细谈Redis五大数据类型
文章原创于公众号:程序猿周先森。本平台不定时更新,喜欢我的文章,欢迎关注我的微信公众号。

上一篇文章有提到,Redis中使用最频繁的有5种数据类型:String、List、Hash、Set、SortSet。上一篇文章只是单纯介绍了下这5种数据类型使用到的指令以及常用场景,本篇文章会谈谈5种数据类型的底层数据结构以及各自常用的操作命令来分别进行解析。Redis作为目前最流行的Key-Value型内存数据库,不仅数据库操作在内存中进行,并且可定期的将数据持久化到磁盘中,所以性能相对普通数据库高很多,而在Redis中,每个Value实际上都是以一个redisObject结构来表示:
typedef struct redisObject{
unsigned type:4;
unsigned encoding:4;
void *ptr;
int refCount;
unsigned lru:
}
我们可以看看这几个参数分别的含义:
type:对象的数据类型,一般情况就是5大数据类型。
encode:redisObject对象底层编码实现,主要编码类型有简单动态字符串,链表,字典,跳跃表,整数集合及压缩列表。
*ptr:指向底层实现数据结构的指针。
refCount:计数器,当引用计数值为0将会释放对象。
lru:最后一次访问本对象的时间。
String数据类型
String 数据结构是简单的 Key-Value 类型,是Redis中最常用的一种数据类型,Value 可以是string或者数字。String数据类型实际上可以存储字符串、整数、浮点数三种不同类型的值,Redis是如何做到自动识别字符串、整数、浮点数三种不同类型的值。Redis是使用C实现的,但是并未使用C中的字符串,实际上Redis自己实现了一个结构体SDS来替代String类型:
struct sdshdr{
//记录buf数组中已使用字节的长度
int len;
//记录buf数组中剩余空间的长度
int free;
//字节数组,用于存储字符串
char buf[];
};
我们可以看到free参数是用来判断剩余可使用空间的长度,len表示字符串的长度,buf存储字符串的每一个字符以及结尾的'\0'。为什么Redis要自己实现SDS结构体呢?因为SDS结构体有几个优点:
由于len保存了当前字符串的实际长度,所以获取长度时间复杂度为O(1)。
SDS在拼接之前会对当前字符串的空间进行自动调整和扩展,防止当前字符串数据溢出。
减少内存分配次数,SDS拼接字符串发生时,如果此时的字符串长度len小于1M,则SDS会分配和len大小相同的未使用空间给free,如果此时的字符串长度len大于1M,则SDS会分配和1M的未使用空间给free,当字符串缩短时,缩短的空间会叠加到free中,用于后续的拼接使用。
String数据类型常用命令:
- 常用命令:set、get、decr、incr、mget 等。
String数据类型适用场景:
分布式锁
分布式session:将分布式应用session存储到Redis中
商品秒杀
常规计数:博客数,阅读数
List数据类型
List数据结构是用来存储多个有序的字符串,List中的每个字符串成为元素,List提供了节点重排和节点顺序访问的能力,在Redis中,List可以在两端push和pop元素,还可以获取指定范围的元素列表,获取指定索引下标的元素等,List数据结构主要有zipList(压缩链表)和LinkedList(双向链表)两种实现方式。首先我们可以先看看LinkedList的结构:
type struct list{
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//包含的节点总数
unsigned long len;
};
可以看到每个LinkedList中都会包含一个表头节点head和一个表尾结点tail,在LinkedList中每个节点都会有一个prev指向前一个元素,同时还有一个next指向后一个元素,每个节点的value就是节点的值。从而实现双向链表,理解起来实际上和C中的双向链表有很大程度的相似性。而另一种实现方式zipList是基于连续内存实现,有点类似于数组方式,但是和数组有点不一致的是zipList的每一个entry的大小可能不一致,需要特殊方法去控制解决,但是在执行push,pop操作时会有数据的迁移,时间复杂度为O(n), 所以一般只有在元素较少时才会使用zipList,我们可以看看zipList的结构:
type struct ziplist{
//整个压缩列表的字节数
uint32_t zlbytes;
//记录压缩列表尾节点到头结点的字节数,直接可以求节点的地址
