修正_typora文档复制到博客图片失效
开始
今天开始尝试使用
Typora写markdown 然后复制到博客园,不过会有一个问题那就是 typroa 插入的图片都是本地的,md文档复制到博客园之后,图片都失效了
通过百度,有工具可以直接把 md 文档中的图片上传到博客园,然后替换文档中的链接,我把工具下载下来之后,发现这东西依赖
.net,而这个东西好大,所以萌生了自己写一个工具的想法
注意!!!!!
sm.ms图床有限制
- 一分钟10张
- 一小时20张
- 一星期50张
所以,,, 白嫖不了了。。。
其实是可以的 只是需要改造一下...
加一个代理池
但是 还是默默的 换成自己的把
分析博客园上传图片接口
博客园有三种编辑器,其中
markdown编辑器和tinyMCE编辑器可以上传图片
- 首先分析一下接口,在拖入图片之后会请求一个接口,上传文件,但是我用python 仿照他请求之后一直返回500错误。另一个编辑器使用的接口也是不可用的。
- 最后折腾了三四个小时发现它在服务端设置了禁止跨域.... 我早该想到的 !
- 所以不能使用这种方式了,但是已有的.net 工具是怎么实现的呢?应该是官方发布的吧。不然登录验证怎么做
寻找图床
既然博客园是不能上传图片了,那就需要找一个图床,需求就是特别稳定,据说新浪图床还炸了。找了之后有三个图床。
- sm.ms
- 路过图床
- 中关村的图片上传接口
- 找到的其他接口都需要登录才行,所以不好使
- 简单分析之后,决定使用sm.ms ,因为这个网址没有对接口做演示,且官方也放出了api,并且也没有什么限制
- 上传文件之后它请求了这个接口
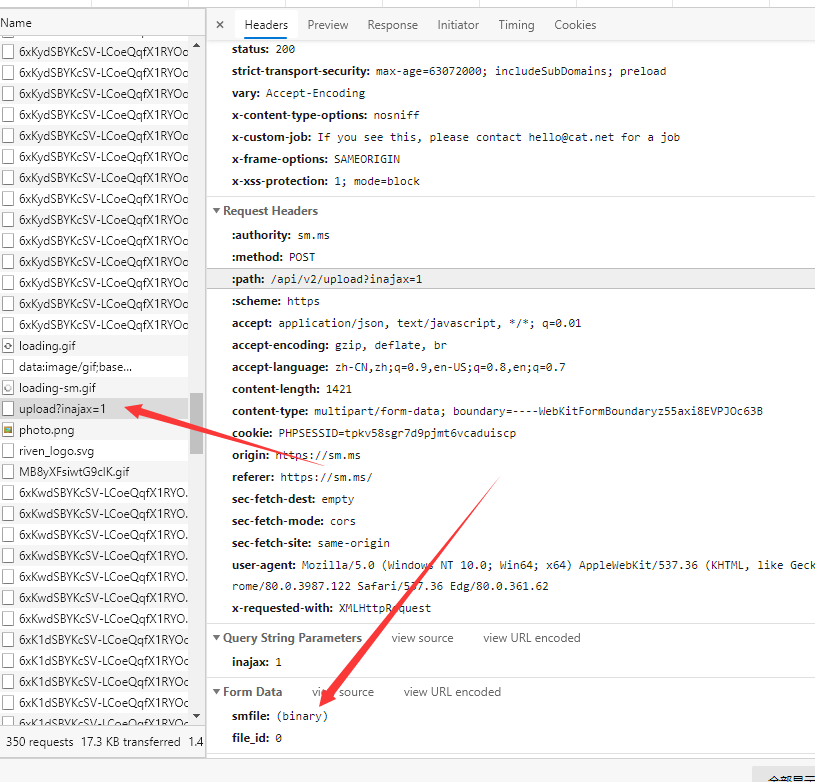
- 并且返回了一个json 数据是图片的url (这么老实的图床,感觉白嫖的良心痛,但是也不能一直白嫖吧)
- 写了python 代码测试了一下接口,确实可用
import requests as rq
import json
# 传入图片名 返回图床url
def uploadImg(imgname):
url = 'https://sm.ms/api/v2/upload?inajax=1'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36 Edg/80.0.361.62',
}
files = [('smfile',(imgname,open(imgname, 'rb'),'image/png'))]
r = rq.post(url,headers=headers,files=files)
dic = json.loads(r.text)
print(r.text)
try:
if 'data' in dic:
return dic['data']['url']
elif 'code' in dic:
if dic['code'] == 'image_repeated':
return dic['images']
else:
print(r.text)
exit()
except Exception as e:
print(str(e))
exit()
print(uploadImg('2.png'))
- 那后面就是,正则匹配图片链接,然后,通过上面的自定义函数得到图片在图床的url,再替换到md文件中即可
- 最后效果

- 此时文件中的链接被替换成了图床链接,这时候文档复制到哪里都行了,不过为了防止图床炸掉,还是在本地保存了一份 (将typroa 图片设置为复制到文档同目录就好了)
- 最后贴出全部代码
import requests as rq
from bs4 import BeautifulSoup
import sys
import re
import json
def uploadImg(imgname):
url = 'https://sm.ms/api/v2/upload?inajax=1'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36 Edg/80.0.361.62',
}
