,必须小写
index => "detailtab2"
# 数据唯一索引(建议使用数据库KeyID)
document_id => "%{KeyId}"
}
}
stdout {
codec => json_lines
}
}
二、使用logstash全量同步(1分钟同步一次)mysql数据导入到elasticsearch
配置如下:
input {
stdin {}
jdbc {
type => "jdbc"
jdbc_connection_string => "jdbc:mysql://192.168.200.100:3306/yang?characterEncoding=UTF-8&autoReconnect=true"
# 数据库连接账号密码;
jdbc_user => "root"
jdbc_password => "010209"
# MySQL依赖包路径;
jdbc_driver_library => "/mnt/mysql-connector-java-5.1.38.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
statement => "SELECT * FROM `im`"
schedule => "* * * * *"
}
}
output {
elasticsearch {
# 配置ES集群地址
hosts => ["192.168.200.100:9200"]
# 索引名字,必须小写
index => "im"
}
stdout {
}
}
第一次同步结果:
[2019-04-25T14:39:03,194][INFO ][logstash.inputs.jdbc ] (0.100064s) SELECT * FROM `im`
{
"@version" => "1",
"@timestamp" => 2019-04-25T06:39:03.338Z,
"type" => "jdbc",
"id" => 3,
"name" => "QQ"
}
{
"@version" => "1",
"@timestamp" => 2019-04-25T06:39:03.309Z,
"type" => "jdbc",
"id" => 2,
"name" => "MSN"
}
向mysql插入数据后第二次同步:
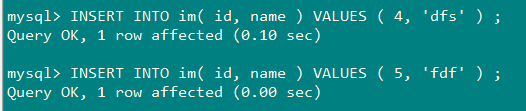
[2019-04-25T14:40:00,295][INFO ][logstash.inputs.jdbc ] (0.001956s) SELECT * FROM `im`
{
"@version" => "1",
"@timestamp" => 2019-04-25T06:40:00.310Z,
"type" => "jdbc",
"id" => 2,
"name" => "MSN"
}
{
"@version" => "1",
"@timestamp" => 2019-04-25T06:40:00.316Z,
"type" => "jdbc",
"id" => 3,
"name" => "QQ"
}
{
"@version" => "1",
"@timestamp" => 2019-04-25T06:40:00.317Z,
"type" => "jdbc",
"id" => 4,
"name" => "dfs"
}
{
"@version" => "1",
"@timestamp" => 2019-04-25T06:40:00.317Z,
"type" => "jdbc",
"id" => 5,
"name" => "fdf"
}
三、使用logstash增量同步(1分钟同步一次)mysql数据导入到elasticsearch
input {
stdin {}
jdbc {
type => "jdbc"
jdbc_connection_string => "jdbc:mysql://192.168.200.100:3306/yang?characterEncoding=UTF-8&autoReconnect=true"
# 数据库连接账号密码;
jdbc_user => "root"
jdbc_password => "010209"
# MySQL依赖包路径;
jdbc_driver_library => "/mnt/mysql-connector-java-5.1.38.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
#是否开启分页
jdbc_paging_enabled => "true"
#分页条数
jdbc_page_size => "50000"
# 执行的sql 文件路径+名称
#statement_filepath => "/data/my_sql2.sql"
#SQL语句,也可以使用statement_filepath来指定想要执行的SQL
statement => "SELECT * FROM `im` where id > :sql_last_value"
#每一分钟做一次同步
schedule => "* * * * *"
#是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false)
lowercase_column_names => false
# 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中;
record_last_run => true
# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值;
use_column_value => true
# 需要记录的字段,用于增量同步,需是数据库字段
tracking_column => "id"
# record_last_run上次数据存放位置;
last_run_metadata_path => "/mnt/sql_last_value"
#是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false)
clean_run => false
}
}
output {
elasticsearch {
# 配置ES集群地址
hosts => ["192.168.200.100:9200"]
# 索引名字,必须小写
index => "im"
}
stdout {
}
}
说明:
由于我上一次最后sql_last_value文件中记录的id为5,当向mysql插入id=6的值时,结果:

插入id=8,7时;
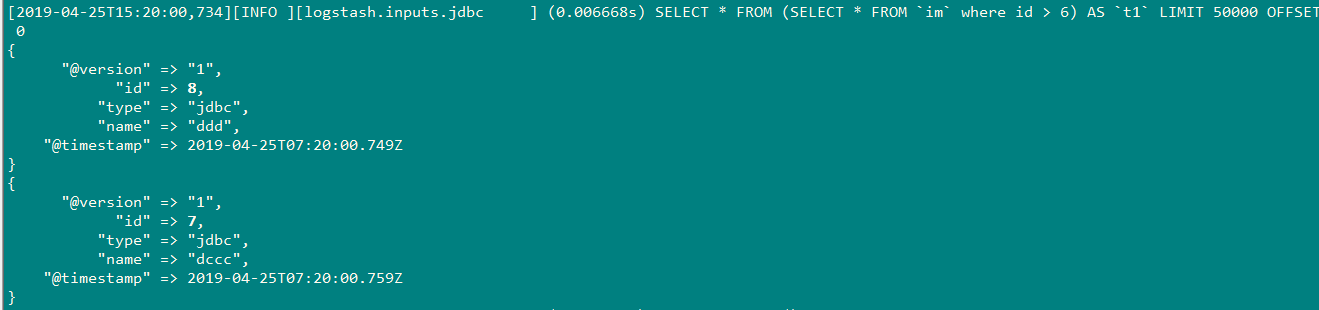
因为我插入的顺序,先插入id 为8,后插入id为7,因此最后一次记录的id为7,当我下一次插入id=9,10时,会重新导入id为8的值。