uint32_t zltail_offset;
//记录了节点数,有多种类型,默认如下
uint16_t zllength;
//节点
List entryX;
}
zipList中每个节点都会有以下几个参数信息:
previous_entry_length:记录前一个节点的字节长度
content:节点所存储的内容,可以是一个字节数组或者整数
encoding:记录content属性中所保存的数据类型以及长度
*** List数据类型适用场景**
在渲染文章列表时可以使用List数据类型,一般情况下每个用户都会有自己发布的文章列表,如果需要展示文章列表,就可以使用List数据类型,不但可以有序而且可以按照索引范围去查询文章列表。
Set数据类型
Set数据类型和List数据类型有点类似,也可以用来保存多个元素,但最大的一点区别在于Set数据类型不允许出现重复的元素,并且Set中的元素是无序的,所以没办法和List一样通过索引下标获取元素,但是Set类型支持多个Set集合取交集、并集、差集,所以合理使用Set数据类型,可以在实际项目开发中解决很多问题。Set数据类型有两种数据结构:IntSet和HashTable。首先我们来看看IntSet的结构:
typedef struct intset {
// 编码方式
uint32_t enconding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
当Set集合中所有元素都为整型时,Redis才会使用IntSet数据结构。有一点需要格外注意的是:IntSet数据结构是有序的。因为为了减轻性能的消耗,Redis在Set集合元素都为整型时,会使用一种基于动态数组的结构体,同时在push元素的时候控制元素的大小顺序,这样就可以使用二分查找算法来对元素进行push及pop操作,这样时间复杂度仅为O(logN)。在Set集合中元素存在非整型数据时,Redis这时会自动采用HashTable数据结构来存放数据,在HashTable中,存放的只有key值而没有value值,所以说在HashTable中,键值永远为null。我们可以看下HashTable的结构:
typedef struct dict{
//类型特定函数
dictType *type;
//哈希表 两个,一个用于实时存储,一个用于rehash
dictht ht[2];
//rehash索引 数据迁移时使用
unsigned rehashidx;
}
Set数据类型使用场景:
记录唯一值:比如登录ip,身份证号
添加标签:可以通过标签的交并集计算用户喜好程度等数据。
Hash数据类型
在Redis中哈希类型是指键本身又是一种键值对结构,也就是我们所说的对象,所以Hash数据类型用来存储对象是最合适的数据类型。Hash数据类型的编码可以是zipList或HashTable。当哈希对象保存的所有键值对长度小于64字节并且元素数量少于512时使用zipList,否则使用HashTable。zipList与刚才List数据类型中讲到的zipList实际上基本一致,唯一区别在于Hash存储entry数量成对增加,所以长度一定为2的整数倍。当然,使用zipList刚才已经说过push和pop时间复杂度为O(n),所以只能在数据量少的情况下才允许使用。而HashTable其实有点类似于Java中的HashTable,HashTTable主要依赖于三个结构:dict、dictht、entry。三个结构的关系可以表示为如下这幅图:
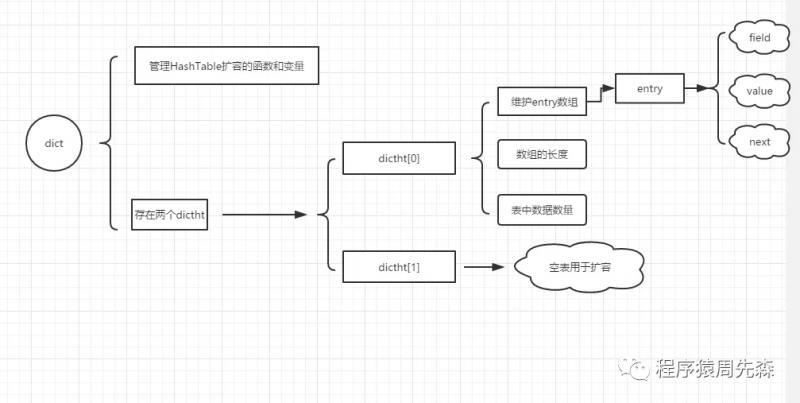
Hash数据类型适用场景:
存储对象数据。
结合Json描述对象集合。
SortSet数据类型
有序集合是在Set集合的基础上,保留了Set集合中不能存在重复元素的特性,但是不同的是,SortSet集合中元素是可以排序的,SortSet排序和List排序都可以使用索引下标作为排序依据,所以说SortSet实现了数据有序且键值对唯一的集合,SortSet的数据结构有两种:zipList和skipList + HashTable,zipList都不用多少了,是用于数据量较少的情况,默认排序为元素从小到大。而采用skipList + HashTable的数据结构,skipList会在保证集合有序的情况下优化范围查找的时间复杂性,而HashTable刚才已经提到过它可以优化push和pop元素时的时间复杂性。skipList基于有序链表,可以创建多层索引,实现以空间复杂度来换取时间复杂度的做法,最终实现时间复杂度为O(logN)的元素查询过程,当需要push或者pop元素时,则使用HashTable实现时间复杂度仅为O(1).
