数据结构Java实现05----栈:顺序栈和链式堆栈
一、堆栈的基本概念:
堆栈(也简称作栈)是一种特殊的线性表,堆栈的数据元素以及数据元素间的逻辑关系和线性表完全相同,其差别是线性表允许在任意位置进行插入和删除操作,而堆栈只允许在固定一端进行插入和删除操作。
先进后出:堆栈中允许进行插入和删除操作的一端称为栈顶,另一端称为栈底。堆栈的插入和删除操作通常称为进栈或入栈,堆栈的删除操作通常称为出栈或退栈。
备注:栈本身就是一个线性表,所以我们之前讨论过线性表的顺序存储和链式存储,对于栈来说,同样适用。
二、堆栈的抽象数据类型:
数据集合:
堆栈的数据集合可以表示为a0,a1,…,an-1,每个数据元素的数据类型可以是任意的类类型。
操作集合:
(1)入栈push(obj):把数据元素obj插入堆栈。
(2)出栈pop():出栈, 删除的数据元素由函数返回。
(3)取栈顶数据元素getTop():取堆栈当前栈顶的数据元素并由函数返回。
(4)非空否notEmpty():若堆栈非空则函数返回true,否则函数返回false。
三、顺序栈:
顺序存储结构的堆栈称作顺序堆栈。其存储结构示意图如下图所示:
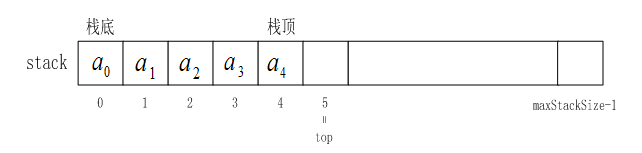
1、顺序栈的实现:
(1)设计Stack接口
(2)实现SequenceStack类
注:栈是线性表的特例,线性表本身就是用数组来实现的。于是,顺序栈也是用数组实现的。
代码实现:
(1)Stack.java:(Stack接口)
public interface Stack {
//入栈
public void push(Object obj) throws Exception;
//出栈
public Object pop() throws Exception;
//获取栈顶元素
public Object getTop() throws Exception;
//判断栈是否为空
public boolean isEmpty();
}
(2)SequenceStack.java:
//顺序栈
public class SequenceStack implements Stack { Object[] stack; //对象数组(栈用数组来实现)
final int defaultSize = 10; //默认最大长度
int top; //栈顶位置(的一个下标):其实可以理解成栈的实际长度
int maxSize; //最大长度 //如果用无参构造的话,就设置默认长度
public SequenceStack() {
init(defaultSize);
} //如果使用带参构造的话,就调用指定的最大长度
public SequenceStack(int size) {
init(size);
} public void init(int size) {
this.maxSize = size;
top = 0;
stack = new Object[size];
} //获取栈顶元素
@Override
public Object getTop() throws Exception {
// TODO Auto-generated method stub
if (isEmpty()) {
throw new Exception("堆栈为空!");
} return stack[top - 1];
} //判断栈是否为空
@Override
public boolean isEmpty() {
// TODO Auto-generated method stub
return top == 0;
} //出栈操作
@Override
public Object pop() throws Exception {
// TODO Auto-generated method stub
if (isEmpty()) {
throw new Exception("堆栈为空!");
}
top--; return stack[top];
} //入栈操作
@Override
public void push(Object obj) throws Exception {
// TODO Auto-generated method stub
//首先判断栈是否已满
if (top == maxSize) {
throw new Exception("堆栈已满!");
}
stack[top] = obj;
top++;
}
}
2、测试类:
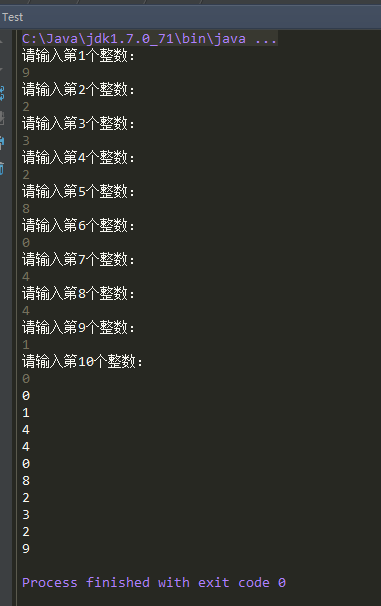
设计一个顺序栈,从键盘输入十个整数压进栈,然后再弹出栈,并打印出栈序列。
代码实现:
(3)Test.java:
import java.util.Scanner;
public class Test {
public static void main(String[] args) throws Exception {
SequenceStack stack = new SequenceStack(10);
Scanner in = new Scanner(System.in);
int temp;
for (int i = 0; i < 10; i++) {
System.out.println("请输入第" + (i + 1) + "个整数:");
temp = in.nextInt();
stack.push(temp);
}
//遍历输出
while (!stack.isEmpty()) {
System.out.println(stack.pop());
}
}
}
运行效果:
