Sql Server之旅——第十一站 简单说说sqlserver的执行计划
我们知道sql在底层的执行给我们上层人员开了一个窗口,那就是执行计划,有了执行计划之后,我们就清楚了那些烂sql是怎么执行的,这样
就可以方便的找到sql的缺陷和优化点。
一:执行计划生成过程
说到执行计划,首先要知道的是执行计划大概生成的过程,这样就可以做到就心中有数了,下面我画下简图:

1. 分析过程
这三个比较容易理解,首先我们要保证sql的语法不能错误,select和join的表是必须存在的,以及你是有执行这个sql的权限,对不对。。。
这样我们就走完了执行计划生命周期的第一个流程。
2. 编译过程
保证了上面sql这三点的话,引擎就必须硬着头皮看你这么一大坨烂sql,该删的删,该改的改,该转换的转换,比如说你的“子查询”会转化为
“表连接”等等。。。其实也挺难为引擎的,举个例子吧。
<1>子查询生成的sql:

<2>join生成的sql:
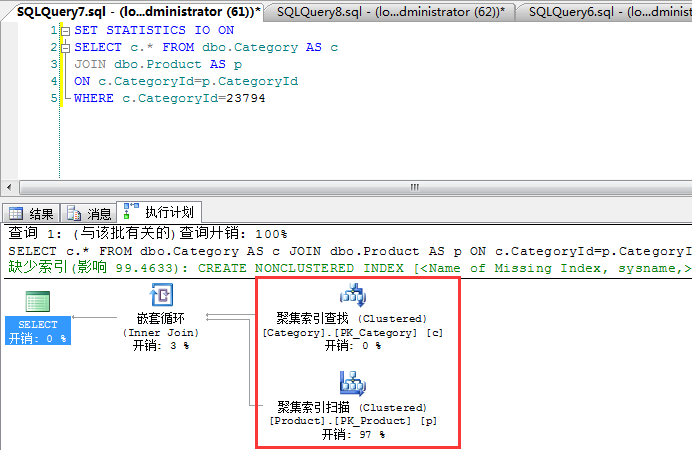
从上面的两个结果中,你可以看到,大家都是玩join的,如果你仔细看的话,会发现一个是“哈希匹配”,一个是“嵌套循环”,为什么不一样,这
当然是引擎根据很多情况综合评选出来的,比如说:磁盘IO,逻辑读,资源占用,硬件环境等等。。。这也是所谓的“计划选优”操作。
3.执行过程
既然执行计划都选出来了,理所当然就要执行了,执行完后会把sql和执行计划放入缓存,这样下次有同样的sql过来的时候就可以直接从
Cache中提取了,不需要再次生成计划了,你也看到,生成执行计划还是比较消耗CPU时间的。
二:看看sql和执行的计划的缓存
刚才也说了,sql和plan都已经放入缓存了,那我的好奇心比较强,我就想看看sql和plan到底在哪,并且长的是个什么丑样子,刚好
sqlserver还是比较能够满足我们G点的。
1. 为了方便查看缓存,我需要先将所有的缓存清空,比如下面的语句。
DBCC freeproccache
SELECT c.* FROM dbo.Category AS c
JOIN dbo.Product AS p
ON c.CategoryId=p.CategoryId
WHERE c.CategoryId=23794
2. 通过sys.dm_exec_cached_plans拿到sql和plan的指针(plan_handle),如下图
SELECT * FROM sys.dm_exec_cached_plans

从图中你看到了两个adhoc(即时查询),分别是我在第一步执行的join查询和我在第二步执行的这个select。
3. 现在我们已经拿到了2个adhoc的plan_handle,然后通过dm_exec_sql_text查看他们的sql分别是怎样?

