层层递进——宽度优先搜索(BFS)
问题引入
我们接着上次“解救小哈”的问题继续探索,不过这次是用宽度优先搜索(BFS)。
注:问题来源可以点击这里 http://www.cnblogs.com/OctoptusLian/p/7429645.html
最开始小哼在入口(1,1)处,一步之内可以到达的点有(1,2)和(2,1)。
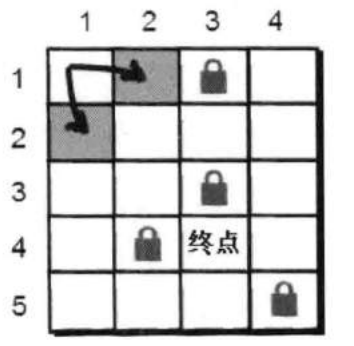
但是小哈并不在这两个点上,那小哼只能通过(1,2)和(2,1)这两点继续往下走。
比如现在小哼走到了(1,2)这个点,之后他又能够到达哪些新的点呢?有(2,2)。再看看通过(2,1)又可以到达哪些点呢?可以到达(2,2)和(3,1)。
此时你会发现(2,2)这个点既可以从(1,2)到达,也可以从(2,1)到达,并且都只使用了两步。
注:为了防止一个点多次被走到,这里需要一个数组来记录一个点是否已经被走到过。
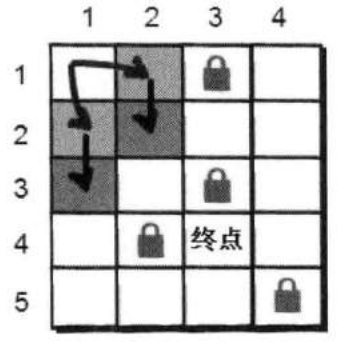
此时小哼2步可以走到的点就全部走到了,有(2,2)和(3,1),可是小哈并不在这两个点上。看来没有别的办法,还得继续往下尝试,看看通过(2,2)和(3,1)这两个点还能到达哪些新的没有走到过的点。
通过(2,2)这个点我们可以到达(2,3)和(3,2),通过(3,1)可以到达(3,2)和(4,1)。
现在三步可以到达的点有(2,3)、(3,2)和(4,1),依旧没有到达小哈的所在点,所以我们需要继续重复刚才的做法,直到找到小哈所在点为止。
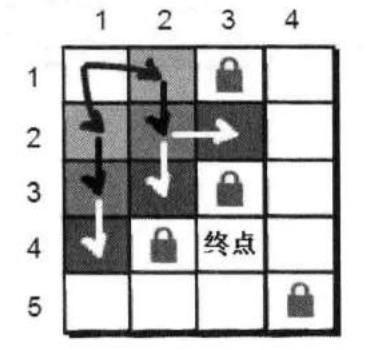
解决步骤
回顾一下刚才的算法,可以用一个队列来模拟这个过程。在这里我们用一个结构体来实现队列
struct note{
int x; //横坐标
int y; //纵坐标
int s; //步数
};
struct note que[]; //因为地图大小不超过50*50,因此队列扩展不会超过2500个
int head,tail;
int a[][] = {}; //用来存储地图
int book[][] = {}; //数组book的作用是记录哪些点已经在队列中了,防止一个点被重复扩展,并全部初始化为0
/*最开始的时候需要进行队列初始化,即将队列设置为空*/
head = ;
tail = ;
//第一步将(1,1)加入队列,并标记(1,1)已经走过。
que[tail].x = ;
que[tail].y = ;
que[tail].s = ;
tail++;
book[][] = ;
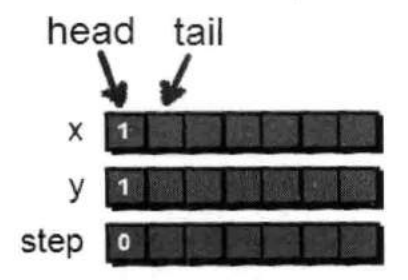
然后从(1,1)开始,先尝试往右走到达了(1,2)。
tx = que[head].x;
ty = que[head].y+;
需要判断(1,2)是否越界。
if(tx < || tx > n || ty < || ty > m)
continue;
再判断(1,2)是否为障碍物或者已经在路径中。
if(a[tx][ty] == && book[tx][ty] == )
{
}
如果满足上面的条件,则将(1,2)入队,并标记该点已经走过。
book[tx][ty] = ; //注意bfs每个点通常情况下只入队一次,和深搜不同,不需要将book数组还原
//插入新的点到队列中
que[tail].x = tx;
