机器学习入门-K-means算法
无监督问题,我们手里没有标签
聚类:相似的东西聚在一起
难点:如何进行调参
K-means算法
需要制定k值,用来获得到底有几个簇,即几种类型
质心:均值,即向量各维取平均值
距离的度量: 欧式距离和余弦相似度
优化目标: min∑∑dist(ci, xi) 即每种类别的数据到该类别质心距离的之和最小
1-k x
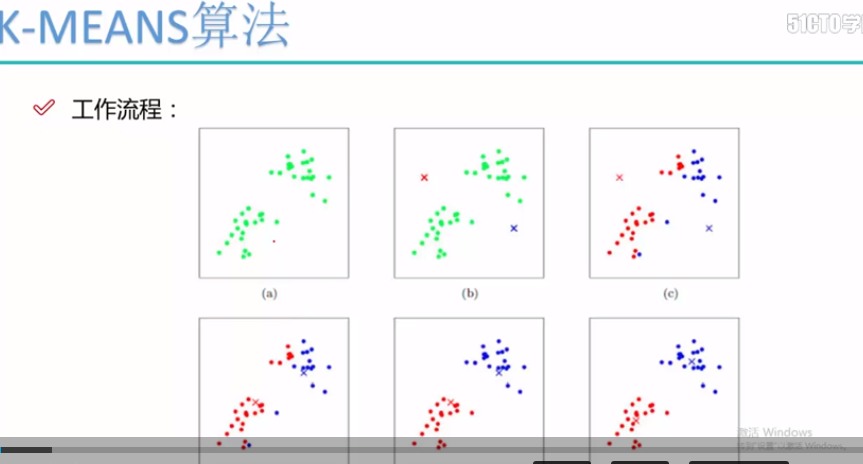
根据上述的工作流程:
第一步:随机选择两个初始点,类别的质心点(图二)
第二步: 根据所选的质心点,根据欧式距离对数据进行分类(图三)
第三步:求得分类后的每个类别的质心(图四)
第四步: 根据所选的质心点,根据欧式距离对数据进行分类(图五)
第五步:求得分类后的每个类别的质心(图五)
.... 一直到分类的数据类别不发生变化为止
优势:简单,快速,适用于常规数据集,分布较为规则的数据集
劣势:
K值难确定
复杂度与样本数据呈线性关系
不太适用于不规则的数据
我们使用sklearn来实现kmeans代码,使用silhouette_score轮廓系数来作为评估
第一步:读入数据
第二步:提取特征列
第三步:建立kmeans模型和训练
第四步:使用.grouby计算每一种类别的聚类中心,即求平均
第五步:使用scatter_matrix 画出两个变量关系的散点图
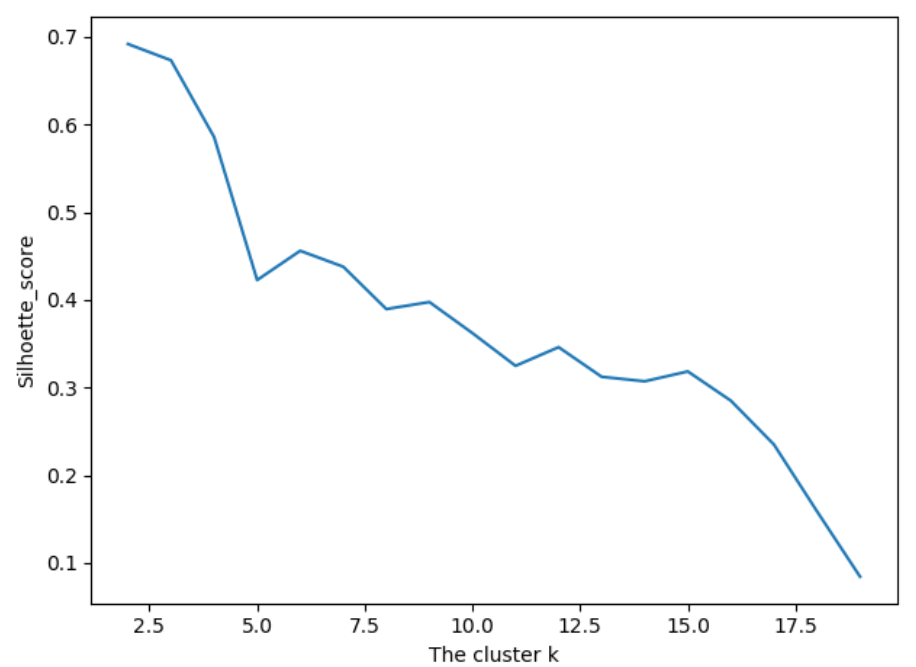
第六步:使用sihouette_score 轮廓系数来比较不同数目的聚类簇的结果影响
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd # 1.读入数据
data = pd.read_csv('data.txt', sep=' ') # 2.提取特征
X = data[['calories', 'sodium', 'alcohol', 'cost']] # 3.建立Kmeans模型和训练
from sklearn.cluster import KMeans model = KMeans(n_clusters=3).fit(X)
beer = data.copy()
beer['cluster3'] = model.labels_
# 根据分类结果,从小到大进行排序
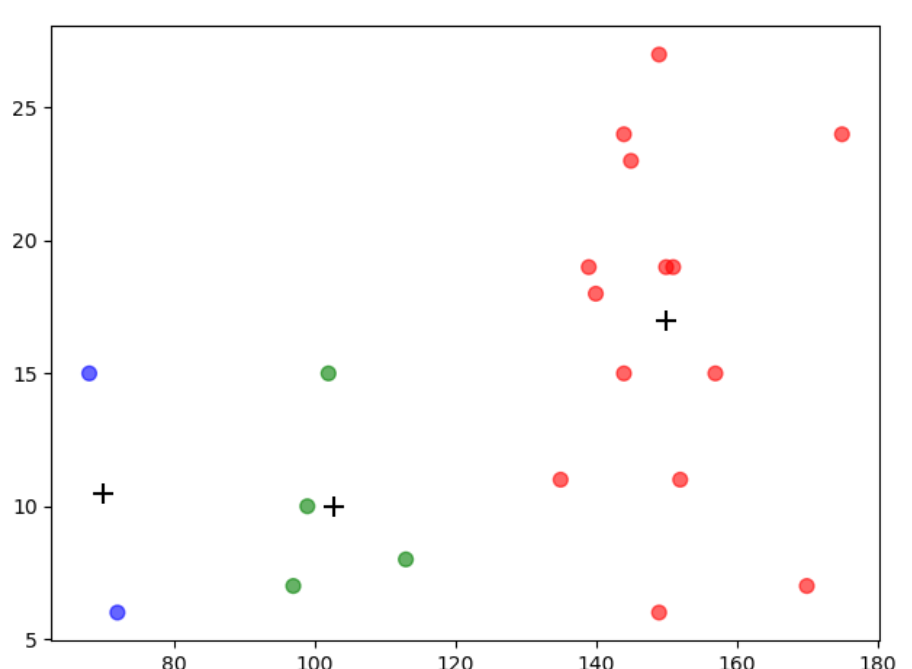
beer = beer.sort_values(by=['cluster3']) # 4. 使用groupby 计算出每一个聚类中心的质心点, 画散点图
centers = beer.groupby(by=['cluster3']).mean()
colors = np.array(['red', 'green', 'blue', 'yellow'])
plt.scatter(beer['calories'], beer['sodium'], c=colors[beer['cluster3']], s=50, alpha=0.6)
