【MySQL】(二)InnoDB存储引擎
InnoDB是事务安全的MySQL存储引擎,设计上采用了类似于Oracel数据库的架构。通常来说,InnoDB存储引擎是OLTP应用中核心表的首选存储引擎。同时,也正是因为InnoDB的存在,才使MySQL数据库变得更有魅力。本文将介绍InnoDB存储引擎的体系架构及其不同于其他存储引擎的特性。
2.1、InnoDB 存储引擎概述
该引擎是第一个完整支持ACID事务的MySQL引擎,其特点是行锁设计、支持MVCC、支持外键、提供一致性非锁定读,同时被设计用来最有效的利用以及使用内存和CPU。
2.2、InnoDB 体系架构
从下图可见,InnoDB存储引擎有多个内存块,可以认为这些内存块组成了一个大的内存池,负责如下工作:
- 维护所有进程/线程需要访问的多个内部数据结构
- 缓存磁盘上的数据,方便快速地读取,同时在对磁盘文件的数据修改之前在这里缓存
- 重做日志(redo log)缓冲
后台线程的主要作用是负责刷新内存池中的数据,保证缓冲池中的内存缓存的是最近的数据。此外将已修改的数据文件刷新到磁盘文件,同时保证在数据库发生异常的情况下InnoDB能恢复到正常运行状态。
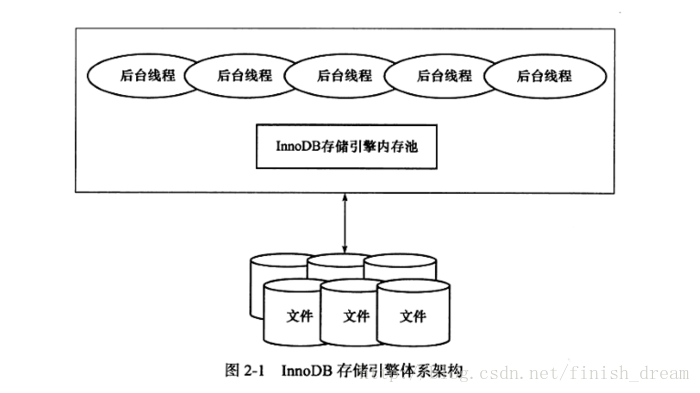
2.2.1、后台线程
InnoDB存储引擎是多线程的模型,因此气候态有多个不同的后台线程,负责处理不同的任务。
1.Master Thread
Master Thread是非常核心的后台线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新、合并插入缓冲、UNDO页的回收等。
2.IO Thread
在InnoDB存储引擎中大量使用了AIO(Async IO)来处理写IO请求,这样可以极大提高数据库的性能。而IO Thread的工作主要是负责这些IO请求的回调(call back)处理。
3.Purge Thread
事务被提交后,其所使用的undolog可能不再需要,因此需要PurgeThread来回收已经使用并分配的undo页。
4.Page Cleaner Thread
将脏页的刷新操作都放入到单独的线程中来完成。而七亩地是为了减轻原master Thread的工作及对于用户查询线程的阻塞,进一步提高InnoDb存储引擎的性能。
2.2.2、内存
1、缓冲池
InnoDB存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理。因此可将其视为基于磁盘的数据库系统。在数据库系统中,由于CPU速度与磁盘速度之间的鸿沟,基于磁盘的数据库系统通常使用缓冲池技术来提高数据库的整体性能。
缓冲池简单来说就是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库性能的影响。在数据库中进行读取页的操作,首先将从磁盘读到的页放在缓冲池中,这个过程称为将页“FIX”在缓冲池中。下一次再读取相同的页时,首先判断该页是否在缓冲池中。若在缓冲池中,称该页在缓冲池中被命中,直接读取该页。否则,读取磁盘上的页。
对于数据库中页的修改操作,则首先修改在缓冲池中的页,然后再以一定的频率刷新到磁盘上。需要注意的是,页从缓冲池刷新回磁盘的操作并不是在每次页发生更新时触发,而是通过一种称为Checkpoint的机制刷新回磁盘。同样,这也是为了提高数据库整体性能。
综上所述,缓冲池大小直接影响着数据库的整体性能。
2、LRU List
这段主要介绍InnoDB存储引擎怎么对缓冲池进行内存管理的。
在InnoDB存储引擎中同样适用LRU算法对缓冲池进行管理。稍有不同的是InnoDB存储引擎对传统的LRU算法做了一些优化在InnoDB的存储引擎中,LRU列表还加入了midpoint位置。新读取到的页,虽然是最新访问的页,但并不是直接放入到LRU列表的首部,而是放入到LRU列表的mindpoint位置。这个算法在InnoDB存储引擎下被称为mindpoint insertion strategy。在默认配置下,该位置在LRU列表长度的5/8处。