que[tail].y = ty;
que[tail].s = que[head].s+; //步数是父亲的步数+1
tail++;
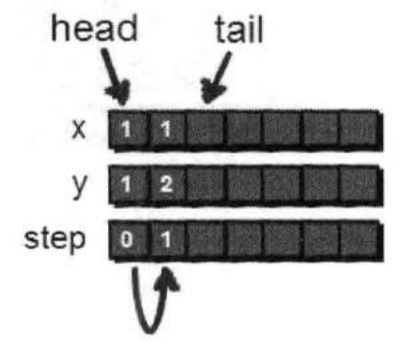
接下来还要继续尝试往其他方向走。
在这里我们规定一个顺序,即按照顺时针的方向来尝试(右→下→左→上)。
我们发现从(1,1)还是可以到达(2,1),因此也需要将(2,1)也加入队列,代码实现与刚才对(1,2)的操作是一样的。
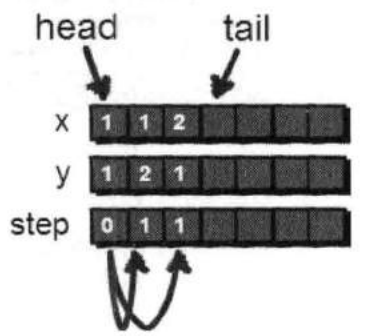
对(1,1)扩展完毕后,此时我们将(1,1)出队(因为扩展完毕,已经没用了)。
head++;
接下来我们需要在刚才新扩展出的(1,2)和(2,1)这两个点上继续向下探索(因为还没有到达小哈所在的位置,所以还需要继续)。
(1,1)出队之后,现在队列的head正好指向了(1,2)这个点,现在我们需要通过这个点继续扩展,通过(1,2)可以到达(2,2),并将(2,2)也加入队列。
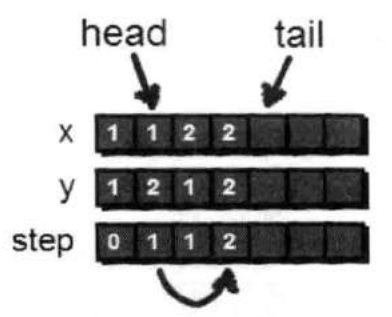
(1,2)这个点已经处理完毕,于是可以将(1,2)出队。(1,2)出队之后,head指向了(2,1)这个点。通过(2,1)可以到达(2,2)和(3,1),但是因为(2,2)已经在队列中,因此我们只需要将(3,1)入队。
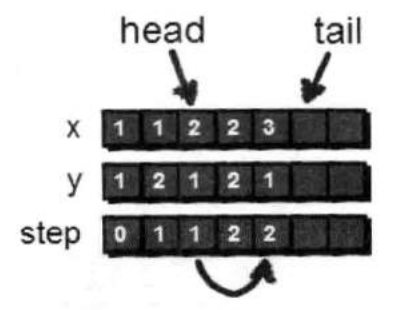
到目前为止我们已经扩展出从起点出发2步以内可以到达的所有点,可是依旧没有到达小哈所在的位置,因此还需要继续扩展,直到找到小哈所在的点才算结束。
为了方便向四个方向扩展,这里需要一个next数组:
int next[][] = { //顺时针方向
{,}; //向右走
{,}; //向下走
{,-}; //向左走
{-,}; //向上走
}
完整代码如下
#include<stdio.h>
struct note{
int x; //横坐标
int y; //纵坐标
int f; //父亲在队列中的编号(本题不需要输出路径,可以不需要f)
int s; //步数
};
int main()
{
struct note que[]; //因为地图大小不超过50*50,因此队列扩展不会超过2500个 int a[][] = {}; //用来存储地图
int book[][] = {}; //数组book的作用是记录哪些点已经在队列中了,防止一个点被重复扩展,并全部初始化为0
//定义一个用于表示走的方向的数组
int next[][] = { //顺时针方向
{,}, //向右走
{,}, //向下走
{,-}, //向左走
{-,}, //向上走
}; int head,tail;
int i,j,k,n,m,startx,starty,p,q,tx,ty,flag; scanf("%d %d",&n,&m);
for(i=;i<=n;i++)
for(j=;j<=m;j++)
scanf("%d",&a[i][j]);
scanf("%d %d %d %d",&startx,&starty,&p,&q); //队列初始化
head = ;
tail = ;
//往队列插入迷宫入口坐标
que[tail].x = startx;
que[tail].y = starty;
que[tail].f = ;
