部署hadoop的开发环境
第一步:安装jdk
由于hadoop是java开发的,所以需要JDK来运行代码。这里安装的是jdk1.6.
jdk的安装见http://www.cnblogs.com/tommyli/archive/2012/01/06/2314706.html
第二步:创建独立的用户
useradd hadoop
passwd hadoop
有些机器不能设置空密码的时候
passwd -d hadoop
这里的用户名为hadoop,如果你要调试的时候要注意名字。
比如我用windows调试linux的集群,这个名字应该是windows系统的用户名(否则你没有权限提交作业到hadoop)。
第三步:设置用户无密码登陆
su - hadoop
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
exit
第四步:下载hadoop
mkdir /opt/hadoop
cd /opt/hadoop/
wget http://apache.mesi.com.ar/hadoop/common/hadoop-1.2.0/hadoop-1.2.0.tar.gz
tar -xzf hadoop-1.2.0.tar.gz
mv hadoop-1.2.0 hadoop
chown -R hadoop /opt/hadoop
cd /opt/hadoop/hadoop/
第五步:配置hadoop
vi conf/core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property> <property>
<name>fs.default.name</name>
<value>hdfs://10.53.132.52:54310</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property> <property>
<name>dfs.permissions</name>
<value>false</value>
</property>
vi conf/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
<description>Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
</description>
</property>
vi conf/mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>10.53.132.52:54311</value>
<description>The host and port that the MapReduce job tracker runs
at. If "local", then jobs are run in-process as a single map
and reduce task.
</description>
</property>
第六步:开启hadoop
bin/hadoop namenode -format
bin/start-all.sh
关闭是
bin/stop-all.sh
验证开启是
jps
26049 SecondaryNameNode
25929 DataNode
26399 Jps
26129 JobTracker
26249 TaskTracker
25807 NameNode
第七步:下载并设置eclipse的hadoop插件。
插件文件是:hadoop-eclipse-plugin-1.2.0.jar
放到eclipse的plugins目录下即可。
第八步:打开eclipse创建map/reduce项目。
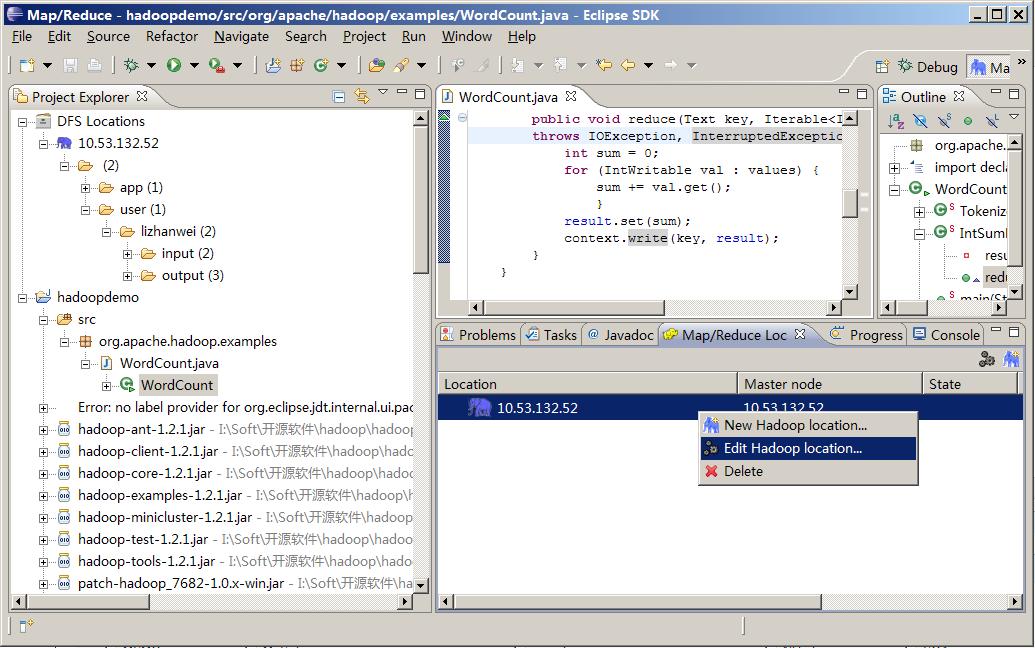
修改map/reduce和hdfs的地址和端口
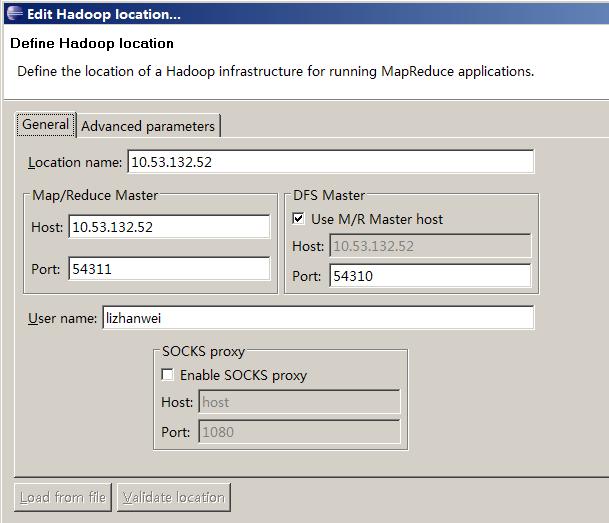
第九步:调试hadoop
