相克军_Oracle体系_随堂笔记004-shared pool
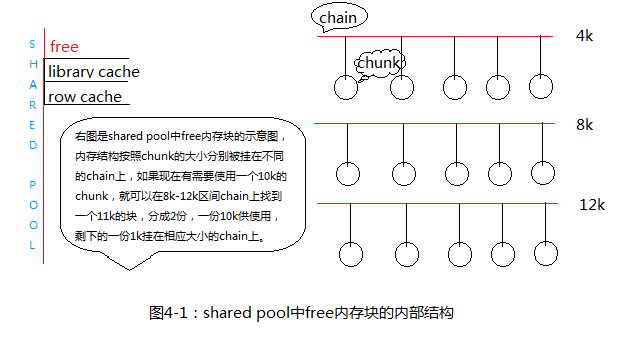
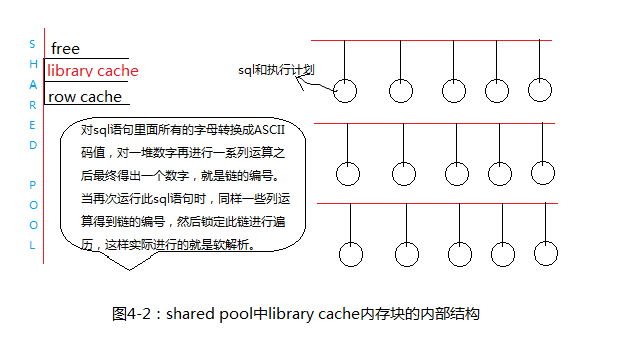
select count(*) from x$ksmsp;
select name, value
from v$sysstat
where name like 'parse%';
alter system flush shared_pool;
declare v_sql varchar2(50);
begin for i in 1..10000 loop
v_sql := 'insert /*jingyu*/ into test values(:1)';
execute immediate v_sql using i;
end loop;
commit;
end;
show parameter cursor
alter system set cursor_sharing='force';
select sql_fulltext
from v$sql
where executions=1
order by sql_text;
select sum(pinhits)/sum(pins)*100
from v$librarycache;
select sum(gets), sum(getmisses), 100*sum(gets-getmisses)/sum(gets)
from v$rowcache;
select * from table(dbms_xplan.display_cursor('g4pkmrqrgxg3b'));
select request_misses from v$shared_pool_reserved;
select component, current_size from v$sga_dynamic_components;
show parameter sga_target
show parameter sga_max_size
alter system set shared_pool_size=150M scope=both;
相克军_Oracle体系_随堂笔记004-shared pool的更多相关文章
- 相克军_Oracle体系_随堂笔记002-基础
1.常见的Oracle生产库环境: 图2-1可以说是标准的生产库环境,处处体现了冗余,有效防止了单点故障.这就是HA(高可用) 而且冗在某种条件下还可以去掉,平常实现同时运行提供服务,如果一台坏掉,另 ...
- 相克军_Oracle体系_随堂笔记001-概述
一.Oracle官方支持 1.在线官方文档 http://docs.oracle.com/ 2.metalink.oracle.com,如今已经改成:http://support.oracle.com ...
- 相克军_Oracle体系_随堂笔记003-体系概述
1.进程结构图 对Oracle生产库来讲,服务器进程(可以简单理解是前台进程)的数量远远大于后台进程.因为一个用户进程对应了一个服务器进程. 而且后台进程一般出问题几率不大,所以学习重点也是服务器进程 ...
- 相克军_Oracle体系_随堂笔记005-Database buffer cache
本章主要阐述SGA中的Database buffer cache. Buffer cache { 1.pin (读写瞬间的状态) 2.clean 3.dirty 4.unused } --Databa ...
- 相克军_Oracle体系_随堂笔记006-日志原理
简单来说,学习Oracle数据库就两个目标: 保证数据库数据的一致性: 提高数据库的性能(这个和日志没关系). 日志的功能: 只是保证数据库数据的一致性: 1.Oracle日志原理 ...
- 相克军_Oracle体系_随堂笔记007-PGA
实际工作中,Oracle中有两个很重要:Server Process 和 PGA. PGA内存作用和构成 1.PGA作用 2.PGA构成 1)private SQL area 2)Sess ...
- 相克军_Oracle体系_随堂笔记008-存储结构
控制文件.数据文件.日志文件 放在存储上. 参数文件:数据库启动时读取,并不关闭,但是启动过后丢了也没事.一般放在服务器上. $ORACLE_HOME/dbs下 备份文件{ 控制 ...
- 相克军_Oracle体系_随堂笔记009-检查点队列
1.检查点队列 checkpoint queue RBA 日志块地址 redo block address LRBA 第一次被脏的地址 HRBA 最近一次被脏的地址 on disk rba 重做日志( ...
- 相克军_Oracle体系_随堂笔记010-SCN
1.SCN的意义?system change number 时间 先后.新旧 select dbms_flashback.get_system_change_number, SCN_TO ...
随机推荐
- [LintCode] Product of Array Except Self 除本身之外的数组之积
Given an integers array A. Define B[i] = A[0] * ... * A[i-1] * A[i+1] * ... * A[n-1], calculate B WI ...
- Ubuntu下安装mod_python报错(GIT错误)
Ubuntu下安装mod_python3.4.1版本报出如下错误: writing byte-compilation script '/tmp/tmpE91VXZ.py' /usr/bin/pytho ...
- 在服务器上启用HTTPS的详细教程
现在,你应该能在访问https://konklone.com的时候,在地址栏里看到一个漂亮的小绿锁了,因为我把这个网站换成了HTTPS协议.一分钱没花就搞定了. 为什么要使用HTTPS协议: 虽然SS ...
- EF 连接sql2000
正常连接会提示版本低 可以先用ef连接高版本的sql然后新建好EDMX文件后,在右键xml方式打开,把ProviderManifestToken="2008" 改为2000 然后再 ...
- 学习笔记:因为java匿名类学习到接口的一些小用法
在看CometD的示例代码时发现了许多有意思的代码,但说实话看别人的代码确实是件很累的事情,所以就看到这个知识点做一下记录吧. 先看一段代码: 代码1 这段代码中有一个new的操作,而且是在方 ...
- Replication的犄角旮旯(三)--聊聊@bitmap
<Replication的犄角旮旯>系列导读 Replication的犄角旮旯(一)--变更订阅端表名的应用场景 Replication的犄角旮旯(二)--寻找订阅端丢失的记录 Repli ...
- 我的Git手册
本文肯定不是Git的最佳的教程,它只是本人的Git操作手册,我将从一些实际问题出发,让熟悉SVN用户顺利过度到Git来(当然包括我自己了),其中会加入一些个人感受或看法,相信会对大家有些启发.另外,全 ...
- 【效率】专为Win7系统设计的极简番茄计时器 - MiniPomodoro (附源码)
时光飞逝,一转眼坚持使用番茄工作法已经快3年了!能坚持这么长时间,主要还是得益于它的简单.但是令人纠结的是,这么长时间以来,换了7款不同的番茄计时器,仍然没有找到非常满意的: ■ 机械的噪音太大,会妨 ...
- 小型单文件NoSQL数据库SharpFileDB初步实现
小型单文件NoSQL数据库SharpFileDB初步实现 我不是数据库方面的专家,不过还是想做一个小型的数据库,算是一种通过mission impossible进行学习锻炼的方式.我知道这是自不量力, ...
- Windows Azure Storage (19) 再谈Azure Block Blob和Page Blob
<Windows Azure Platform 系列文章目录> 请读者在参考本文之前,预习相关背景知识:Windows Azure Storage (1) Windows Azure St ...