# 画出质心的位置
plt.scatter(centers.calories, centers.sodium, c='k', marker='+', s=100)
plt.show()
 、
、
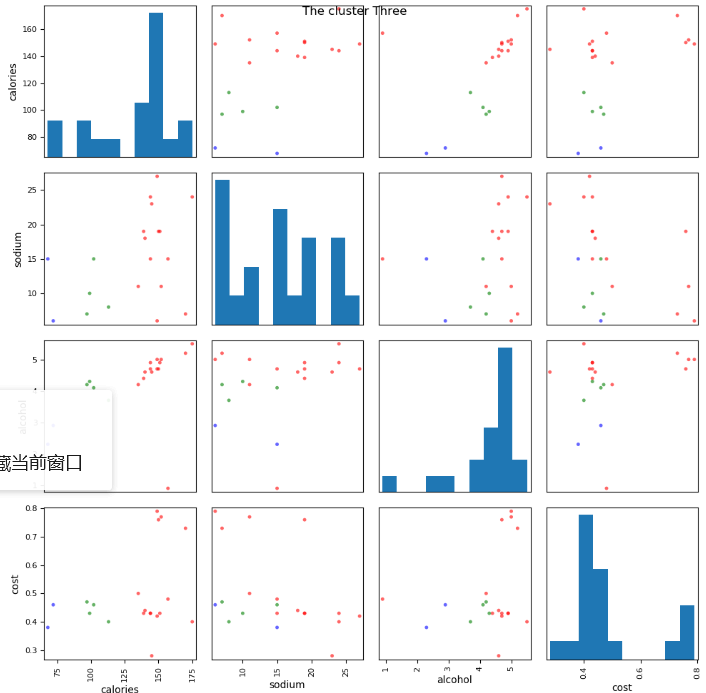
# 5. 使用scatter_matrix画出两两变量的关系图
from pandas.tools.plotting import scatter_matrix scatter_matrix(beer[['calories', 'sodium', 'alcohol', 'cost']], s=50, alpha=0.6, c=colors[beer['cluster3']], figsize=(10, 10))
plt.suptitle('The cluster Three')
plt.show()
# 6.silhouette_score引入轮廓系数作为评估的标准
import sklearn # k_cluster 从2-19,判断聚类的效果
scores = []
for i in range(2, 20):
labels = KMeans(n_clusters=i).fit(X).labels_
score = sklearn.metrics.silhouette_score(X, labels)
scores.append(score)
print(score) plt.plot(list(range(2, 20)), scores)
plt.xlabel('The cluster k')
plt.ylabel('Silhoette_score')
plt.show()
机器学习入门-K-means算法的更多相关文章
- 机器学习入门:K-近邻算法
机器学习入门:K-近邻算法 先来一个简单的例子,我们如何来区分动作类电影与爱情类电影呢?动作片中存在很多的打斗镜头,爱情片中可能更多的是亲吻镜头,所以我们姑且通过这两种镜头的数量来预测这部电影的主题. ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- 【机器学习】K均值算法(II)
k聚类算法中如何选择初始化聚类中心所在的位置. 在选择聚类中心时候,如果选择初始化位置不合适,可能不能得出我们想要的局部最优解. 而是会出现一下情况: 为了解决这个问题,我们通常的做法是: 我们选取K ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- [机器学习实战] k邻近算法
1. k邻近算法原理: 存在一个样本数据集,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 机器学习入门KNN近邻算法(一)
1 机器学习处理流程: 2 机器学习分类: 有监督学习 主要用于决策支持,它利用有标识的历史数据进行训练,以实现对新数据的表示的预测 1 分类 分类计数预测的数据对象是离散的.如短信是否为垃圾短信,用 ...
- 机器学习之K近邻算法
K 近邻 (K-nearest neighbor, KNN) 算法直接作用于带标记的样本,属于有监督的算法.它的核心思想基本上就是 近朱者赤,近墨者黑. 它与其他分类算法最大的不同是,它是一种&quo ...