四、Java中栈与堆的区别:
栈(stack):(线程私有)
是一个先进后出的数据结构,通常用于保存方法(函数)中的参数,局部变量。在java中,所有基本类型和引用类型的引用都在栈中存储。栈中数据的生存空间一般在当前scopes内(就是由{...}括起来的区域)。
堆(heap):(线程共享)
是一个可动态申请的内存空间(其记录空闲内存空间的链表由操作系统维护),C中的malloc语句所产生的内存空间就在堆中。在java中,所有使用new xxx()构造出来的对象都在堆中存储,当垃圾回收器检测到某对象未被引用,则自动销毁该对象。所以,理论上说java中对象的生存空间是没有限制的,只要有引用类型指向它,则它就可以在任意地方被使用。
五、hashCode与对象之间的关系:
如果两个对象的hashCode不相同,那么这两个对象肯定也不同。
如果两个对象的hashCode相同,那么这两个对象有可能相同,也有可能不同。
总结一句:不同的对象可能会有相同的hashCode;但是如果hashCode不同,那肯定不是同一个对象。
代码举例:
public class StringTest {
public static void main(String[] args) {
//s1 和 s2 其实是同一个对象。对象的引用存放在栈中,对象存放在方法区的字符串常量池
String s1 = "china";
String s2 = "china";
//凡是用new关键创建的对象,都是在堆内存中分配空间。
String s3 = new String("china");
//凡是new出来的对象,绝对是不同的两个对象。
String s4 = new String("china");
System.out.println(s1 == s2); //true
System.out.println(s1 == s3);
System.out.println(s3 == s4);
System.out.println(s3.equals(s4));
System.out.println("\n-----------------\n");
/*String很特殊,重写从父类继承过来的hashCode方法,使得两个
*如果字符串里面的内容相等,那么hashCode也相等。
**/
//hashCode相同
System.out.println(s3.hashCode()); //hashCode为94631255
System.out.println(s4.hashCode()); //hashCode为94631255
//identityHashCode方法用于获取原始的hashCode
//如果原始的hashCode不同,表明确实是不同的对象
//原始hashCode不同
System.out.println(System.identityHashCode(s3)); //
System.out.println(System.identityHashCode(s4)); //
System.out.println("\n-----------------\n");
//hashCode相同
System.out.println(s1.hashCode()); //
System.out.println(s2.hashCode()); //94631255
//原始hashCode相同:表明确实是同一个对象
System.out.println(System.identityHashCode(s1)); //
System.out.println(System.identityHashCode(s2)); //
}
}
上面的代码中,注释已经标明了运行的结果。通过运行结果我们可以看到,s3和s4的字符串内容相同,但他们是两个不同的对象,由于String类重写了hashCode方法,他们的hashCode相同,但原始的hashCode是不同的。
六、链式堆栈:
链式存储结构的堆栈称作链式堆栈。
与单链表相同,链式堆栈也是由一个个结点组成的,每个结点由两个域组成,一个是存放数据元素的数据元素域data,另一个是存放指向下一个结点的对象引用(即指针)域next。
堆栈有两端,插入数据元素和删除数据元素的一端为栈顶,另一端为栈底。链式堆栈都设计成把靠近堆栈头head的一端定义为栈顶。
依次向链式堆栈入栈数据元素a0, a1, a2, ..., an-1后,链式堆栈的示意图如下图所示:

1、设计链式堆栈:
(1)Node.java:结点类
//结点类
public class Node { Object element; //数据域
Node next; //指针域 //头结点的构造方法
public Node(Node nextval) {
this.next = nextval;
} //非头结点的构造方法
public Node(Object obj, Node nextval) {
this.element = obj;
this.next = nextval;
} //获得当前结点的后继结点
public Node getNext() {
return this.next;
} //获得当前的数据域的值
public Object getElement() {
return this.element;
} //设置当前结点的指针域
public void setNext(Node nextval) {
this.next = nextval;
} //设置当前结点的数据域
public void setElement(Object obj) {
this.element = obj;