4. 看完text缓存,接下来我们继续看看sql的plan缓存在哪?可以通过dm_exec_query_plan来查看。
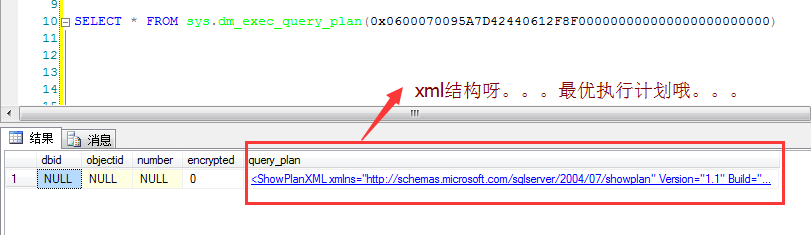
上面的query_plan字段就是所谓的执行计划,以xml的形式保存在字段中。。。所以说解析这个xml还是很费时间的。。。
<?xml version="1.0"?>
<ShowPlanXML xmlns="http://schemas.microsoft.com/sqlserver/2004/07/showplan" Version="1.1" Build="10.0.1600.22">
<BatchSequence>
<Batch>
<Statements>
<StmtSimple StatementText="SELECT c.* FROM dbo.Category AS c
JOIN dbo.Product AS p
ON c.CategoryId=p.CategoryId
WHERE c.CategoryId=23794" StatementId="1" StatementCompId="1" StatementType="SELECT" StatementSubTreeCost="1.33278" StatementEstRows="1.03803" StatementOptmLevel="FULL" QueryHash="0xB10B821B9B5E6396" QueryPlanHash="0x8C7B3B1660E28D16">
<StatementSetOptions QUOTED_IDENTIFIER="true" ARITHABORT="true" CONCAT_NULL_YIELDS_NULL="true" ANSI_NULLS="true" ANSI_PADDING="true" ANSI_WARNINGS="true" NUMERIC_ROUNDABORT="false" />
<QueryPlan CachedPlanSize="16" CompileTime="2" CompileCPU="2" CompileMemory="168">
<MissingIndexes>
<MissingIndexGroup Impact="99.4633">
<MissingIndex Database="[MYPETSHOP]" Schema="[dbo]" Table="[Product]">
<ColumnGroup Usage="EQUALITY">
<Column Name="[CategoryId]" ColumnId="2" />
</ColumnGroup>
</MissingIndex>
</MissingIndexGroup>
<MissingIndexGroup Impact="99.4636">
<MissingIndex Database="[MYPETSHOP]" Schema="[dbo]" Table="[Product]">
<ColumnGroup Usage="EQUALITY">
<Column Name="[CategoryId]" ColumnId="2" />
</ColumnGroup>
</MissingIndex>
</MissingIndexGroup>
</MissingIndexes>
<RelOp NodeId="0" PhysicalOp="Nested Loops" LogicalOp="Inner Join" EstimateRows="1.03803" EstimateIO="0" EstimateCPU="4.33898e-006" AvgRowSize="97" EstimatedTotalSubtreeCost="1.33278" Parallel="0" EstimateRebinds="0" EstimateRewinds="0">
<OutputList>
<ColumnReference Database="[MYPETSHOP]" Schema="[dbo]" Table="[Category]" Alias="[c]" Column="CategoryId" />
<ColumnReference Database="[MYPETSHOP]" Schema="[dbo]" Table="[Category]" Alias="[c]" Column="Name" />
<ColumnReference Database="[MYPETSHOP]" Schema="[dbo]" Table="[Category]" Alias="[c]" Column="Image" />
</OutputList>
<NestedLoops Optimized="0">
<RelOp NodeId="1" PhysicalOp="Clustered Index Seek" LogicalOp="Clustered Index Seek" EstimateRows="1" EstimateIO="0.003125" EstimateCPU="0.0001581" AvgRowSize="97" EstimatedTotalSubtreeCost="0.0032831" TableCardinality="1.00001e+006" Parallel="0" EstimateRebinds="0" EstimateRewinds="0">
<OutputList>
<ColumnReference Database="[MYPETSHOP]" Schema="[dbo]" Table="[Category]" Alias="[c]" Column="CategoryId" />
<ColumnReference Database="[MYPETSHOP]" Schema="[dbo]" Table="[Category]" Alias="[c]" Column="Name" />
<ColumnReference Database="[MYPETSHOP]" Schema="[dbo]" Table="[Category]" Alias="[c]" Column="Image" />
</OutputList>