que[tail].s = ;
tail++;
book[startx][starty] = ; flag = ; //用来标记是否到达目标点,0表示暂时没有到达, 1表示已到达
while(head < tail){ //当队列不为空时循环
for(k=;k<=;k++) //枚举四个方向
{
//计算下一个点的坐标
tx = que[head].x + next[k][];
ty = que[head].y + next[k][];
if(tx < || tx > n || ty < || ty > m) //判断是否越界
continue;
if(a[tx][ty] == && book[tx][ty] == ) //判断是否是障碍物或者已经在路径中
{
book[tx][ty] = ; //把这个点标记为已经走过。注意bfs每个点通常情况下只入队一次,和深搜不同,不需要将book数组还原
//插入新的点到队列中
que[tail].x = tx;
que[tail].y = ty;
que[tail].f = head; //因为这个点是从head扩展出来的,所以它的父亲是head,本题不需要求路径,因此可省略
que[tail].s = que[head].s+; //步数是父亲的步数+1
tail++; }
if(tx == p && ty == q) //如果到目标点了,停止扩展,任务结束,退出循环
{
flag = ; //重要!两句不要写反
break;
}
}
if(flag == )
break;
head++; //当一个点扩展结束后,才能对后面的点再进行扩展
}
printf("%d",que[tail-].s); //打印队列中末尾最后一个点,也就是目标点的步数
//注意tail是指向队列队尾(最后一位)的下一个位置,所以这里需要减1
getchar();getchar();
return ;
}
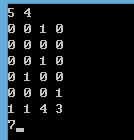
第一行有两个数n m,n表示迷宫的行数,m表示迷宫的列数。
接下来n行m列为迷宫,0表示空地,1表示障碍物。
最后一行四个数,前两个数表示迷宫入口的x和y坐标,后两个为小哈的x和y坐标。
写在最后
通过本次学习,我们知道一道问题的解决方法是多种多样的,不光可以用深度优先搜索来解,也可以用宽度优先搜索。
个人感觉宽度优先搜索就像是一次病原体的扩散,目的是要以最短的速度扩散到最广的范围。
注:文章内容源自《啊哈算法》
层层递进——宽度优先搜索(BFS)的更多相关文章
- 【算法入门】广度/宽度优先搜索(BFS)
广度/宽度优先搜索(BFS) [算法入门] 1.前言 广度优先搜索(也称宽度优先搜索,缩写BFS,以下采用广度来描述)是连通图的一种遍历策略.因为它的思想是从一个顶点V0开始,辐射状地优先遍历其周围较 ...
- 宽度优先搜索BFS(Breadth-First-Search)
Breadth-First-Search 1. 与DFS的异同 相同点:搜索所有可能的状态. 不同点:搜索顺序. 2. BFS总是先搜索距离初始状态近的状态,它是按照:开始状态->只需一次转移就 ...
- 挑战程序2.1.5 穷竭搜索>>宽度优先搜索
先对比一下DFS和BFS 深度优先搜索DFS 宽度优先搜索BFS 明显可以看出搜索顺序不同. DFS是搜索单条路径到 ...
