WordCount的实现和测试
WordCount
一、开头
(1)合作者:201631107110,201631083416
(2)代码地址:https://gitee.com/zhaoxiaoqin/WordCount.git
(3)本次作业链接地址:https://www.cnblogs.com/zhaoxiaoqin/articles/9824449
二、正文
1.项目完成情况:
1.1 基本功能(完成)
wc.exe -c input.c //返回文件 file.c 的字符数
wc.exe -w input.c //返回文件 file.c 的单词总数
wc.exe -l input.c //返回文件 file.c 的总行数
1.2 扩展功能(未完成)
wc.exe -s //递归处理目录下符合条件的文件
wc.exe -a input.c //返回更复杂的数据(代码行 / 空行 / 注释行)
wc.exe -e stopList.txt // 停用词表,统计文件单词总数时,不统计该表中的单词
[file_name]: 文件或目录名,可以处理一般通配符
2.实现代码
2.1 main函数实现参数传递
int main(int argc, char* argv[]) {
Test(argc, argv);//测试
getchar();
return ;
}
2.2 GetOption函数实现参数解析
int *GetOptions(int argc,char* argv[])
{
/* 返回0代表参数有错
* 1 表示读取字母
* 3 表示读取单词
* 5 表示读取行数
* 它们的和代表所要的功能
*/ char* params;
for(int i=;i<argc;i++)
{
params = argv[i];
if(strcmp("-c",params) == )
{
ret[] += ;
}
else if(strcmp("-w",params) == )
{
ret[] += ;
}
else if(strcmp("-l",params) == )
{
ret[] += ;
}
//启动图形界面,则退出命令行结口 }
if(argc > ) {
params = argv[argc - ];
if (strcmp("-o", params) == && argv[argc - ] != NULL) {
result = argv[argc - ];
ret[] = argc - ;
}
else
{
ret[]= argc - ;
}
}else {
ret[] = argc - ;
}
//处理 -o之前缺少输入文件
return ret;
}
2.3 WordCount函数根据解析的参数执行相应操作
void WordCount(int argc,char* argv[])
{
list = createlist();//创建单词列表
char* fileName;
if (argc <= ) {
Help();
exit();
}
GetOptions(argc,argv);
fileName = argv[ret[]];
switch(ret[])
{
case :
ReadChar(fileName);
break;
case :
ReadWord(fileName);
break;
case :
Readlines(fileName);
break;
case : {
ReadChar(fileName);
flag = ;
ReadWord(fileName);
break;
}
case : {
ReadChar(fileName);
flag = ;
Readlines(fileName);
break;
}
case :{
ReadWord(fileName);
flag = ;
Readlines(fileName);
break;
}
case : {
CharWordLine(fileName);
break;
}
default:
Help();
break;
}
}
2.4 ReadChar函数实现对文件的字符统计
void *ReadChar(char* fileName)
{
char* feature = "字符数: ";
char buf;
//int count[1] = {0}; //用来储存字母出现过的次数
int sum = ;
FILE* fp = fopen(fileName,"r");
if (fp == NULL)
{
printf("Fail to open the file!\n");
Help();
exit(-);
}
while(!feof(fp))
{
buf = fgetc(fp);
sum ++;
}
fclose(fp);
int count[] = {sum};
WriteToFile(fileName,count,,feature);
print(fileName, count, , feature);
}
2.5 ReadWord实现对文件的单词统计
void *ReadWord(char* fileName)
{
/*在记录单词个数 的时候,
* 我们通过统计逗号和空格的个数
* 然后通过计算得到单词的个数
* 假设每个单词的长度不超过256字母
*/ char *feature = "单词数:";
getwordCount(fileName);//得到文件的单词统计
printword();
int sum = ;
for (int i = ; i < list.count; i++)
sum += list.list[i].count;//计算总量
int count[] = { sum };
WriteToFile(fileName, count, , feature);
return NULL;
}
2.6 ReadLine 实现对文件行数的统计
void *Readlines(char* fileName)
{
char buf = '\0';
char* feature = "行数: ";
FILE* fp = NULL;