files = [('smfile',(imgname,open(imgname, 'rb'),'image/png'))]
r = rq.post(url,headers=headers,files=files)
dic = json.loads(r.text)
try:
if 'data' in dic:
return dic['data']['url']
elif 'code' in dic:
if dic['code'] == 'image_repeated':
return dic['images']
else:
print(r.text)
exit()
except Exception as e:
print(str(e))
exit()
def getImgStr(str_):
pattern = re.compile(r'\!\[.*?]\(.*?\)')
return pattern.findall(str_)
def getImgName(img_str):
pattern = re.compile(r'\(.*.\)')
return pattern.findall(img_str)[0][1:-1]
if __name__ == '__main__':
if len(sys.argv) < 2:
print('请传递参数进来'+str(len(sys.argv)))
exit()
md_filename = sys.argv[1]
md_str = ''
with open(md_filename,'r',encoding='utf-8') as f:
md_str = str(f.read())
img_strs = getImgStr(md_str)
for img_str in img_strs:
img_name = getImgName(img_str)
img_url = uploadImg(img_name)
md_str = md_str.replace(img_name,img_url)
print(img_url)
with open('修正_'+md_filename,'w',encoding='utf-8') as f:
f.write(md_str)
- 最后再通过pyingtaller 打包成exe 然后放到系统变量path所指向的目录下就行了。下次编辑文档,在md文档所在处,地址栏输入cmd 然后执行命令
up_img 文档名.md就可以完成图片上传替换
额外的
虽然图片不能上传到博客园,但是解析接口的时候发现了些比较诡异的事情。
TinyMCE编辑器所使用的图片接口,上传之后没有返回任何东西,但是图片却加载进来了,我死活不相信这么玄学的事情,分析了js代码之后,确实看到了对接收结果的处理,但是浏览器调试工具就是不显示返回结果。
最后使用fiddler 抓包,终于发现了数据
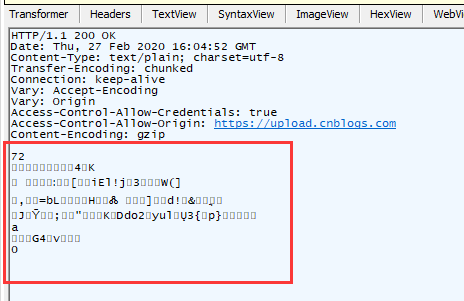
显然是加密的,但是如何做到 dev-tool不显示,还真的不知道的骚操作
虽然图床可用,但是终究放心不下,最终准备使用七牛云,毕竟免费送10G空间流量的不是...
修正_typora文档复制到博客图片失效的更多相关文章
- 使用word文档直接发表博客 8 )
目前大部分的博客作者在用Word写博客这件事情上都会遇到以下3个痛点: 1.所有博客平台关闭了文档发布接口,用户无法使用Word,Windows Live Writer等工具来发布博客.使用Word写 ...
- word文档发布至博客wordpress网站系统
今天ytkah接到一个需求:将word文档发布到wordpress网站上,因为客户那边习惯用word来编辑文章,想直接将内容导入到wp网站中,其实 Word 已经提供了这样的功能,并且能够保留 Wor ...
- 博客图片失效?使用npm工具一次下载/替换所有失效的外链图片
前言 大约一个月前,微博的图片外链失效了,以及掘金因为盗链问题也于2019/06/06决定开启防盗链,造成的影响是:个人博客网站的引用了这些图片外链都不能显示. 目前微博和掘金的屏蔽,在CSDN和se ...