} public String toString() {
return this.element.toString();
}
}
(2)Stack.java:
//栈接口
public interface Stack { //入栈
public void push(Object obj) throws Exception; //出栈
public Object pop() throws Exception; //获得栈顶元素
public Object getTop() throws Exception; //判断栈是否为空
public boolean isEmpty();
}
(3)LinkStack.java:
public class LinkStack implements Stack {
Node head; //栈顶指针
int size; //结点的个数
public LinkStack() {
head = null;
size = 0;
}
@Override
public Object getTop() throws Exception {
// TODO Auto-generated method stub
return head.getElement();
}
@Override
public boolean isEmpty() {
// TODO Auto-generated method stub
return head == null;
}
@Override
public Object pop() throws Exception {
// TODO Auto-generated method stub
if (isEmpty()) {
throw new Exception("栈为空!");
}
Object obj = head.getElement();
head = head.getNext();
size--;
return obj;
}
@Override
public void push(Object obj) throws Exception {
// TODO Auto-generated method stub
head = new Node(obj, head);
size++;
}
(4)Test.java:测试类
import java.util.Scanner;
public class Test {
public static void main(String[] args) throws Exception {
//SequenceStack stack = new SequenceStack(10);
LinkStack stack = new LinkStack();
Scanner in = new Scanner(System.in);
int temp;
for (int i = 0; i < 10; i++) {
System.out.println("请输入第" + (i + 1) + "个整数:");
temp = in.nextInt();
stack.push(temp);
}
//遍历输出
while (!stack.isEmpty()) {
System.out.println(stack.pop());
}
}
}
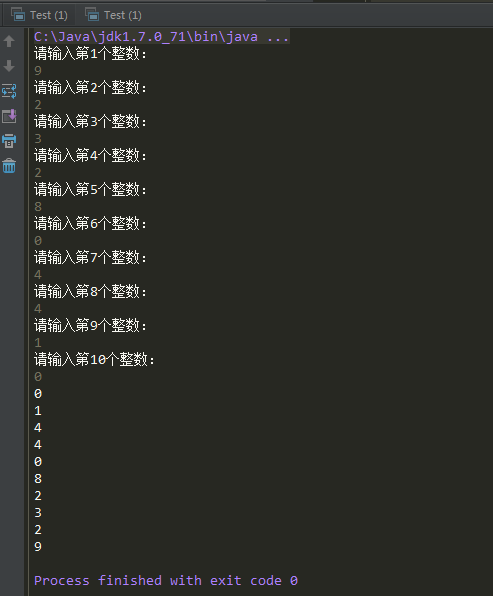
运行效果:
七、堆栈的应用:
堆栈是各种软件系统中应用最广泛的数据结构之一。括号匹配和表达式计算是编译软件中的基本问题,其软件设计中都需要使用堆栈。
- 括号匹配问题
- 表达式计算
1、括号匹配问题:
假设算术表达式中包含圆括号,方括号,和花括号三种类型。使用栈数据结构编写一个算法判断表达式中括号是否正确匹配,并设计一个主函数测试。
比如:
{a+[b+(c*a)/(d-e)]} 正确
([a+b)-(c*e)]+{a+b} 错误,中括号的次序不对
括号匹配有四种情况:
1.左右括号匹配次序不正确
2.右括号多于左括号
3.左括号多于右括号
4.匹配正确
下面我们就通过代码把这四种情况列举出来。
代码实现:
public class Test {
//方法:将字符串转化为字符串数组
public static String[] expToStringArray(String exp) {
int n = exp.length();
String[] arr = new String[n];
for (int i = 0; i < arr.length; i++) {
arr[i] = exp.substring(i, i + 1);
}
return arr;
}
//方法:括号匹配问题的检测
public static void signCheck(String exp) throws Exception {
SequenceStack stack = new SequenceStack();
String[] arr = Test.expToStringArray(exp);
for (int i = 0; i < arr.length; i++) {
if (arr[i].equals("(") || arr[i].equals("[") || arr[i].equals("{")) { //当碰到都是左边的括号的时候,统统压进栈
stack.push(arr[i]);
} else if (arr[i].equals(")") && !stack.isEmpty() && stack.getTop().equals("(")) { //当碰到了右小括号时,如果匹配正确,就将左小括号出栈