package org.apache.hadoop.examples; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "10.53.132.52:54311"); //conf.addResource(new Path("\\soft\\hadoop\\conf\\core-site.xml"));
//conf.addResource(new Path("\\soft\\hadoop\\conf\\hdfs-site.xml")); String[] ars=new String[]{"input","output"};
String[] otherArgs = new GenericOptionsParser(conf, ars).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
(这里是吧作业提交到远端的hadoop)
调试
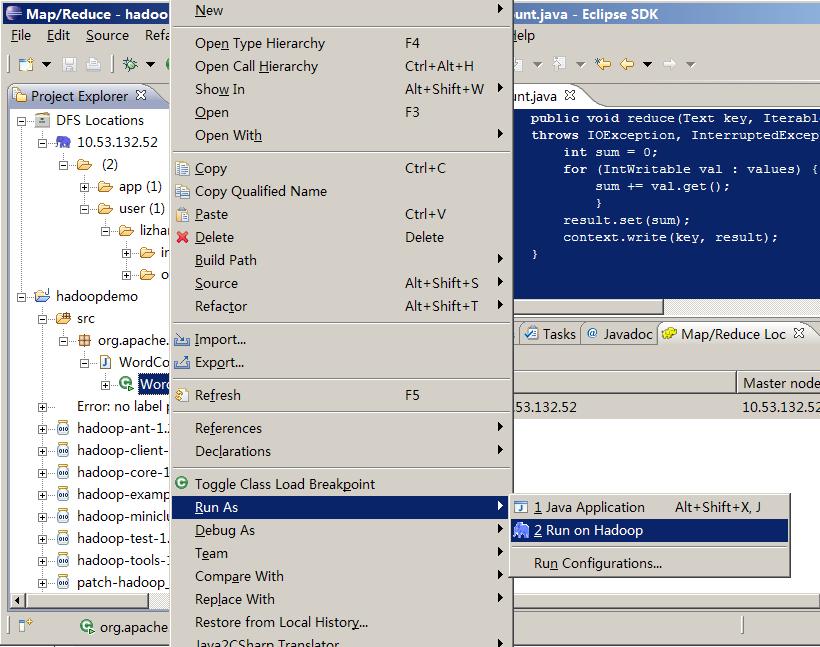
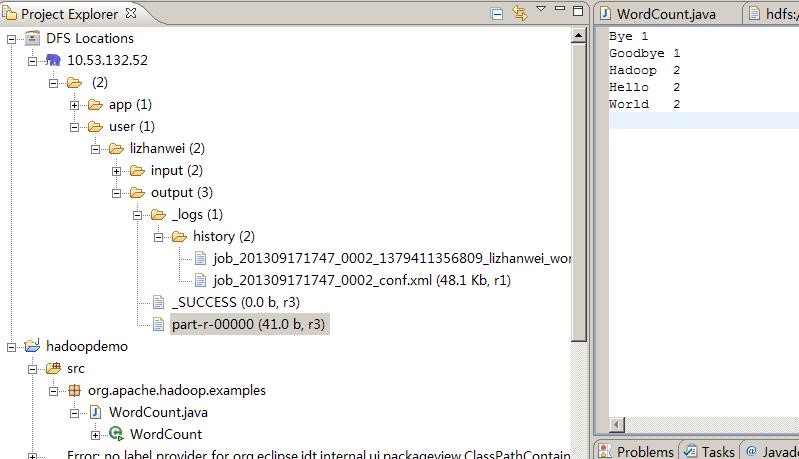
结果
13/09/17 17:50:32 INFO input.FileInputFormat: Total input paths to process : 2
13/09/17 17:50:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
13/09/17 17:50:33 WARN snappy.LoadSnappy: Snappy native library not loaded
13/09/17 17:50:33 INFO mapred.JobClient: Running job: job_201309171747_0002
13/09/17 17:50:34 INFO mapred.JobClient: map 0% reduce 0%
13/09/17 17:50:39 INFO mapred.JobClient: map 100% reduce 0%
13/09/17 17:50:47 INFO mapred.JobClient: map 100% reduce 33%
13/09/17 17:50:48 INFO mapred.JobClient: map 100% reduce 100%
13/09/17 17:50:49 INFO mapred.JobClient: Job complete: job_201309171747_0002
13/09/17 17:50:49 INFO mapred.JobClient: Counters: 29
13/09/17 17:50:49 INFO mapred.JobClient: Job Counters
13/09/17 17:50:49 INFO mapred.JobClient: Launched reduce tasks=1
13/09/17 17:50:49 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=6115
13/09/17 17:50:49 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
13/09/17 17:50:49 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
13/09/17 17:50:49 INFO mapred.JobClient: Launched map tasks=2
13/09/17 17:50:49 INFO mapred.JobClient: Data-local map tasks=2
13/09/17 17:50:49 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=8702
13/09/17 17:50:49 INFO mapred.JobClient: File Output Format Counters
13/09/17 17:50:49 INFO mapred.JobClient: Bytes Written=41
13/09/17 17:50:49 INFO mapred.JobClient: FileSystemCounters