3、重做日志缓冲
InnoDB存储引擎的内存区除了有缓冲区外,还有重做日志缓冲。InnoDB存储引擎首先将重做日志信息放入到这个缓冲区,然后按一定平率将其刷新到重做日志文件。重做日志缓冲一般不需要设置得很大,因为一般情况下每一秒会将重做日志缓冲刷新到日志文件,因此用户只需保证每秒产生的事务量在这个缓冲大小之内即可。
4、额外的内存池
在对一些数据结构本身进行内存分配时,需要从额外的内存池中进行申请,当该区域的内存不够使,会从缓冲池中进行申请。
2.3、Checkpoint技术
前面已经讲到了,缓冲池的设计目的为了协调CPU与磁盘速度的鸿沟。因此页的操作首先都是在缓冲池中完成的。如果一条DML(数据操作语言)语句,如Update或Delete改变了页中的记录,那么此时页时脏的,即缓冲池中页的版本要比磁盘的新。数据库需要将新的版本的页从缓冲池刷新到磁盘。
倘若每一次一个页发生变化,就将新页的版本刷新到磁盘,那么这个开销是非常大的。若热点数据集中在某几个页中,那么数据库的性能将变得非常差。同时,如果在从缓冲池将页的新版本刷新到磁盘时发生宕机,那么数据就不能恢复了。为了避免发生数据丢失的问题,当前事务数据库系统普遍都采用Write Ahead Log策略,即当事务提交时,先写重做日志,再修改页。当由于发生宕机而导致数据丢失时,通过重做日志来完成数据的恢复。这也是事务ACID中D(Durability持久性)的要求。
Checkpoint(检查点)技术的目的是解决以下几个问题:
- 缩短数据库的恢复时间;
- 缓冲池不够用时,将脏页刷新到磁盘;
- 重做日志不可用时,刷新脏页;
当数据库发生宕机时,数据库不需要重做所有的日志,因为Checkpoint之前的页都已经刷新回磁盘。故数据库只需对Checkpoint后的重做日志进行恢复。这样就大大缩短了恢复时间。
此外,当缓冲池不够用时,根据LRU算法会溢出最近最少使用的页,此页即为脏页,那么需要强制执行Checkpoint,将脏页也就是页的最新版本刷新回磁盘。
在InnoDB存储引擎中,Checkpoint发生的时间、条件及脏页的选择等都非常复杂。而Checkpoint所做的事情无外乎是将缓冲池中的脏页刷回到磁盘。不同之处在于每次刷新多少页到磁盘,每次从哪里取脏页,以及什么时间触发Checkpoint。在InnoDB存储引擎内部,有两种Checkpoint,分别为:
- Sharp Checkpoint
- Fuzzy Checkpoint
Sharp Checkpoint 发生在数据库关闭时将所有的脏页都刷新回磁盘,这是默认的工作方式,及参数innodb_fast_shutdown=1。
但若是数据库在运行时也是用Sharp Checkpoint,那么数据的可用性就会受到很大的影响。故在InnoDB存储引擎内部使用Fuzzy Checkpoint进行页的刷新,即只刷新一部分脏页,而不是刷新所有的脏页。
【MySQL】(二)InnoDB存储引擎的更多相关文章
- MySQL数据库InnoDB存储引擎中的锁机制
MySQL数据库InnoDB存储引擎中的锁机制 http://www.uml.org.cn/sjjm/201205302.asp 00 – 基本概念 当并发事务同时访问一个资源的时候,有可能 ...
- MySQL数据库InnoDB存储引擎多版本控制(MVCC)实现原理分析
文/何登成 导读: 来自网易研究院的MySQL内核技术研究人何登成,把MySQL数据库InnoDB存储引擎的多版本控制(简称:MVCC)实现原理,做了深入的研究与详细的文字图表分析,方便大家理解I ...
- MySql中innodb存储引擎事务日志详解
分析下MySql中innodb存储引擎是如何通过日志来实现事务的? Mysql会最大程度的使用缓存机制来提高数据库的访问效率,但是万一数据库发生断电,因为缓存的数据没有写入磁盘,导致缓存在内存中的数据 ...