stack.pop();
} else if (arr[i].equals(")") && !stack.isEmpty() && !stack.getTop().equals("(")) {
System.out.println("左右括号匹配次序不正确!");
return;
} else if (arr[i].equals("]") && !stack.isEmpty() && stack.getTop().equals("[")) {
stack.pop();
} else if (arr[i].equals("]") && !stack.isEmpty() && !stack.getTop().equals("[")) {
System.out.println("左右括号匹配次序不正确!");
return;
} else if (arr[i].equals("}") && !stack.isEmpty() && stack.getTop().equals("{")) {
stack.pop();
} else if (arr[i].equals("}") && !stack.isEmpty() && !stack.getTop().equals("{")) {
System.out.println("左右括号匹配次序不正确!");
return;
} else if (arr[i].equals(")") || arr[i].equals("]") || arr[i].equals("}") && stack.isEmpty()) {
System.out.println("右括号多于左括号!");
return;
}
}
if (!stack.isEmpty()) {
System.out.println("左括号多于右括号!");
} else {
System.out.println("括号匹配正确!");
}
}
public static void main(String[] args) throws Exception {
String str = "([(a+b)-(c*e)]+{a+b}";
//括号匹配的检测
Test.signCheck(str);
}
}
运行效果:
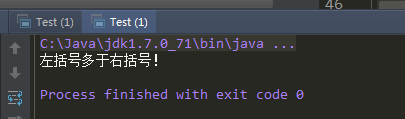
上方代码中,第50行是一个错误的括号表达式,于是运行结果也很明显了。
2、表达式计算:
比如:
3+(6-4/2)*5=23
其后缀表达式为:3642/-5*+# (#符号为结束符)
现在要做的是:
使用链式堆栈,设计一个算法计算表达式,当我们输入后缀表达式后,能输出运行结果。
代码实现:
public class Test {
//方法:使用链式堆栈,设计一个算法计算表达式
public static void expCaculate(LinkStack stack) throws Exception {
char ch; //扫描每次输入的字符。
int x1, x2, b = 0; //x1,x2:两个操作数 ,b字符的ASCII码
System.out.println("输入后缀表达式并以#符号结束:");
while ((ch = (char) (b = System.in.read())) != '#') {
//如果是数字,说明是操作数则压入堆栈
if (Character.isDigit(ch)) {
stack.push(new Integer(Character.toString(ch)));
}
//如果不是数字,说明是运算符
else {
x2 = ((Integer) stack.pop()).intValue();
x1 = ((Integer) stack.pop()).intValue();
switch (ch) {
case '+':
x1 += x2;
break;
case '-':
x1 -= x2;
break;
case '*':
x1 *= x2;
break;
case '/':
if (x2 == 0) {
throw new Exception("分母不能为零!");
} else {
x1 /= x2;
}
break;
}
stack.push(new Integer(x1));
}
}
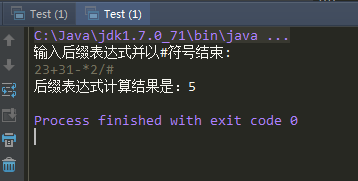
System.out.println("后缀表达式计算结果是:" + stack.getTop());
}
public static void main(String[] args) throws Exception {
LinkStack stack = new LinkStack();
//(2+3)*(3-1)/2=5的后缀表达式为:23+31-*2/
//方法:键盘输入后缀表达式,输出的得到计算结果
Test.expCaculate(stack);
}
}
运行效果:
数据结构Java实现05----栈:顺序栈和链式堆栈的更多相关文章
- 数据结构Java实现03----栈:顺序栈和链式堆栈
一.堆栈的基本概念: 堆栈(也简称作栈)是一种特殊的线性表,堆栈的数据元素以及数据元素间的逻辑关系和线性表完全相同,其差别是线性表允许在任意位置进行插入和删除操作,而堆栈只允许在固定一端进行插入和删除 ...
- Java实现线性表-顺序表示和链式表示
顺序表示和链式表示的比较: 1.读写方式:顺序表可以顺序存取,也可以随机存取:链表只能从表头顺序存取元素: 2.逻辑结构与物理结构:顺序存储时,逻辑上相邻的元素其对应的物理存储位置也相邻:链式存储时, ...
