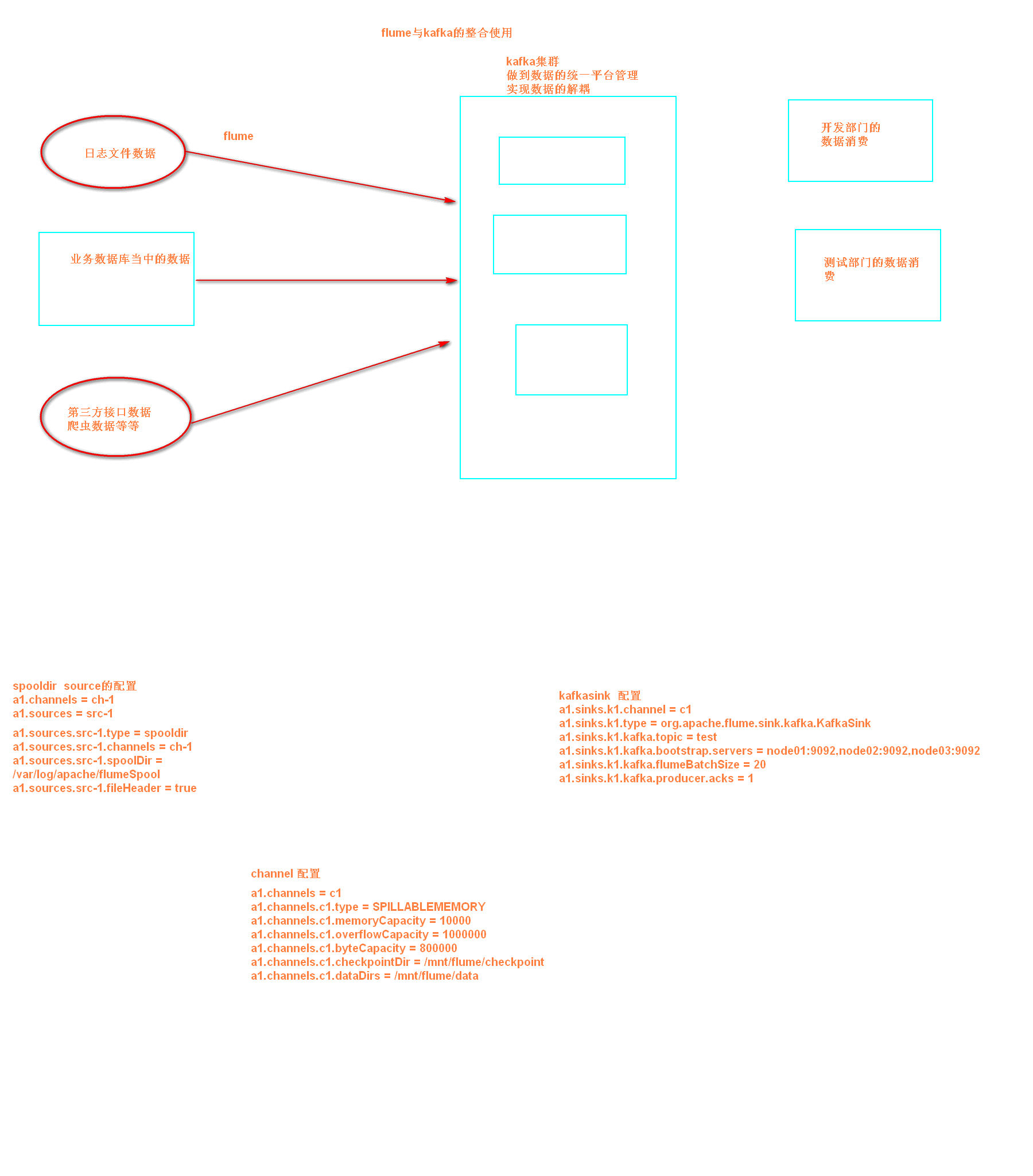
kafka和flume进行整合的日志采集的confi文件编写
配置flume.conf
为我们的source channel sink起名
a1.sources = r1
a1.channels = c1
a1.sinks = k1
指定我们的source收集到的数据发送到哪个管道
a1.sources.r1.channels = c1
指定我们的source数据收集策略
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /export/servers/flumedata
a1.sources.r1.deletePolicy = never
a1.sources.r1.fileSuffix = .COMPLETED
a1.sources.r1.ignorePattern = ^(.)*\.tmp$
a1.sources.r1.inputCharset = GBK
指定我们的channel为memory,即表示所有的数据都装进memory当中
a1.channels.c1.type = memory
指定我们的sink为kafka sink,并指定我们的sink从哪个channel当中读取数据
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = test
a1.sinks.k1.kafka.bootstrap.servers = node01:9092,node02:9092,node03:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
启动flume
bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name a1 -Dflume.root.logger=INFO,console
kafka和flume进行整合的日志采集的confi文件编写的更多相关文章
- 基于Kafka的服务端用户行为日志采集
本文来自网易云社区 作者:李勇 背景 随着互联网的不断发展,用户所产生的行为数据被越来越多的网站重视,那么什么是用户行为呢?所谓的用户行为主要由五种元素组成:时间.地点.人物.行为.行为对应的内容.为 ...