fp = fopen(fileName,"r");
if (fp == NULL)
{
printf("Fail to open the file!\n");
Help();
exit(-);
}
int space[] = {}; //记录行数
while(!feof(fp))
{
buf = fgetc(fp);
if (buf == ) //换行符的ASCII码为10 只要找出所有的换行符就好
{
space[] ++;
}
}
space[] ++; //在最后一个行中会把换行符设置为其他字符,随意需要加1
WriteToFile(fileName,space,,feature);
print(fileName, space, , feature);
//关闭文件
fclose(fp);
}
2.7 WriteToFile函数实现将统计信息存入文件中
void WriteToFile(char* fileName,int count[],int Csize,char* feature)
{
/*fileName 表示读取的文件
* count 表示记录的个数
* Csize 表示记录数组的大小
* feature表示记录的内容 单词或者字母或者行数
* flag 表示只写,还是追加模式,0 表示只写,1表示追加
*/
char *mode = '\0';
if (flag == )
{
mode = "a+";
}
else
{
mode = "w+";
}
int index = ; //记录字符数
for(int i=;i<Csize;i++)
{
if(count[i] != )
{
index += count[i]; //计算总的单词个数
}
}
FILE *fp = NULL;
fp = fopen(result,mode); //将结果写入文件
if (fp == NULL)
{
printf("Failed when writing the count to file\n");
exit(-);
}
fprintf(fp,"%s,%s %d\n",fileName,feature,index); //写入文件 if (list.count > )
{
for (int i = ; i < list.count; i++)
{
fprintf(fp, "%s:%d\n", list.list[i].wordstring, list.list[i].count); //写入文件
}
}
fclose(fp);
}
2.8 getwordCount函数实现对文件中各单词的分离和统计
void getwordCount(char *filename)//得到各单词的个数统计
{
char data[];//假设每行最多100个字符
FILE* fp = NULL;
fp = fopen(filename, "r");
if (fp == NULL)
{
printf("Fail to open the file!\n");
Help();
getchar();
exit(-);
}
while (!feof(fp))
{
fscanf(fp, "%s", &data);
char str[n];
for (int i = ; i < n; i++)
{
str[i] = '\0';
}
int len = ;
for (int i = ; i < strlen(data); i++)
{
char c = data[i];
if (!issplitchar(c))//若不为单词分隔符
{
str[len] = c; len++;
}
else//若为单词分隔符且指针不超过字符长度
{
if (len > )
{
additem(&list, str);//添加
} for (int i = ; i < n; i++)
{
str[i] = '\0';
}
len = ;
}
}
if (len > )
{
additem(&list, str);//添加
}
}
fclose(fp); }
2.9 word和wordlist结构体用于保存单词和单词的个数
typedef struct word//保存单词信息
{
char* wordstring;//内容
int count;//数量
}word; typedef struct wordlist//单词列表定义
{
word *list;//单词列表
int count;//单词种类个数
}wordlist;
3.互审代码情况
| 参数 | 功能 |
| -w | 统计文件中的单词个数以及各单词的个数并写入输出文件中 |
| -l | 统计文件的行数并写入输出文件中 |
| -c | 统计文件中的字符个数并写入输出文件中 |
| -o | 文件的路径 |
已完成WordCount的基本功能,包括字符计数、行数计数、单词统计等,但在单词统计和行数统计同时存在时,输出文件中的行数会写错位,该版本的WordCount可以接收多个参数,比如-w -c -l等,可以同时存在,而-w参数可以统计文本文件中的各单词的个数并将其保存在输出文件中。
4.静态代码检查情况
利用VisualStudio自带的静态代码检测工具对项目进行代码检测后,结果如下:
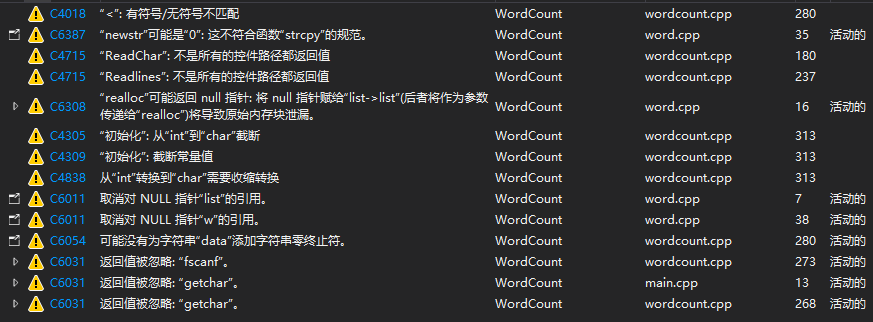
在对出现的风险代码进行修改后,对项目进行测试。
5.测试
5.1 测试用例
| 用例编号 | 输入 | 输出 | 测试结果 |
| 1 | WordCount.exe -c text.txt | 文件字符数:726 | 通过 |
| 2 | WordCount.exe -l text.txt | 文件行数:8 | 通过 |
| 3 | WordCount.exe -w text.txt |
单词种类数:80 |
通过 |
| 4 |
WordCount.exe -c -l text.txt |
文件字符数: :736 |
通过 |
|
5 |
WordCount.exe -c -l -w text.txt |
文件字符数: :736 文件行数:8 |
通过 |
5.2 测试
测试用例1