随机推荐
- day41 python【事物 】【数据库锁】
MySQL[五] [事物 ][数据库锁] 1.数据库事物 1. 什么是事务 事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消.也就是事务具有原子性 ...
- oracle 与sql serve 获取随机行数的数据
Oracle 随机获取N条数据 当我们获取数据时,可能会有这样的需求,即每次从表中获取数据时,是随机获取一定的记录,而不是每次都获取一样的数据,这时我们可以采取Oracle内部一些函数,来达到这 ...
- linux下 mysql主从备份
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/czh0423/article/details/26720539 一.准备 用两台server做測试: ...
- 【转】每天一个linux命令(16):which命令
原文网址:http://www.cnblogs.com/peida/archive/2012/11/08/2759805.html 我们经常在linux要查找某个文件,但不知道放在哪里了,可以使用下面 ...
- Anaconda 使用(解决python包管理与环境管理)
Anaconda完全入门指南(对python环境和原理,讲的比较透彻):https://www.jianshu.com/p/eaee1fadc1e9 用pip一个一个安装第三方库费时费力,还需要考虑兼 ...
- C#设计模式之:抽象工厂模式与反射
抽象工厂模式[实例]:定义一个用于创建对象的接口,让子类决定实例化哪一个类 UML 代码class User{ private int _id; public int Id { get = ...
- json_encode 中文 null
今天使用json_encode 结果中文变成了null 原来是编码的问题. 将编码由 GBK 转成utf-8的就可以了 iconv('gb2312','utf-8', '中文');
- Android之WebViewClient与WebChromeClient的区别
Android之WebViewClient与WebChromeClient的区别 2012-05-05 0个评论 收藏 我要投稿 ANDROID应用开发的时候可能会用到WE ...
- bzoj4419 发微博
Description 刚开通的SH微博共有n个用户(1..n标号),在短短一个月的时间内,用户们活动频繁,共有m条按时间顺序的记录: ! x 表示用户x发了一条微博: + x y 表示用户x和用 ...
- jQuery解决IE6、7、8不能使用 JSON.stringify 函数的问题
https://github.com/douglascrockford/JSON-js使用其中的 json2.js 作为兼容.这个JS中的函数将JSON对象转换成JSON字符串,解决 IE6.7.8. ...