- [Java算法分析与设计]--顺序栈的实现
在程序的世界,栈的应用是相当广泛的.其后进先出的特性,我们可以应用到诸如计算.遍历.代码格式校对等各个方面.但是你知道栈的底层是怎么实现的吗?现在跟随本篇文章我们来一睹它的庐山真面目吧. 首先我们先定 ...
- java 实现简单的顺序栈
package com.my; import java.util.Arrays; /** * 顺序栈 * @author wanjn * */ public class ArrayStack { pr ...
- 数据结构(C实现)------- 顺序栈
栈是限定仅在表的一端进行插入或删除的纯属表,通常称同意插入.删除的一端为栈顶(Top),对应在的.则称还有一端为栈底(Bottom). 不含元素的栈则称为空栈. 所设栈S={a1,a2,a3,..., ...
- javascript实现数据结构与算法系列:栈 -- 顺序存储表示和链式表示及示例
栈(Stack)是限定仅在表尾进行插入或删除操作的线性表.表尾为栈顶(top),表头为栈底(bottom),不含元素的空表为空栈. 栈又称为后进先出(last in first out)的线性表. 堆 ...
- 栈的顺序存储和链式存储c语言实现
一. 栈 栈的定义:栈是只允许在一端进行插入或删除操作的线性表. 1.栈的顺序存储 栈顶指针:S.top,初始设为-1 栈顶元素:S.data[S.top] 进栈操作:栈不满时,栈顶指针先加1,再到栈 ...
- [Java算法分析与设计]--链式堆栈的设计
在上篇文章当中,我们实现了底层为数组的顺序栈.在我之前的文章中也提到过:以数组为数据结构基础在存储数据方面需要一整块连续的内存来存放数据,一旦遇到需要可以动态扩展的功能需求时如果数据量大可能会给虚拟机 ...
- [置顶] ※数据结构※→☆线性表结构(queue)☆============优先队列 链式存储结构(queue priority list)(十二)
优先队列(priority queue) 普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除.在优先队列中,元素被赋予优先级.当访问元素时,具有最高优先级的元素最先删除.优先队列具有 ...
随机推荐
- Runtime -----那些被忽略的技能
有人说现在的程序员都被惯坏了,尤其使用一些面向对象的语言开发的时候,只是简单的调用一些系统封装好的接口或者是调用一些“便利的”第三方,对于一个程序的真正实现有了解吗???又有多少了解呢 ...
- docker 使用
https://www.digitalocean.com/community/tutorials/how-to-use-the-digitalocean-docker-application http ...
- [js开源组件开发]-手机端照片预览组件
手机端照片预览组件 可怜的我用着华为3C手机,用别人现成的组件都好卡,为了适应我这种屌丝,于是自己简化写了一版的照片预览效果,暂时无缩放功能,以后可能有空再加吧,你也可以自己加下,这是个github上 ...
- java多线程系列4-线程池
在之前的文章中,学习了通过实现java.lang.Runnable来定义类,以及像下面这样创建一个线程来运行任务: Runnable task = new TaskClass(task); new T ...
- 多线程基础(五)NSThread线程通信
5.多线程基础 线程间通信 什么叫线程间通信 在一个进程中,线程往往不是孤立存在的,多个线程之间需要经常进行通信 线程间通信的体现 1个线程传递数据给另一个线程 在1个线程中执行完特定任务后, ...
- 远程连接mysql容易遇到的2个问题
1."com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure The las ...
- 菜鸟教程 Python100例 之实例29
学习编程的路,走得好艰辛... 为了巩固基础知识,把菜鸟教程网上的实例拿来练习.. 在做到实例29时,看了网站给出的代码,觉得可以加强一下功能,不由得动了一下脑筋,如下: 原文题目: 题目:给一个不多 ...
- Java Concurrency In Practice -Chapter 2 Thread Safety
Writing thread-safe code is managing access to state and in particular to shared, mutable state. Obj ...
- 编写一个Java程序,计算半径为3.0的圆周长和面积并输出结果。把圆周率π定义为常量,半径定义为变量,然后进行计算并输出结果。
- cocos2d-x之场景转换特效
bool HelloWorld::init() { if ( !Layer::init() ) { return false; } Size visibleSize = Director::getIn ...