Spark 学习笔记之 aggregateByKey
aggregateByKey:
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession object TransformationsDemo {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder().appName("TransformationsDemo").master("local[1]").getOrCreate()
val sc = sparkSession.sparkContext
testAggregateByKey(sc) } private def testAggregateByKey(sc: SparkContext) = {
var data = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),1)
def seq(a:Int, b:Int) : Int ={
println("seq: " + a + "\t " + b)
math.max(a,b)
} def comb(a:Int, b:Int) : Int ={
println("comb: " + a + "\t " + b)
a + b
} data.aggregateByKey(0)(seq, comb).collect.foreach(println)
}
}
运行结果:
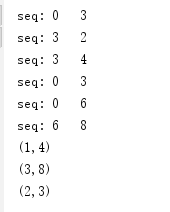
运行结果分析:
根据Key值的不同,可以分为3个组:
(1) (1,3),(1,2),(1,4);
(2) (2,3);
(3) (3,6),(3,8)。
这3个组分别进行seqOp,也就是(K,V)里面的V和0进行math.max()运算,运算结果和下一个V继续运算,以第一个组为例,运算过程是这样的:
0, 3 => 3
3, 2 => 3
3, 4 => 4
所以最终结果是(1,4)。
第二组结果是(2,3)。
第三组结果是(3,8)。
combOp是对把各分区的V加起来,由于这里并没有分区,所以实际上是不起作用的。
修改下代码,添加分区:
private def testAggregateByKey(sc: SparkContext) = {
var data = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3)
def seq(a:Int, b:Int) : Int ={
println("seq: " + a + "\t " + b)
math.max(a,b)
}
def comb(a:Int, b:Int) : Int ={
println("comb: " + a + "\t " + b)
a + b
}
data.aggregateByKey(0)(seq, comb).collect.foreach(println)
}
运行结果:

运行结果分析:
根据Key值的不同,可以分为3个区:
(1) (1,3),(1,2);
(2) (1,4),(2,3);
(3) (3,6),(3,8)。
区内先做求最大值
第一组结果是(1,3)。
第二组结果是(1,4),(2,3)。
第三组结果是(3,8)。
combOp是对把各分区的V加起来,由于此次有分区,所以(1,3)和(1,4),做合并操作,结果:(1, 7)。
Spark 学习笔记之 aggregateByKey的更多相关文章
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
随机推荐
- CodeForces 948B Primal Sport
Primal Sport 题意:2个人玩游戏, 每次轮到一个人选择一个比当前值小的素数, 然后在找到比素数的倍数中最小的并且不小于当前数的一个数. 现在这个游戏玩了2轮, 现在想找到最小的那个起点X0 ...
- Gym 101470 题解
A:Banks 代码: #include<bits/stdc++.h> using namespace std; #define Fopen freopen("_in.txt&q ...
- Gym 101964 题解
B:Broken Watch (别问,问就是队友写的) 代码: import java.awt.List; import java.io.BufferedInputStream; import jav ...
- Relatively Prime Graph CF1009D 暴力 思维
Relatively Prime Graph time limit per test 2 seconds memory limit per test 256 megabytes input stand ...
- Windows下安装youtube-dl(下载各大网站视频)
youtube-dl干什么用的? 惯例,看官方介绍: youtube-dl is a command-line program to download videos from YouTube.com ...
- 2019icpc南昌网络赛_I_Yukino With Subinterval
题意 给定一个序列,两种操作,单点修改,询问区间\([l,r]\)值域在\([x,y]\)范围内的连续段个数. 分析 原数组为\(a\),构造一个新的数组\(b\),\(b[i]=(a[i]==a[i ...
- Oracle 11g Rac 用rman实现把本地数据文件迁移到ASM共享存储中
在Oracle Rac环境中,数据文件都是要存放在ASM共享存储上的,这样两个节点才能同时访问.而当你在某一节点下把数据文件创建在本地磁盘的时候,那么在另一节点上要访问该数据文件的时候就会报错,因为找 ...
- c++调试在容器释放内存时报Unknown Signal 或 Trace/breakpoint trap异常
在做一道题时,用到的板子中出现了很多的容器的使用,,一开始都是开MAXN大小的容器,,但是有几率出现程序运行完后不正常退出,, 在多次尝试断点调试后,发现主要的异常是程序在结束时,要进行资源的释放,, ...
- 【LeetCode】55-跳跃游戏
题目描述 给定一个非负整数数组,你最初位于数组的第一个位置. 数组中的每个元素代表你在该位置可以跳跃的最大长度. 判断你是否能够到达最后一个位置. 示例 1: 输入: [2,3,1,1,4] 输出: ...
- Ubuntu系统添加用户权限
一.首先创建一个新用户: sudo adduser hadoop 其次设置密码: sudo passwd hadoop 如果无法使用root密码,请输入如下命令: sudo passwd root 二 ...