- 【BFS宽度优先搜索】
一.求所有顶点到s顶点的最小步数 //BFS宽度优先搜索 #include<iostream> using namespace std; #include<queue> # ...
- BFS算法的优化 双向宽度优先搜索
双向宽度优先搜索 (Bidirectional BFS) 算法适用于如下的场景: 无向图 所有边的长度都为 1 或者长度都一样 同时给出了起点和终点 以上 3 个条件都满足的时候,可以使用双向宽度优先 ...
- 算法基础⑦搜索与图论--BFS(宽度优先搜索)
宽度优先搜索(BFS) #include<cstdio> #include<cstring> #include<iostream> #include<algo ...
- 搜索与图论②--宽度优先搜索(BFS)
宽度优先搜索 例题一(献给阿尔吉侬的花束) 阿尔吉侬是一只聪明又慵懒的小白鼠,它最擅长的就是走各种各样的迷宫. 今天它要挑战一个非常大的迷宫,研究员们为了鼓励阿尔吉侬尽快到达终点,就在终点放了一块阿尔 ...
- [宽度优先搜索] FZU-2150 Fire Game
Fat brother and Maze are playing a kind of special (hentai) game on an N*M board (N rows, M columns) ...
- 宽度优先搜索--------迷宫的最短路径问题(dfs)
宽度优先搜索运用了队列(queue)在unility头文件中 源代码 #include<iostream>#include<cstdio>#include<queue&g ...
随机推荐
- zabbix 通过自定义key完成网卡监控
创建执行脚本: # cat /etc/zabbix/monitor_scripts/network.sh #!/bin/bash #set -x usage() { echo "Useage ...
- angular五种服务详解
在这之前angular学习笔记(十五)-module里的'服务'这篇文章里,已经大致讲解了ng中的'服务',在之后的很多地方也用到了服务,但是,所有的服务都是使用app.factory来创建的.但其实 ...
- burpsuite扩展集成sqlmap插件
通常我们在使用sqlmap测试SQL注入问题的时候会先使用burpsuite来抓包,然后交给sqlmap进行扫描,此操作略显繁琐. 为了避免这种繁琐的重复操作可以将sqlmap以插件的方式集成到bur ...
- MonoBehaviour类Invoke, Coroutine
异步函数 在一个方法执行时调用另一个方法.而被调用的方法或者其中的某些语句不是立刻执行,而是过一段时间后才执行. MonoBehaviour提供了两种异步方法 调用(Invoke) 协程(Corout ...
- http.ResponseWriter的Flush
func handle(res http.ResponseWriter, req *http.Request) { fmt.Fprintf(res, "sending first line ...
- 玩转Bootstrap(JS插件篇)-第1章 模态弹出框 :1-2 动画过渡
动画过渡(Transitions) 这一小节我们先来讲“动画过渡(Transitions)”这个插件的使用,源文件:transition.js Bootstrap框架默认给各个组件提供了基本动画的过渡 ...
- EL表达式取值中文再发送请求时会乱码
问题描述: 在网站底部进行评论,点击提交按钮时,后台tomcat报错,通过火狐浏览器的firebug看到发送的POST请求体中,有一个title参数是乱码, 导致该字段超长违反了数据库字段的长度约束: ...
- 隐藏windows任务栏中的窗口显示
在实际应用中遇到类似下列需要: 隐藏windows窗口,在windows任务栏中窗口不可见,但应用程序在后台运行. windows应用程序的窗口默认会在任务栏中添加一个可见的窗口项,方便用户操作和在不 ...
- 05-老马jQuery教程-动画
前言 jQuery的动画系统做的非常出色,而且把最常用的显示.隐藏.淡入淡出.滑动显示和折叠凳效果都做了很好的封装.跟jQuery的选择器和事件配合起来,可以实现很多很绚的效果,而且简单易用兼容性好. ...
- WideCharToMultiByte和MultiByteToWideChar函数的用法(转)
转自:http://www.cnblogs.com/gakusei/articles/1585211.html 为了支持Unicode编码,需要多字节与宽字节之间的相互转换.这两个系统函数在使用时需要 ...