- 文顶顶iOS开发博客链接整理及部分项目源代码下载
文顶顶iOS开发博客链接整理及部分项目源代码下载 网上的iOS开发的教程很多,但是像cnblogs博主文顶顶的博客这样内容图文并茂,代码齐全,示例经典,原理也有阐述,覆盖面宽广,自成系统的系列教程 ...
- WebApi实现验证授权Token,WebApi生成文档等 - CSDN博客
原文:WebApi实现验证授权Token,WebApi生成文档等 - CSDN博客 using System; using System.Linq; using System.Web; using S ...
- Python+Typora博客图片上传
简介 用Typora 写Markdown 1年多了,这个编辑器的确很好用,但就是写完博客复制到博客园时要一个个手动插替换图片非常麻烦.后来发现最新版的Typora 已经支持图片上传功能,在 设置-图像 ...
- 如何使用免费PDF控件从PDF文档中提取文本和图片
如何使用免费PDF控件从PDF文档中提取文本和图片 概要 现在手头的项目有一个需求是从PDF文档中提取文本和图片,我以前也使用过像iTextSharp, PDFBox 这些免费的PD ...
- hexo博客图片问题
hexo博客图片问题 第一步 首先确认_config.yml 中有 post_asset_folder:true. Hexo 提供了一种更方便管理 Asset 的设定:post_asset_folde ...
- 在线HTML文档编辑器使用入门之图片上传与图片管理的实现
在线HTML文档编辑器使用入门之图片上传与图片管理的实现: 官方网址: http://kindeditor.net/demo.php 开发步骤: 1.开发中只需要导入选中的文件(通常在 webapp ...
随机推荐
- Docke-ce 安装
Docker-ce 的安装 安装系统工具 yum install -y yum-utils device-mapper-persistent-data lvm2 添加docker镜像源 yum-con ...
- 第31届IMO 第2题
题目 设n>=3,考虑一个圆上由2n-1个不同点构成的集合E.现给E中恰好k个点染上黑色,如果至少有一对黑点使得这两个黑点之间的弧上(两段弧中的某一个)包含恰好E中的n个点,就成这样的染色方法是 ...
- centos7 下 安装GeoIP2,在nginx中根据ip地址对应的国家转发请求
最近有个需求是根据用户的地理位置,访问不同的服务器,比如国外用户访问国外的服务器,国内的用户访问国内的服务器,实现的思路主要两种: 智能dns,这个需要在阿里云中注册为企业版才有提供 nginx中使用 ...
- hdu 1007 Quoit Design(平面最近点对)
题意:求平面最近点对之间的距离 解:首先可以想到枚举的方法,枚举i,枚举j算点i和点j之间的距离,时间复杂度O(n2). 如果采用分治的思想,如果我们知道左半边点对答案d1,和右半边点的答案d2,如何 ...
- Visual Studio Code搭建Python开发环境方法总结
更新:目前VSCode官方Python插件已经支持代码运行与调试,无需安装Code Runner插件. 1.下载安装Python,地址 https://www.python.org/downloads ...
- [转]TCP/IP 协议基础(一)
参考书籍为<图解tcp/ip>-第五版.这篇随笔,主要内容还是TCP/IP所必备的基础知识,包括计算机与网络发展的历史及标准化过程(简述).OSI参考模型.网络概念的本质.网络构建的设备等 ...
- JDK线程池和Spring线程池的使用
JDK线程池和Spring线程池实例,异步调用,可以直接使用 (1)JDK线程池的使用,此处采用单例的方式提供,见示例: public class ThreadPoolUtil { private s ...
- shell-快速抽样
有时我们需要对文件进行抽样,这时候只需要一个shell命令就可以抽取固定行数的样本:shuf shuf -n $m $file 参数有2: -n: 抽样行数 -r: 是否重复
- 题解【洛谷P1896】[SCOI2005]互不侵犯
题面 棋盘类状压 DP 经典题. 我们考虑设 \(dp_{i,j,s}\) 表示前 \(i\) 行已经摆了 \(j\) 个国王,且第 \(i\) 行国王摆放的状态为 \(s\) 的合法方案数. 转移的 ...
- [Note]prufer
[Note]Prufer编码 实现 不断删除度数为\(1\)的最小序号的点,并输出与其相连的节点的序号,直至树中只有两个节点. 性质 任何一棵\(n\)节点的树都可以唯一的用长度为\(n-2\)的pr ...