- MySQL数据库InnoDB存储引擎
MySQL数据库InnoDB存储引擎Log漫游 http://blog.163.com/zihuan_xuan/blog/static/1287942432012366293667/
- mysql中InnoDB存储引擎的行锁和表锁
Mysql的InnoDB存储引擎支持事务,默认是行锁.因为这个特性,所以数据库支持高并发,但是如果InnoDB更新数据的时候不是行锁,而是表锁的话,那么其并发性会大打折扣,而且也可能导致你的程序出错. ...
- mysql之innodb存储引擎
mysql之innodb存储引擎 innodb和myisam区别 1>.InnoDB支持事物,而MyISAM不支持事物 2>.InnoDB支持行级锁,而MyISAM支持表级锁 3>. ...
- MySQL:InnoDB存储引擎的B+树索引算法
很早之前,就从学校的图书馆借了MySQL技术内幕,InnoDB存储引擎这本书,但一直草草阅读,做的笔记也有些凌乱,趁着现在大四了,课程稍微少了一点,整理一下笔记,按照专题写一些,加深一下印象,不枉读了 ...
- mysql之innodb存储引擎---数据存储结构
一.背景 1.1文件组织架构 首先看一下mysql数据系统涉及到的文件组织架构,如下图所示: msyql文件组织架构图 从图看出: 1.日志文件:slow.log(慢日志),error.log(错误日 ...
- mysql之innodb存储引擎---BTREE索引实现
在阅读本篇文章可能需要一些B树和B+树的基础 一.B树和B+树的区别 1.B树的键值不会出现多次,而B+树的键值一定会出现在叶子节点上,而且在非叶子节点也可能会重复出现2.B数存储真实数据,B+数叶子 ...
- 在MySQL的InnoDB存储引擎中count(*)函数的优化
写这篇文章之前已经看过了很多数据库方面的优化内容,大部分都是加索引.使用事务.要什么select什么等等.然而,只是停留在阅读的层面上,很少有实践,因为没有遇到真实的项目,一切都是纸上谈兵.实践是检验 ...
随机推荐
- qt中采用宽带speex进行网络语音通话实验程序
qt中采用宽带speex进行网络语音通话实验程序 本文博客链接:http://blog.csdn.NET/jdh99,作者:jdh,转载请注明. 环境: 主机:WIN8 开发环境:Qt5 3.1. ...
- 减少Qt编译时间暨简单Qt裁剪
本站所有文章由本站和原作者保留一切权力,仅在保留本版权信息.原文链接.原文作者的情况下允许转载,转载请勿删改原文内容, 并不得用于商业用途. 谢谢合作.原文链接:减少Qt编译时间暨简单Qt裁剪 编译一 ...
- OSGI资料
http://osgi.codeplex.com/ http://www.iopenworks.com/
- ZooKeeper学习第三期---Zookeeper命令操作(转)
转载来源:https://www.cnblogs.com/sunddenly/p/4031881.html 一.Zookeeper的四字命令 Zookeeper支持某些特定的四字命令字母与其的交互.他 ...
- YARN分析系列之一 -- 总览YARN组件
下图简单明了的描述了hadoop yarn 的功能是如何从 hadoop 中细化出来的. 注:图片来自 https://apprize.info/php/hadoop/9.html Hadoop 从 ...
- vue-cli3.x npm create projectName 报错: Unexpected end of JSON input while parsing near......
npm 版本与node版本还有webpack版本之间的问题 清理缓存,“ npm cache clean --force " 一切OK
- Fastjson的SerializerFeature序列化属性
Fastjson的SerializerFeature序列化属性 fastJson在key的value为null时,默认是不显示出这个字段的 JSONObject.toJSONString(Object ...
- 深入V8引擎-AST(4)
(再声明一下,为了简单暴力的讲解AST的转换过程,这里的编译内容以"'Hello' + ' World'"作为案例) 上一篇基本上花了一整篇讲完了scanner的Init方法,接下 ...
- 开源系统监控工具Nagios、Zabbix和Open-Falcon的功能特性汇总及优缺点比较
Nagios Nagios 全名为(Nagios Ain’t Goona Insist on Saintood),最初项目名字是 NetSaint.它是一款免费的开源 IT 基础设施监控系统,其功能强 ...
- JavaScript面向对象之封装
Javascript是一种基于对象的语言,你遇到的所有东西几乎都是对象.但是,它又不是一种真正的面向对象编程语言,因为它的语法中没有 class(类). 那么,如果我们要把"属性" ...