深度学习常见的优化方法(Optimizer)总结:Adam,SGD,Momentum,AdaGard等
机器学习的常见优化方法在最近的学习中经常遇到,但是还是不够精通.将自己的学习记录下来,以备不时之需
基础知识:
机器学习几乎所有的算法都要利用损失函数 lossfunction 来检验算法模型的优劣,同时利用损失函数来提升算法模型.
这个提升的过程就叫做优化(Optimizer)
下面这个内容主要就是介绍可以用来优化损失函数的常用方法
常用的优化方法(Optimizer):
1.SGD&BGD&Mini-BGD:
SGD(stochastic gradient descent):随机梯度下降,算法在每读入一个数据都会立刻计算loss function的梯度来update参数.假设loss function为L(w),下同.\[w-=\eta \bigtriangledown_{w_{i}}L(w_{i}) \]
Pros:收敛的速度快;可以实现在线更新;能够跳出局部最优
Cons:很容易陷入到局部最优,困在马鞍点.
BGD(batch gradient descent):批量梯度下降,算法在读取整个数据集后累加来计算损失函数的的梯度
\[w-=\eta \bigtriangledown_{w}L(w)\]
Pros:如果loss function为convex,则基本可以找到全局最优解
Cons:数据处理量大,导致梯度下降慢;不能实时增加实例,在线更新;训练占内存
Mini-BGD(mini-batch gradient descent):顾名思义,选择小批量数据进行梯度下降,这是一个折中的方法.采用训练集的子集(mini-batch)来计算loss function的梯度.\[w-=\eta \bigtriangledown_{w_{i:i+n}}L(w_{i:i+n})\]
这个优化方法用的也是比较多的,计算效率高而且收敛稳定,是现在深度学习的主流方法.上面的方法都存在一个问题,就是update更新的方向完全依赖于计算出来的梯度.很容易陷入局部最优的马鞍点.能不能改变其走向,又保证原来的梯度方向.就像向量变换一样,我们模拟物理中物体流动的动量概念(惯性).引入Momentum的概念.
- 2.Momentum
在更新方向的时候保留之前的方向,增加稳定性而且还有摆脱局部最优的能力\[\Delta w=\alpha \Delta w- \eta \bigtriangledown L(w)\] \[w=w+\Delta w\]
若当前梯度的方向与历史梯度一致(表明当前样本不太可能为异常点),则会增强这个方向的梯度,若当前梯度与历史梯方向不一致,则梯度会衰减。一种形象的解释是:我们把一个球推下山,球在下坡时积聚动量,在途中变得越来越快,\(\eta\)可视为空气阻力,若球的方向发生变化,则动量会衰减。 - 3.Adagrad:(adaptive gradient)自适应梯度算法,是一种改进的随机梯度下降算法.
以前的算法中,每一个参数都使用相同的学习率\(\alpha\). Adagrad算法能够在训练中自动对learning_rate进行调整,出现频率较低参数采用较大的\(\alpha\)更新.出现频率较高的参数采用较小的\(\alpha\)更新.根据描述这个优化方法很适合处理稀疏数据.\[G=\sum ^{t}_{\tau=1}g_{\tau} g_{\tau}^{T} 其中 s.t. g_{\tau}=\bigtriangledown L(w_{i})\] 对角线矩阵\[G_{j,j}=\sum _{\tau=1}^{t} g_{\tau,j\cdot}^{2}\] 这个对角线矩阵的元素代表的是参数的出现频率.每个参数的更新\[w_{j}=w_{j}-\frac{\eta}{\sqrt{G_{j,j}}}g_{j}\] - 4.RMSprop:(root mean square propagation)也是一种自适应学习率方法.不同之处在于,Adagrad会累加之前所有的梯度平方,RMProp仅仅是计算对应的平均值.可以缓解Adagrad算法学习率下降较快的问题.\[v(w,t)=\gamma v(w,t-1)+(1-\gamma)(\bigtriangledown L(w_{i}))^{2} ,其中 \gamma 是遗忘因子\] 参数更新\[w=w-\frac{\eta}{\sqrt{v(w,t)}}\bigtriangledown L(w_{i})\]
5.Adam:(adaptive moment estimation)是对RMSProp优化器的更新.利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率.