13/09/17 17:50:49 INFO mapred.JobClient: FILE_BYTES_READ=79
13/09/17 17:50:49 INFO mapred.JobClient: HDFS_BYTES_READ=286
13/09/17 17:50:49 INFO mapred.JobClient: FILE_BYTES_WRITTEN=174015
13/09/17 17:50:49 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=41
13/09/17 17:50:49 INFO mapred.JobClient: File Input Format Counters
13/09/17 17:50:49 INFO mapred.JobClient: Bytes Read=50
13/09/17 17:50:49 INFO mapred.JobClient: Map-Reduce Framework
13/09/17 17:50:49 INFO mapred.JobClient: Map output materialized bytes=85
13/09/17 17:50:49 INFO mapred.JobClient: Map input records=2
13/09/17 17:50:49 INFO mapred.JobClient: Reduce shuffle bytes=85
13/09/17 17:50:49 INFO mapred.JobClient: Spilled Records=12
13/09/17 17:50:49 INFO mapred.JobClient: Map output bytes=82
13/09/17 17:50:49 INFO mapred.JobClient: Total committed heap usage (bytes)=602996736
13/09/17 17:50:49 INFO mapred.JobClient: CPU time spent (ms)=2020
13/09/17 17:50:49 INFO mapred.JobClient: Combine input records=8
13/09/17 17:50:49 INFO mapred.JobClient: SPLIT_RAW_BYTES=236
13/09/17 17:50:49 INFO mapred.JobClient: Reduce input records=6
13/09/17 17:50:49 INFO mapred.JobClient: Reduce input groups=5
13/09/17 17:50:49 INFO mapred.JobClient: Combine output records=6
13/09/17 17:50:49 INFO mapred.JobClient: Physical memory (bytes) snapshot=555175936
13/09/17 17:50:49 INFO mapred.JobClient: Reduce output records=5
13/09/17 17:50:49 INFO mapred.JobClient: Virtual memory (bytes) snapshot=1926799360
13/09/17 17:50:49 INFO mapred.JobClient: Map output records=8
部署hadoop的开发环境的更多相关文章
- 基于Eclipse的Hadoop应用开发环境配置
基于Eclipse的Hadoop应用开发环境配置 我的开发环境: 操作系统ubuntu11.10 单机模式 Hadoop版本:hadoop-0.20.1 Eclipse版本:eclipse-java- ...
- 【Yeoman】热部署web前端开发环境
本文来自 “简时空”:<[Yeoman]热部署web前端开发环境>(自动同步导入到博客园) 1.序言 记得去年的暑假看RequireJS的时候,曾少不更事般地惊为前端利器,写了<Sp ...