测试用例2

测试用例3

测试用例4

测试用例5

6.总结
在对项目进行了一系列测试后,发现该项目不存在较大bug,在输入命令参数时,若输入了不合规则的参数,程序会输出提示字符串,但其中的单词统计不能统计诸如I_ptr等带有下划线的单词,可以在后期的改进中,改良分隔字符串检测的算法,该项目的总体思路为:用户在输入参数后,通过main函数的参数传递,将参数传递到GetOption函数中,GetOption函数通过输入参数的个数和种类来解析用户想要执行的命令,并将命令传递到WordCount函数中,对文件执行相应的操作,而在单词统计模块中,该项目自定义了一个结构体来保存单词的字符串和出现次数,当统计函数对文件进行扫描时,每当扫描出一个单词便判断该单词是否在单词列表中,若不在单词列表中则将该单词添加,若在单词列表中则将该单词的次数加1,从而实现了对文件中不同单词的分隔和个数统计。
WordCount的实现和测试的更多相关文章
- 软件质量与测试——WordCount编码实现及测试
1.GitHub地址 https://github.com/noblegongzi/WordCount 2.PSP表格 PSP2.1 PSP 阶段 预估耗时 (分钟) 实际耗时 (分钟) ...
- WordCount 的实现与测试
一.开头 (1)合作者:201631062627,201631062427 (2)代码地址:https://gitee.com/catchcatcat/WordCount.git 二.正文 (1)基本 ...
- WordCount小程序及测试
Github项目地址:https://github.com/792450735/wc PSP表格: PSP2.1表格[1] PSP2.1 PSP阶段 预估耗时 (分钟) 实际耗时 (分钟) Plann ...
- wordcount程序实现与测试
GitHub地址 https://github.com/jiaxuansun/wordcount PSP表格 PSP PSP阶段 预估耗时(分钟) 实际耗时(分钟) Planning 计划 10 5 ...
- 安装Hadoop系列 — 新建MapReduce项目
1.新建MR工程 依次点击 File → New → Ohter… 选择 “Map/Reduce Project”,然后输入项目名称:mrdemo,创建新项目: 2.(这步在以后的开发中可能 ...
- MapReduce-CombineTextInputFormat 切片机制
MapReduce 框架默认的 TextInputFormat 切片机制是对任务按文件规划切片,如果有大量小文件,就会产生大量的 MapTask,处理小文件效率非常低. CombineTextInpu ...
- MapReduce-TextInputFormat 切片机制
MapReduce 默认使用 TextInputFormat 进行切片,其机制如下 (1)简单地按照文件的内容长度进行切片 (2)切片大小,默认等于Block大小,可单独设置 (3)切片时不考虑数据集 ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- CDH- 测试mr
cdh的mr样例算法的jar包在 [zc.lee@ip---- hadoop-0.20-mapreduce]$ pwd /opt/cloudera/parcels/CDH--.cdh5./lib/ha ...
随机推荐
- 小鸟初学Shell编程(七)变量引用及作用范围
变量引用 那么定义好变量,如何打印变量的值呢?举例下变量引用的方式. ${变量名}称作为对变量的引用 echo ${变量名}查看变量的值 ${变量名}在部分情况下可以省略成 $变量名 [root@li ...
- Spark 学习笔记之 aggregateByKey
aggregateByKey: import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD import org.apac ...
- MySQL-时区导致的时间前后端不一致
背景 今天早上刚上班,就被同事提示,程序的日期处理有问题.数据库里日期为:2019-05-21 11:00:00 而前端显示的日期为:2019-05-21 16:00:00 分析 那肯定是和时区相关了 ...
- k8s运维记 - 如何让部署到k8s的kong网关托管自定义静态资源?
目的 使用kong作为目录/data/reports的静态资源服务器,为了测试,已于目录/data/reports下创建文件report.html,如下: <html> <head& ...
- 从零开始入门 K8s | Kubernetes 网络概念及策略控制
作者 | 阿里巴巴高级技术专家 叶磊 一.Kubernetes 基本网络模型 本文来介绍一下 Kubernetes 对网络模型的一些想法.大家知道 Kubernetes 对于网络具体实现方案,没有什 ...
- SQL Server 2012企业版和标准版的区别
关于使用Microsoft SQL Server 数据库的公司一般会有疑问,企业版数据库和标准版数据库的区别在哪?如果采购企业版的价格和标准版的价格相差很大,从多方资料查询发现,我认为最主要的区别是硬 ...
- VUE--插值的操作
一.vue常见的指令 v-once:保留第一次渲染结果 v-html :把html代码解析,只显示内容 v-pre :原样输出 v-cloak :解决文本闪烁问题 v-text :显示文本 二.v-b ...
- 调用对象 “ha-datastoresystem”的“HostDatastoreSystem.QueryVmfsDatastoreCreateOptions” 失败。
VMware vSphere Client上显示:在 ESXi“10.10.10.3”上调用对象 “ha-datastoresystem”的“HostDatastoreSystem.QueryVmfs ...
- 用阿里官网提供的plupload oss的web直传,视频上传进行前端验证它的时长,尺寸,大小等。替换上一个不需要的单个视频
accessid = '' accesskey = '' host = '' policyBase64 = '' signature = '' callbackbody = '' filename = ...
- RF自定义库和关键字
1:在D:\work_software\python\Lib\site-packages 文件夹下, 新建python package文件夹 ,例如我的是TestLibrary 建好后的完整路径:D: ...