<IndexScan Ordered="1" ScanDirection="FORWARD" ForcedIndex="0" ForceSeek="0" NoExpandHint="0">
<DefinedValues>
<DefinedValue>
<ColumnReference Database="[MYPETSHOP]" Schema="[dbo]" Table="[Category]" Alias="[c]" Column="CategoryId" />
</DefinedValue>
<DefinedValue>
<ColumnReference Database="[MYPETSHOP]" Schema="[dbo]" Table="[Category]" Alias="[c]" Column="Name" />
</DefinedValue>
<DefinedValue>
<ColumnReference Database="[MYPETSHOP]" Schema="[dbo]" Table="[Category]" Alias="[c]" Column="Image" />
</DefinedValue>
</DefinedValues>
<Object Database="[MYPETSHOP]" Schema="[dbo]" Table="[Category]" Index="[PK_Category]" Alias="[c]" IndexKind="Clustered" />
<SeekPredicates>
<SeekPredicateNew>
<SeekKeys>
<Prefix ScanType="EQ">
<RangeColumns>
<ColumnReference Database="[MYPETSHOP]" Schema="[dbo]" Table="[Category]" Alias="[c]" Column="CategoryId" />
</RangeColumns>
<RangeExpressions>
<ScalarOperator ScalarString="(23794)">
<Const ConstValue="(23794)" />
</ScalarOperator>
</RangeExpressions>
</Prefix>
</SeekKeys>
</SeekPredicateNew>
</SeekPredicates>
</IndexScan>
</RelOp>
<RelOp NodeId="2" PhysicalOp="Clustered Index Scan" LogicalOp="Clustered Index Scan" EstimateRows="1.03803" EstimateIO="1.18831" EstimateCPU="0.0983419" AvgRowSize="11" EstimatedTotalSubtreeCost="1.28665" TableCardinality="89259" Parallel="0" EstimateRebinds="0" EstimateRewinds="0">
<OutputList />
<IndexScan Ordered="0" ForcedIndex="0" NoExpandHint="0">
<DefinedValues />
<Object Database="[MYPETSHOP]" Schema="[dbo]" Table="[Product]" Index="[PK_Product]" Alias="[p]" IndexKind="Clustered" />
<Predicate>
<ScalarOperator ScalarString="[MYPETSHOP].[dbo].[Product].[CategoryId] as [p].[CategoryId]=(23794)">
<Compare CompareOp="EQ">
<ScalarOperator>
<Identifier>
<ColumnReference Database="[MYPETSHOP]" Schema="[dbo]" Table="[Product]" Alias="[p]" Column="CategoryId" />
</Identifier>
</ScalarOperator>
<ScalarOperator>
<Const ConstValue="(23794)" />
</ScalarOperator>
</Compare>
</ScalarOperator>
</Predicate>
</IndexScan>
</RelOp>
</NestedLoops>
</RelOp>
</QueryPlan>
</StmtSimple>
</Statements>
</Batch>
</BatchSequence>
</ShowPlanXML>
好了,到现在你应该认识到重新生成执行计划是不容易的。。。下一篇我们讨论讨论重用,重编译,重新生成等相关情况。
Sql Server之旅——第十一站 简单说说sqlserver的执行计划的更多相关文章
- Sql Server之旅——第五站 确实不得不说的DBCC命令
原文:Sql Server之旅--第五站 确实不得不说的DBCC命令 今天研发中心办年会,晚上就是各自部门聚餐了,我个人喜欢喝干红,在干红中你可以体味到那种酸甜苦辣...人生何尝不是这样呢???正好 ...
- (转)Sql Server之旅——第八站 复合索引和include索引到底有多大区别?
索引和锁,这两个主题对我们开发工程师来说,非常的重要...只有理解了这两个主题,我们才能写出高质量的sql语句,在之前的博客中,我所说的 索引都是单列索引...当然数据库不可能只认单列索引,还有我这篇 ...
- Sql Server之旅——第四站 你必须知道的非聚集索引扫描
非聚集索引,这个是大家都非常熟悉的一个东西,有时候我们由于业务原因,sql写的非常复杂,需要join很多张表,然后就泪流满面了...这时候就 有DBA或者资深的开发给你看这个猥琐的sql,通过执行计划 ...
- Sql Server之旅——第七站 为什么都说状态少的字段不能建索引
我们在学sqlserver的时候,大多教科书和前辈们都说状态少的字段不要建索引,由此带来的开销还不如不建索引,但是这句话有多少人真的知道, 或者说有多少人真的对此有比较深刻的理解,而不是听别人道听途说 ...