- hadoop搭建开发环境及编写Hello World
hadoop搭建开发环境及编写Hello World 本文地址:http://www.cnblogs.com/archimedes/p/hadoop-helloworld.html,转载请注明源地 ...
- 批量部署Hadoop集群环境(1)
批量部署Hadoop集群环境(1) 1. 项目简介: 前言:云火的一塌糊涂,加上自大二就跟随一位教授做大数据项目,所以很早就产生了兴趣,随着知识的积累,虚拟机已经不能满足了,这次在服务器上以生产环境来 ...
- 使用 docker 部署常用的开发环境
使用 docker 部署常用的开发环境 Intro 使用 docker,很多环境可以借助 docker 去部署,没必要所有的环境都在本地安装,十分方便. 前段时间电脑之前返厂修了,回来之后所有的软件都 ...
- 使用vagrant一键部署本地php开发环境(二)制作自己的vagrant box
在上篇的基础上 ,我们已经安装好了virtualbox和vagrant,没有安装的话,参照上篇 使用vagrant一键部署本地php开发环境(一) 1.从网易镜像或阿里等等镜像下载Centos7 ht ...
- 【原创干货】大数据Hadoop/Spark开发环境搭建
已经自学了好几个月的大数据了,第一个月里自己通过看书.看视频.网上查资料也把hadoop(1.x.2.x).spark单机.伪分布式.集群都部署了一遍,但经历短暂的兴奋后,还是觉得不得门而入. 只有深 ...
- windows部署React-Native的开发环境实践(技术细节)
前情摘要 众所周知,有人说.net可以用Xamrian,呵呵,不习惯收费的好么?搞.Net的人设置一次java的环境变量,可能都觉得实在太麻烦了,可能是因为这些年微软确实把我们给带坏了,所有东西一键安 ...
- Hadoop Eclipse开发环境搭建
This document is from my evernote, when I was still at baidu, I have a complete hadoop developme ...
随机推荐
- TextEdit 只能输入数字(0-9)的限制
MaskType="RegEx" MaskUseAsDisplayFormat="True" Mask="[0-9]*" <dxe:T ...
- Eclipse小技巧:收起outline的头文件
- 10 个超炫绘制图表图形的 Javascript 插件【转载+整理】
原文地址 现在,有很多在线绘制图表和图形(Charts and Graphs)的 JavaScript 插件,这些插件还都是免费,以及图表库.这些插件大量出现的原因是基于一个事实:人们不再依赖于 Fl ...
- Android MarsDaemon实现进程及Service常驻
前段时间.就讨论过关于怎样让Service常驻于内存而不被杀死,最后的结论就是使用JNI实现守护进程,可是不得不说的是,在没有改动系统源代码的情况下,想真正实现杀不死服务,是一件非常难的事情.眼下除了 ...
- ArcGIS 10.4的0x80040228许可错误
今天,再次遇到这个问题,再忙得把它记录下来! AO/AE程序的许可方式 不管是开发环境是基于ArcObject还是基于ArcEngine,不管运行环境是Desktop还是Runtime(早已改名了为A ...
- 整合Tomcat和Nginx实现动静态负载均衡
转载请注明原文地址:http://www.cnblogs.com/ygj0930/p/6386135.html Nginx与tomcat整合可以实现服务器的负载均衡. 在用户的请求发往服务器进行处理时 ...
- 结合JSFL/actionscript 实现轮廓动画
动画前半段通过JSFL获取轮廓数据,并在EnterFrame中逐个边缘画出的:后半段机枪动画是美术做好的flash动画. 这里只放出actionscript代码,而JSFL代码涉及到一个工程,暂时保密 ...
- ThreadLocal MDC
因为MDC底层是用ThreadLocal实现的,所以这里补充一些和ThreadLocal相关的知识点. 1.ThreadLocal的三个层次 关于ThreadLocal有三个层次,可以按照这三个层次去 ...
- js 正则表达式校验必须包含字母、数字、特殊字符
1.情景展示 在注册时,密码要求必须同时包含:字母.数字.特殊字符,如何实现? 2.原因分析 用正则表达式进行校验,是最方便的! 3.解决方案 // 密码必须由 8-64位字母.数字.特殊符号组成 ...
- 〖Linux〗Ubuntu13.10搭建文件共享Samba服务器
1. 安装 $ sudo apt-get install samba 2. 配置smb用户密码 # cat /etc/passwd | mksmbpasswd > /etc/samba/smbp ...