SortSet数据类型适用场景
积分排行榜:根据积分排序从小到大
获取某个范围的数据:考试80-100分的数据
欢迎关注公众号:程序员周先森
细谈Redis五大数据类型的更多相关文章
- Redis五大数据类型的常用操作
在上一篇博文<centos安装redis>中,已经详细介绍了如何在centos上安装redis,今天主要介绍下Redis五大数据类型及其五大数据类型的相关操作. Redis支持五种数据类型 ...
- 一文搞定Redis五大数据类型及应用场景
本文学习知识点 redis五大数据类型数据类型:string.hash.list.set.sorted_set 五大类型各自的应用场景 @TOC 1. string类型 1-1 string类型数据的 ...
- redis 五大数据类型使用
redis 五大数据类型使用 字符串str 单个值 127.0.0.1:6379> set name pp # 设置键值[O(1)] OK 127.0.0.1:6379> setex na ...
- 《Redis入门指南(第二版)》读书思考总结之Redis五大数据类型
热身:系统级命令 1. 获得符合规则的键名列表 KEYS pattern 模式匹配 产品的缓存:product+"."+....; => keys product* 订单的 ...
- Redis五大数据类型详解
关于Redis的五大数据类型,它们分别为:String.List.Hash.Set.SortSet.本文将会从它的底层数据结构.常用操作命令.一些特点和实际应用这几个方面进行解析.对于数据结构的解析, ...
- redis五大数据类型以及常用操作命令
Redis的五大数据类型 String(字符串) string是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value.string类型是二进制安全的.意 ...
- 四:Redis五大数据类型
Redis的五大数据类型 1.string(字符串) string是Redis最基本的类型,你可以理解成与menmcached一模一样的类型,一个key对应一个value string类型是二进制安全 ...
- Redis五大数据类型
首先说明下,Redis是:单线程+多路IO复用技术!!! string set > key + zset list hash 常用的几个命令: >keys * 查 ...
- 【转】细谈Redis和Memcached的区别
Redis的作者Salvatore Sanfilippo曾经对这两种基于内存的数据存储系统进行过比较: Redis支持服务器端的数据操作:Redis相比Memcached来说,拥有更多的数据结构和并支 ...
随机推荐
- 【模板】树链剖分(Luogu P3384)
题目描述 众所周知 树链剖分是个好东西QWQ 也是一个代码量破百的算法 基本定义 树路径信息维护算法. 将一棵树划分成若干条链,用数据结构去维护每条链,复杂度为O(logN). 其实本质是一些数据结 ...
- Git安装与使用(windows环境)(一)----Git安装、生成公钥和私钥、添加SSH
安装 1.从官网下载git:http://git-scm.com/downloads 2.安装git,选择git组件安装,如下图 3.一直next,直到出现下面的窗口.这里是选择命令行形式.(可以理解 ...
- Java 操作Word书签(二):添加文本、图片、表格到书签内容
在Java操作Word书签(一)中介绍了给Word中的特定段落或文字添加书签.读取及删除已有书签的方法,本文将继续介绍Java 操作Word书签的方法,即如何给已有的书签添加内容,包括添加文本.图片. ...
- ArcMap和ArcGIS Pro加载百度地图
前面发布了两篇我用ArcBruTile开发用于ArcMap加载百度地图的插件ArcBruTileBaidu,放在网上后评论和反响还不错,还有两位大学同学通过百度搜索居然搜到我本人!文章和技术介绍也被网 ...
- unity编辑器扩展_06(给选项添加快捷键,控制菜单是否启用)
代码: [MenuItem("Tools/Delete ", true, 1)] static bool DeleteVadidate() { if (S ...
- 栅格数据的批量镶嵌(附Python脚本)
栅格数据的批量镶嵌(附Python脚本) 博客小序:在数据处理的过程中,会遇到需要大量镶嵌的情况,当数据较多时手动镶嵌较为麻烦,自己最近对分省的DEM数据进行镶嵌,由于利用python进行镶嵌较为方便 ...
- Python之流程控制——while循环
Python之流程控制--while循环 一.语法 while 条件: 执行代码 while就是当的意思,它指当其后面的条件成立,就执行while下面的代码. 例:写一个从0打印到10的程序 coun ...
- 解决org.apache.ibatis.binding.BindingException: Invalid bound statement (not found): com.xyfer.dao.UserDao.findById
在使用Spring整合MyBatis的时候遇到控制台报错:org.apache.ibatis.binding.BindingException: Invalid bound statement (no ...
- [Error]syntaxerror: non-ascii character '/xd6' in file
eclipse代码运行时显示:syntaxerror: non-ascii character '/xd6' in file 原因:如果文件里有非ASCII字符,需要在第一行或第二行指定编码声明. 解 ...
- 2019 Multi-University Training Contest 2
2019 Multi-University Training Contest 2 A. Another Chess Problem B. Beauty Of Unimodal Sequence 题意 ...