- Sql Server之旅——第六站 使用winHex利器加深理解数据页
这篇我来介绍一个winhex利器,这个工具网上有介绍,用途大着呢,可以用来玩数据修复,恢复删除文件等等....它能够将一个file解析成 hex形式,这样你就可以对hex进行修改,然后你就可以看到修复 ...
- Sql Server之旅——第十三站 对锁的初步认识
终于这个系列快结束了,马上又要过年了,没什么心情写博客...作为一个开发人员,锁机制也是我们程序员必须掌握的东西,很久之前 在学习锁的时候,都是教科书上怎么说,然后我怎么背,缺少一个工具让我们眼见为实 ...
- Sql Server之旅——第十站 看看DML操作对索引的影响
我们都知道建索引是需要谨慎的,当只有利大于弊的时候才适合建,我们也知道建索引是需要维护成本的,这个维护也就在于DML操作了, 下面我们具体看看到底DML对索引都有哪些内幕.... 一:delete操作 ...
- Sql Server之旅——第八站 复合索引和include索引到底有多大区别?
周末终于搬进出租房了,装了宽带....才发现没网的日子...那是一个怎样的与世隔绝呀...再也受不了那样的日子了....好了,既然网 安上去了,还得继续我的这个系列. 索引和锁,这两个主题对我们开发工 ...
- Sql Server之旅——第三站 解惑那些背了多年聚集索引的人
说到聚集索引,我想每个码农都明白,但是也有很多像我这样的猥程序员,只能用死记硬背来解决这个问题,什么表中只能建一个聚集索引, 然后又扯到了目录查找来帮助读者记忆....问题就在这里,我们不是学文科,, ...
随机推荐
- Mysql高并发优化
一.数据库结构的设计 1.数据行的长度不要超过8020字节,如果超过这个长度的话在物理页中这条数据会占用两行从而造成存储碎片,降低查询效率. 2.能够用数字类型的字段尽量选择数字类型而不用字符串类型的 ...
- spring笔记3 spring MVC的基础知识3
4,spring MVC的视图 Controller得到模型数据之后,通过视图解析器生成视图,渲染发送给用户,用户就看到了结果. 视图:view接口,来个源码查看:它由视图解析器实例化,是无状态的,所 ...
- Go语言的编程范式
由于比较古怪的语言特性,感觉代码的封装性是一种不同的思路. 包管理的火热程度居然没有nodejs高,这是为什么 package form import ( "encoding/gob&quo ...
- JAVA多线程和并发基础面试问答(转载)
JAVA多线程和并发基础面试问答 原文链接:http://ifeve.com/java-multi-threading-concurrency-interview-questions-with-ans ...
- 第 25 章 CSS3 过渡效果
学习要点: 1.过渡简介 2.transition-property 3.transition-duration 4.transition-timing-function 5.transition-d ...
- LGLTagsView
做项目的时候经常会用到标签,比如说现在很多项目中搜索历史用标签展示 和 选择某个产品的不同属性用标签展示....网上的有很多封装好的标签,但是作为一个上进的程序员,都希望能有一个自己写的.其实也是一种 ...
- 关于javascript的一些知识以及循环
javascript的一些知识点:1.常用的五大浏览器:chrome,firefox,Safari,ie,opera 2.浏览器是如何工作的简化版:3.Js由ECMAjavascript;DOM;BO ...
- Asp.net 实现Session分布式储存(Redis,Mongodb,Mysql等) sessionState Custom
对于asp.net 程序员来说,Session的存储方式有InProc.StateServer.SQLServer和Custom,但是Custom确很少有人提及.但Custom确实最好用,目前最实用和 ...
- 25款专业的 WordPress 电子商务网站主题
WordPress 作为最流行的博客系统,插件众多,易于扩充功能.安装和使用都非常方便,而且有许多第三方开发的免费模板,安装方式简单易用.这篇文章和大家分享35款专业的 WordPress 电子商务网 ...
- 如何垂直居中div?面试经常问到
水平居中:给div设置一个宽度,然后添加margin:0 auto属性 div{ width:200px; margin:0 auto;} 让绝对定位的div居中 ;;;;} 重点来了! 水平垂直居中 ...