优点:每一次迭代学习率都有一个明确的范围,使得参数变化很平稳.
\[m_{w}^{t+1}=\beta_{1}m_{w}^{t}+(1-\beta_{1}) \bigtriangledown L^{t} ,m为一阶矩估计\]
\[v_{w}^{t+1}=\beta_{2}m_{w}^{t}+(1-\beta_{2}) (\bigtriangledown L^{t})^{2},v为二阶矩估计\]
\[\hat{m}_{w}=\frac{m_{w}^{t+1}}{1-\beta_{1}^{t+1}},估计校正,实现无偏估计\]
\[\hat{v}_{w}=\frac{v_{w}^{t+1}}{1-\beta_{2}^{t+1}}\]
\[w^{t+1} \leftarrow=w^{t}-\eta \frac{\hat{m}_{w}}{\sqrt{\hat{v}_{w}}+\epsilon}\]
Adam是实际学习中最常用的算法
优化方法在实际中的直观体验
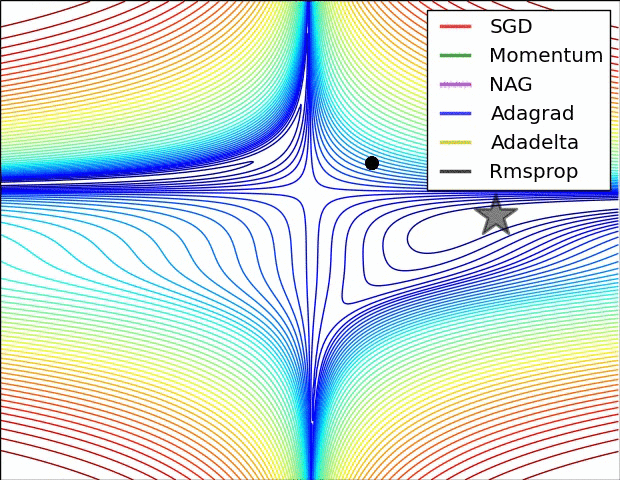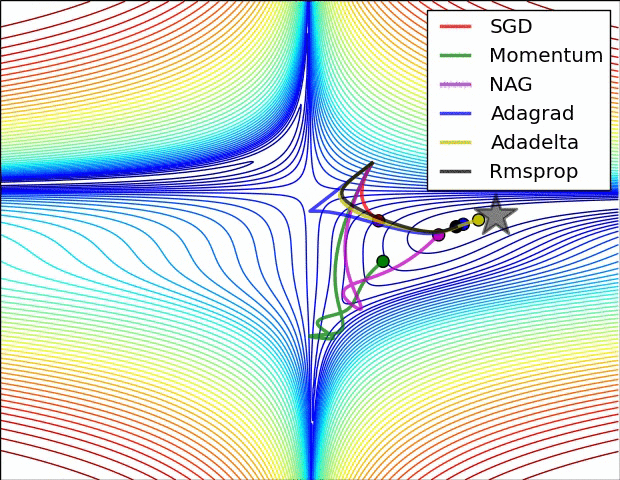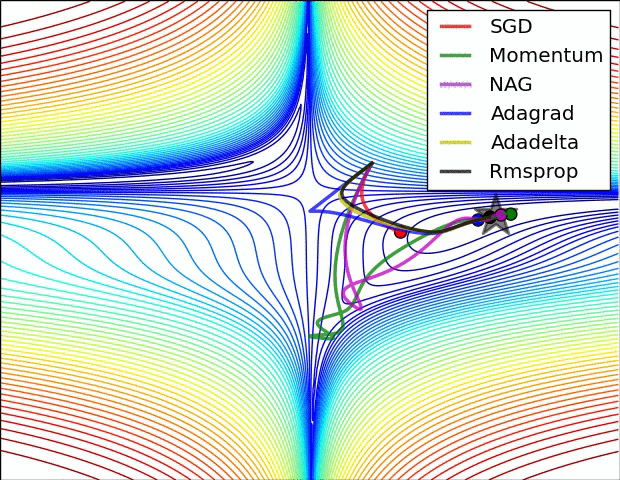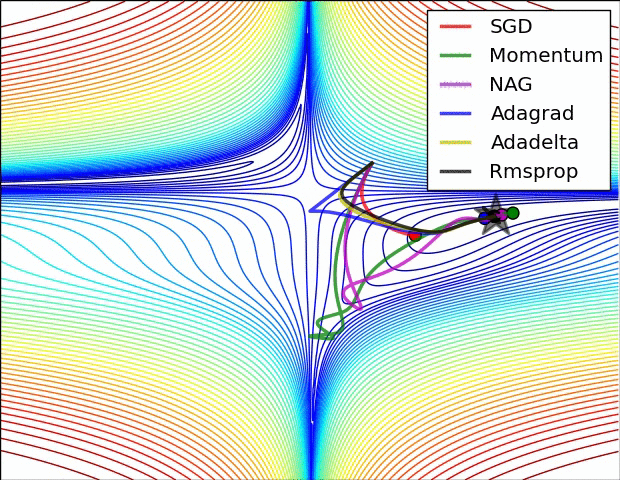
损失曲面的轮廓和不同优化算法的时间演化。 注意基于动量的方法的“过冲”行为,这使得优化看起来像一个滚下山的球
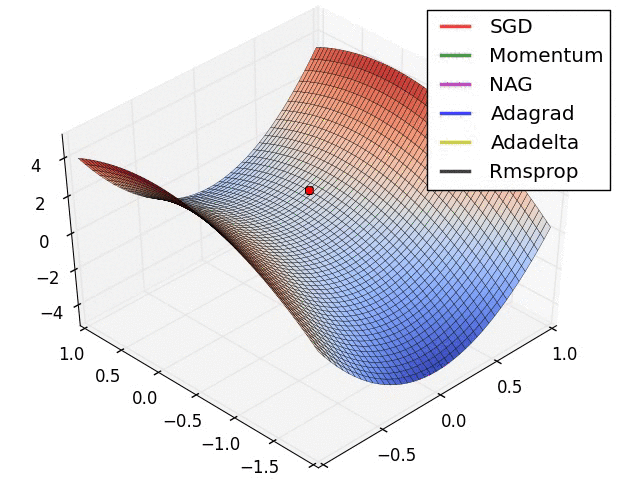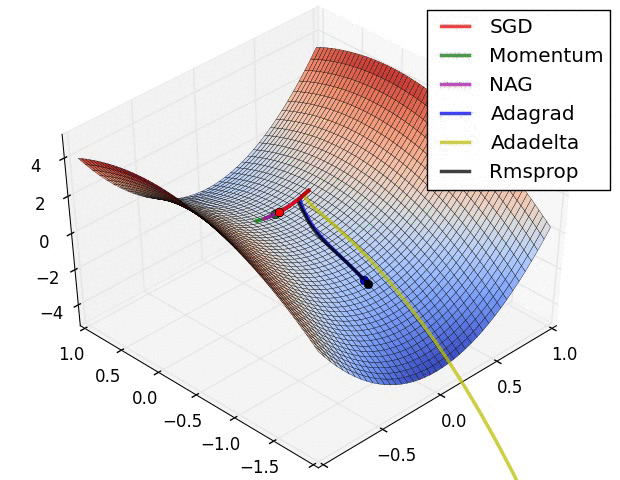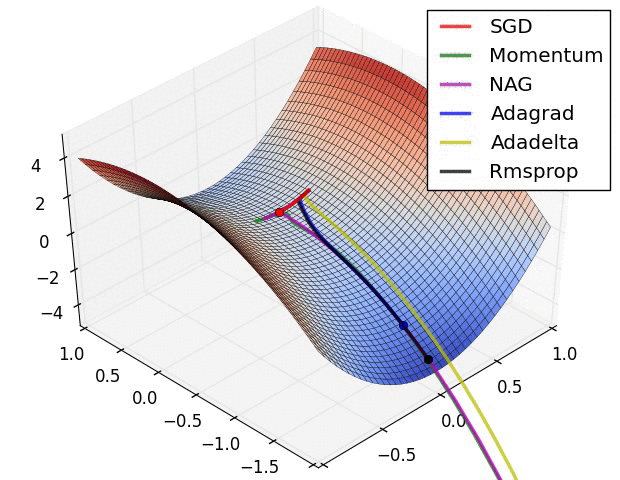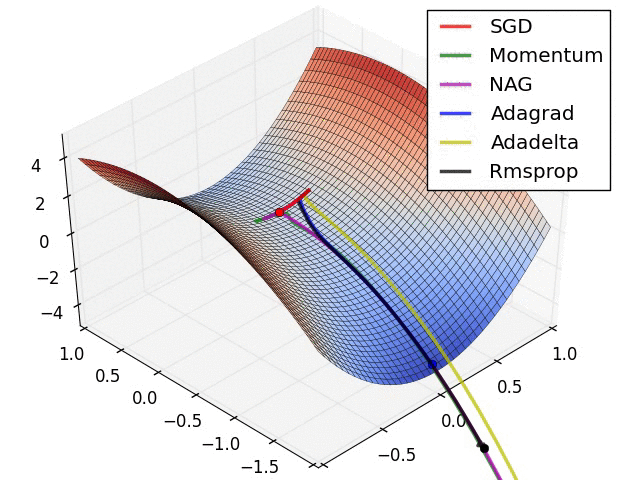
优化环境中鞍点的可视化,其中沿不同维度的曲率具有不同的符号(一维向上弯曲,另一维向下)。 请注意,SGD很难打破对称性并陷入困境。 相反,诸如RMSprop之类的算法将在鞍座方向上看到非常低的梯度。 由于RMSprop更新中的分母术语,这将提高此方向的有效学习率,从而帮助RMSProp继续进行.