- Filebeat7 Kafka Gunicorn Flask Web应用程序日志采集
本文的内容 如何用filebeat kafka es做一个好用,好管理的日志收集工具 放弃logstash,使用elastic pipeline gunicron日志格式与filebeat/es配置 ...
- Flume+Kafka+storm的连接整合
Flume-ng Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume的文档可以看http://flume.apache.org/FlumeUserGuide.html ...
- 基于Flume+LOG4J+Kafka的日志采集架构方案
本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说 ...
- 【采集层】Kafka 与 Flume 如何选择--转自悟性的博文
[采集层]Kafka 与 Flume 如何选择 收藏 悟性 发表于 2年前 阅读 23167 收藏 16 点赞 4 评论 1 摘要: Kafka, Flume 采集层 主要可以使用Flume, Kaf ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- 日志采集框架Flume
前言 在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集.结果数据导出.任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop生态体系中 ...
- 日志采集框架 Flume
日志采集框架 Flume 1 概述 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到H ...
- Flume日志采集框架的使用
文章作者:foochane 原文链接:https://foochane.cn/article/2019062701.html Flume日志采集框架 安装和部署 Flume运行机制 采集静态文件到h ...
随机推荐
- Eclipse导入的Maven项目没有Build Path
我导入的是 Signal-Server项目到 Eclipse中,发现 src 文件夹上面没有#号,包视图和语法提示都没有 ~~ 解决方法: 修改 Project Facets 在 项目右键 -> ...
- 关于 webpack 的研究
webpack的官网:http://webpack.github.io/ 安装webpack 演示项目安装,使用全局安装:npm install webpack -g 真正的项目使用依赖式安装,保证在 ...
- vue 本地环境API代理设置和解决跨域
写一个config.js文件,作为项目地址的配置. //项目域名地址 const url = 'https://exaple.com'; let ROOT; //由于封装的axios请求中,会将ROO ...
- asp.net core Mvc 增删改查
1.创建项目 创建Data文件夹 创建实体类Students/cs public class Students { public Guid Id { get; set; } public string ...
- Python:验证码识别
说明:此验证方法很弱,几乎无法识别出正确的验证码
- Ruby——输入&输出
Ruby的输入和输出操作.输入是程序从键盘.文件或者其他程序读取数据.输出是程序产生数据.可以输出到屏幕.文件或者其他程序. Ruby中的一些类有些方法会执行输入&输出操作.例如Kernel. ...
- 树————N叉树的层序遍历
思想: 使用队的思想,将每一层的节点放入队列中,依次弹出,同时将其children放入队列. c++ /* // Definition for a Node. class Node { public: ...
- 6、通过Appium Desktop 实现录制功能
1.老规矩,我们进入下面这个界面 图中红色标记1为 “top by coordinates” 按钮, 这是一种通过坐标定位元素的方式. 图中红色标记2为 “Start Recording” 按钮, ...
- testNG官方文档翻译-2 注解
这里是一份TestNG中的可用注解及其属性的概述. 一.用于一个TestNG类的信息配置的注解: @BeforeSuite:被BeforeSuite注解的方法将在其所在suite中的所有test运行之 ...
- .net core 根据环境变量区分正式、测试 配置文件
新建测试.正式环境下所用的 配置信息文件 appsettings.Development.json 文件信息: { "Logging": { "LogLevel" ...