当我插入id=10的值后,结束,观察sql_last_value文件的最后记录:

结果:

Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)的更多相关文章
- Logstash学习之路(一)Logstash的安装
一.Logstash简介 Logstash 是一个实时数据收集引擎,可收集各类型数据并对其进行分析,过滤和归纳.按照自己条件分析过滤出符合数据导入到可视化界面.它可以实现多样化的数据源数据全量或增量传 ...
- Logstash:把MySQL数据导入到Elasticsearch中
Logstash:把MySQL数据导入到Elasticsearch中 前提条件 需要安装好Elasticsearch及Kibana. MySQL安装 根据不同的操作系统我们分别对MySQL进行安装.我 ...
- 使用Logstash把MySQL数据导入到Elasticsearch中
总结:这种适合把已有的MySQL数据导入到Elasticsearch中 有一个csv文件,把里面的数据通过Navicat Premium 软件导入到数据表中,共有998条数据 文件下载地址:https ...
- Logstash学习之路(五)使用Logstash抽取mysql数据到kakfa
一.Logstash对接kafka测通 说明: 由于我这里kafka是伪分布式,且kafka在伪分布式下,已经集成了zookeeper. 1.先将zk启动,如果是在伪分布式下,kafka已经集成了zk ...
- Logstash学习之路(二)Elasticsearch导入json数据文件
一.数据从文件导入elasticsearch 1.数据准备: 1.数据文件:test.json 2.索引名称:index 3.数据类型:doc 4.批量操作API:bulk {"index& ...
- Redis——学习之路四(初识主从配置)
首先我们配置一台master服务器,两台slave服务器.master服务器配置就是默认配置 端口为6379,添加就一个密码CeshiPassword,然后启动master服务器. 两台slave服务 ...
- 【记录】ELK之logstash同步mysql数据到Elasticsearch ,配置文件详解
本文出处:https://my.oschina.net/xiaowangqiongyou/blog/1812708#comments 截取部分内容以便学习 input { jdbc { # mysql ...
- 实战ELK(6)使用logstash同步mysql数据到ElasticSearch
一.准备 1.mysql 我这里准备了个数据库mysqlEs,表User 结构如下 添加几条记录 2.创建elasticsearch索引 curl -XPUT 'localhost:9200/user ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
随机推荐
- RocketMQ开发者指南
1. 概念和特性 概念:介绍RocketMQ的基本概念模型 1 消息模型(Message Model) RocketMQ主要由 Producer.Broker.Consumer 三部分组成,其中Pro ...
- java视频流的断点续传功能
项目中需要实现浏览器中视频的拖动问题解决 /** * 视频文件的断点续传功能 * @param path 文件路径 * @param request request * @param response ...
- PostgreSQL 如何忽略事务中错误
在 PostgreSQL 的事务中:执行的SQL遇到错误(书写,约束限制):该事务的已经执行的SQL都会进行rollback.那如何忽略其中的错误.将SQL执行到底?在事务中设置 ON_ERROR_R ...
- 题解-CF677D Vanya and Treasure
CF677D Vanya and Treasure 有一个 \(n\times m\) 的矩阵 \(a(1\le a_{i,j}\le p)\),求从起点 \((1,1)\) 出发依次遍历值为 \(1 ...
- window启动mongoDB
windows启动mongo服务 建议使用docker,方便又快捷,可以查看我的其他文章有介绍 创建好日志文件夹后执行以下命令 mongod.exe --logpath "C:\mongod ...
- USB接口禁用小工具v1.0.1
由论坛用户原创制作的一个USB接口工具, 可选择手动/自动启动或者禁止启动模式, 开启禁止启动模式后USB接口将关闭识别功能, 有效防止U盘设备侵入,对于机房实验室设施来说相当管用. 下载地址:htt ...
- MyBatis详细源码解析(上篇)
前言 我会一步一步带你剖析MyBatis这个经典的半ORM框架的源码! 我是使用Spring Boot + MyBatis的方式进行测试,但并未进行整合,还是使用最原始的方式. 项目结构 导入依赖: ...
- 其它语言通过HiveServer2访问Hive
先解释一下几个名词: metadata :hive元数据,即hive定义的表名,字段名,类型,分区,用户这些数据.一般存储关系型书库mysql中,在测试阶段也可以用hive内置Derby数据库. me ...
- 使用docker-maven-plugin打包
今天在部署的时候遇到点问题,总结一下,docker部署的步骤,如果对您有帮助,关注一下,就是对我最大的肯定, 谢谢! 微服务部署有两种方法: (1)手动部署:首先基于源码打包生成jar包(或war包) ...
- R平方回归平方推导