参考文献:
深度学习常见的优化方法(Optimizer)总结:Adam,SGD,Momentum,AdaGard等的更多相关文章
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 ...
- 各种优化方法总结比较(sgd/momentum/Nesterov/adagrad/adadelta)
前言 这里讨论的优化问题指的是,给定目标函数f(x),我们需要找到一组参数x,使得f(x)的值最小. 本文以下内容假设读者已经了解机器学习基本知识,和梯度下降的原理. SGD SGD指stochast ...
- 深度学习编译与优化Deep Learning Compiler and Optimizer
深度学习编译与优化Deep Learning Compiler and Optimizer
- 基于NVIDIA GPUs的深度学习训练新优化
基于NVIDIA GPUs的深度学习训练新优化 New Optimizations To Accelerate Deep Learning Training on NVIDIA GPUs 不同行业采用 ...
- Android中ListView的几种常见的优化方法
Android中的ListView应该算是布局中几种最常用的组件之一了,使用也十分方便,下面将介绍ListView几种比较常见的优化方法: 首先我们给出一个没有任何优化的Listview的Adapte ...
- 优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam)
优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam) 2019年05月29日 01:07:50 糖葫芦君 阅读数 455更多 ...
- 深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)(转)
转自: https://zhuanlan.zhihu.com/p/22252270 ycszen 另可参考: https://blog.csdn.net/llx1990rl/article/de ...
- 机器学习优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
SGD: 此处的SGD指mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mi ...
- 几种优化方法的整理(SGD,Adagrad,Adadelta,Adam)
参考自: https://zhuanlan.zhihu.com/p/22252270 常见的优化方法有如下几种:SGD,Adagrad,Adadelta,Adam,Adamax,Nadam 1. SG ...
随机推荐
- angular6组件封装以及发布到npm
一.创建angular项目 ng new myFirstDemo //angular-cli新建项目ng g m testm //新建模块ng g c testm/headertest //新建组件 ...
- 从源码看java线程状态
关于java线程状态,网上查资料很混乱,有的说5种状态,有的说6种状态,初学者搞不清楚这个线程状态到底是怎么样的,今天我讲一下如何看源码去解决这个疑惑. 直接上代码: public class Thr ...
- JavaSE(一)Java程序的三个基本规则-组织形式,编译运行,命名规则
一.Java程序的组织形式 Java程序是一种纯粹的面向对象的程序设计语言,因此Java程序必须以类(class)的形式存在,类(class)是Java程序的最小程序单位. J ...
- RabbitMQ与spring集成,配置完整的生产者和消费者
RabbitMQ与AMQP协议详解可以看看这个 http://www.cnblogs.com/frankyou/p/5283539.html 下面是rabbitMQ和spring集成的配置,我配置了二 ...
- 10分钟了解一致性hash算法
应用场景 当我们的数据表超过500万条或更多时,我们就会考虑到采用分库分表:当我们的系统使用了一台缓存服务器还是不能满足的时候,我们会使用多台缓存服务器,那我们如何去访问背后的库表或缓存服务器呢,我们 ...
- Unity经典游戏编程之:球球大作战
版权声明: 本文原创发布于博客园"优梦创客"的博客空间(网址:http://www.cnblogs.com/raymondking123/)以及微信公众号"优梦创客&qu ...
- Spring cloud Feign不支持对象传参解决办法[完美解决]
spring cloud 使用 Feign 进行服务调用时,不支持对象参数. 通常解决方法是,要么把对象每一个参数平行展开,并使用 @RequestParam 标识出每一个参数,要么用 @Reques ...
- 《HTTP权威指南》--阅读笔记(一)
HTTP: HyperText Transfer Protocol 测试站点:http://www.joes-hardware.com URI包括URL和URN URI: Uniform Resour ...
- c# 三步递交模式调用同一个存储过程
主要用于批量的sql操作:第一步创建中间表,第二步多次写数据到中间表,第三步 提交执行 创建三步递交的存储过程: CREATE PROC usp_testsbdj@bz int=0,@name VAR ...
- AOSP 预置 APP
Android 系统预置 APP 是做 Framework 应用开发经常经常会遇到的工作,预置 APP 分为两种,一种是直接预置 APK,一种是预置带有源码的 APP. 预置 apk 示例说明 以 . ...